

논문정보
Deep Long-Tailed Learning : A Survey
논문정리
Abstract
그냥 long tailed data에 대한 설명과 어떤 문제가 있는지, 그리고 알고리즘들을 어떤 부류로 나눴는지에 대한 얘기다.
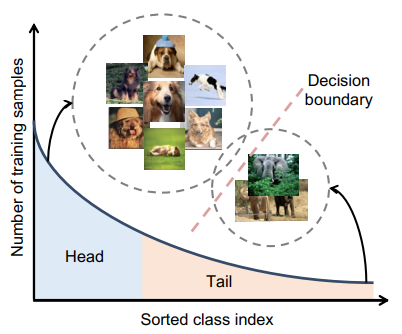
long-tailed 이란?
소수의 클래스가 데이터의 대부분을 차지하고 나머지 클래스는 데이터가 부족한 경우
데이터에 이렇게 불균형이 생기면 샘플수가 많은 쪽으로 편향이 생기고 적은 쪽에 대한 성능이 현저히 떨어지게 된다.
이를 처리하기 위해 여러 연구가 진행되었는데 본 논문에선 이를 세 그룹으로 나누었음
- class re-balancing
- information augmentation
- module improvement
또한, 새로운 평가척도인 relative accuracy를 제안하여 위 알고리즘들을 분석하였다.
Introduction
일반적으로 훈련 샘플은 long-tailed 분포를 갖는다.
즉, 몇 안되는 클래스가 샘플 양의 대부분을 차지하고, 나머지는 적은 상태.
이렇게 되면 인식 모델에 대한 심층 네트워크 훈련이 굉장히 어려워진다.
Fig 1에서 보다 싶이, 데이터 수가 많은 head class에 편향이 생기고 데이터가 제한 된 tail class에 성능이 떨어지게 됨
이를 해결하기 위해 다양한 연구가 진행되었는데 이 진행사항들을 리뷰하고 분석해본 논문이 없어 작성하게 됨.
2021년 중반까지의 연구들에 대한 survey를 제공.

위 Fig 2처럼 현재 사용하는 method들을 크게 3가지 카테고리로 나누었다.
각 카테고리는 여러 하위 카테고리로 2차 분류를 하였다.
위 분류를 따라 각 method에 대한 리뷰를 제공하고, 본 연구진이 제안한 'relative accuracy' 척도를 이용하여 SOTA method를 분석할 것이다.
Survey 부분에 대한 목차는 다음과 같다.
Section 2. 문제 정의와 현재 널리 쓰이는 데이터셋에 대한 설명
Section 3. long-tailed 학습 방법에 대한 리뷰
Section 4. 여러 SOTA 방법들에 대한 분석
Section 5. application scenarios
Section 6. 향후 연구 방향 파악
Section 7. Survey 마무리
나는 Section 1~4까지만 볼거임!
Problem Definition And Basic Concepts
<Problem Definition>
long-tailed 훈련 셋을 $\{x_i, y_i\}^n_{i=1}$와 같이 표기한다.
각 샘플 $x_i$에 클래스 라벨 $y_i$가 대응한다.
K개 클래스에 대한 총 샘플 수는 $n=\sum^K_{k=1} n_k$ (이때, $n_k$는 클래스 k의 샘플 수)
$\pi$는 label frequency를 나타내며, $\pi_k=n_k/n$는 클래스 k의 label frequency이다.
클래스는 cardinality에 대해 내림차순으로 정렬되어 있다고 가정한다.
if $i_1<i_2$, then $n_{i_1}\geq n_{i_2}$, and $n_1>>n_K)$
불균형 비율(imbalance ratio)는 $n_1/n_K$로 나타낼 수 있다.
가장 많은 샘플 수와 가장 적은 샘플 수의 비율
이 task가 까다로운 이유는 다음과 같다
- 클래스 수가 불균형하면 심층 모델이 head class에 편향되고 tail class에 대한 성능이 바닥난다.
- tail-class의 샘플 수가 부족하기 때문에 tail-class에 대한 분류 훈련이 힘들어짐
<Datasets>

long-tailed 학습을 위해 데이터셋이 나왔다.
위 Table 1은 현재 많이 사용되는 9개 데이터셋을 정리한 표
나는 분류를 하니까 분류쪽만 볼거임 ㅎㅎ
long-tailed 이미지 분류 분야에서는 4개의 benchmark dataset이 있다.
ImageNet LT, CIFAR 100-LT, Places-LT, iNaturalist 2018
앞 3개는 각각 ImageNet ,CIFAR100, Places365에서 샘플링한거고, iNaturalist는 real-world long-tailed dataset
불균형 비율(imbalance ratio)은 각각 ImageNet-LT : 256, Places365 : 996, iNaturalist : 500이며
CIFAR100-LT는 {10,50,100}의 3가지가 있다.
<Evaluation Metrics>
사용되는 평가척도는 task에 따라 다른데, top-1 accuracy (또는 error rate)가 이미지 분류작업에서 주로 쓰이는 편.
mean Average Precision(mAP)는 객체탐지나 분할 작업에서 쓰이며 multi-label 이미지 분류에서도 쓰이긴 함
영상(video)인식에서는 top-1 accuracy와 mAP를 동시에 사용한다.
<Mainstream Network Backbones>
여기서도 분류만 볼거임
long-tailed 학습 method는 network backbone이 되는 모델들을 기반으로 개발되었다.
데이터셋에 따라 다른데, ImageNet-LT에 대해서는 ResNet과 ResNeXt가 사용되었고
CIFAR100-LT에는 ResNet-32, iNaturalist2018엔 ResNet-50.
ResNet-152를 ImageNet으로 사전훈련하고 Places-LT에 사용되기도 하였다.
<Long-tailed Learning Challenges>
long-tailed 데이터셋에 대한 학습 대회 언급
<Relationships with Other Tasks>
long-tailed learning과 class-imbalanced learning, few-shot learning, out-of-domain generalization의 차이점을 알아본다.
Class-imbalanced learning
class-imbalanced 샘플을 가지고 모델을 훈련한다
long-tailed 학습이 class-imbalanced 학습의 특수 케이스라고 볼 수 있다.
비교를 해보자면 class-imbalanced학습은, 클래스의 수는 굉장히 적을 수 있고, 소수 데이터 수가 적어야 되는 건 아님
long-tailed 학습은 head class의 샘플 수는 굉장히 많은데, tail class의 샘플 수는 매우 부족한 경우임
무슨 말인가 싶은데 이런 거 같음
class-imbalanced는 데이터가 100000장 : 10000장으로 둘다 충분히 많은데 불균형이 있는 것도 포함이면
long-tailed는 10000장: 10장, 100000장 : 100장 등 하나는 데이터 수가 (학습이 어려울 정도로) 적은 거
Few-shot learning
라벨링된 샘플 수가 제한적일 때 모델을 훈련하는 게 목표!
비교하자면 few-show learning은 long-tailed 학습의 하위태스크로 볼 수 있다.
Out-of-domain Generalization
훈련 분포와 테스트 분포가 다를 때!
long-tailed 학습이 out-of-domain generalization의 특수 케이스라고 볼 수 있다.
Classic Methods
알고리즘 분류를 한 번 더 정리해보자!
Class re-balancing
- re-sampling
- cost-sensitive learning (CSL)
- logit adjustment (LA)
Information augmentation
- transfer learning (TL)
- data augmentation (Aug)
Module improvement
- representation learning (RL)
- classifier design (CD)
- decoupled training (DT)
- ensemble learning (Ensemble)
<Class Re-balancing>
훈련 샘플 수의 균형을 맞춰주는 작업으로 주된 패러다임이다.
Re-sampling
지난 몇십년동안 가장 널리 사용되었던 방법이다.
그 중 가장 많이 사용된 것은 random over-sampling (ROS)와 random under-sampling (RUS)
ROS는 tail class의 샘플을 임의로 반복시키는 것이고 RUS는 head class의 샘플들을 임의로 폐기하는 것
그런데 클래스가 극단적으로 한쪽에 치우치게 되면 ROS가 tail class에 과적합되고 RUS는 head class에 대한 성능을 떨어트림
Class-balanced re-sampling
샘플링 전략에는 instance-balanced sampling, class-balanced sampling, square-root sampling, progressively-balanced sampling이 있다.
instance-balanced sampling 각 샘플이 샘플링 될 확률이 동일
class-balanced sampling 각 클래스가 선택될 될 확률이 동일
square-root sampling instance-balanced sampling의 변형으로 각 클래스에 대한 샘플링 확률이 샘플 크기의 square root와 관련있다.
progressively-balanced sampling instance-balanced와 class-balanced를 보간한 것
Simple Calibration (SimCal) 생략 (segmentation임)
Dynamic curriculum learning (DCL) 훈련이 진행되는 동안 한 클래스의 인스턴스가 더 많이 샘플링 될수록 해당 클래스가 다음에 샘플링 될 확률이 낮아진다.
Balanced meta-softmax 최적의 샘플링 비율을 알아내기 위함. 최상의 sample distribution parameter를 학습
Feature augmentation and sampling adaptation (FASA) model classification loss를 balanced meta 검증셋에 사용하여 feature 샘플링 비율을 찾아내고, tail class가 더 샘플링 될수 있도록 함
Long-tailed object detectyor with classification equilibrium (LOCE) mean classification prediction score를 사용하여 모델이 다양한 클래스에 대해 훈련하는 것을 모니터링하고, tail class에 대한 성능을 향상시키기 위해 memory-augmented feature sampling을 가이드함
VideoLT 생략 (video 인식임)
Scheme-oriented re-sampling
metric 학습이나 앙상블 학습 등 long-tailed 학습을 위한 학습 체계
Metric Learning은 input data 간 거리를 학습하는 것을 의미한다.
input data 가 존재하고, 이 둘 간의 거리/유사도를 알고 있다면, 이를 맞추어나가는 과정을 통해, input data를 잘 설명하는 임베딩을 학습하는 것이다.
즉, 데이터 간의 유사도를 잘 수치화하는 거리 함수(metric function)를 학습
Large marginal local embedding (LMLE) inter-cluster와 inter-class 거리를 모두 유지하기 위한 high quality 특징들을 학습하는 quintuplet sampling scheme
Learning Deep Representation for Imbalanced Classification: CVPR 2016
Paper openaccess.thecvf.com/content_cvpr_2016/papers/Huang_Learning_Deep_Representation_CVPR_2016_paper.pdf Method imbalanced problem의 근본적인 문제점은 minority class를 학습하기 위한 sample이 부..
badlec.tistory.com
위 사이트 참조
Triplet loss는 단순히 같은 class끼리는 당기고 다른 class는 떨어트리는 방식을 사용한다.
그러나 quintuplet은 class간과 class 내부의 instance level까지 같이 고려하기 때문에 더 rich한 feature를 추출할 수 있다는 장점이 있다.
이렇게 학습된 특징들은 클래스 내부의 locality도 보존하면서 클래스 간 차이도 파악하게 된다. 또, 각 데이터 배치에는 같은 수의 샘플들을 갖게 됨
Partitioning resorvoir sampling (PRS) replay-based 샘플링 방법을 제안하여 long-tailed 학습을 다룬다.
여기서의 주요 문제는 리플레이 메모리가 클래스 불균형을 고려할 수 없다는 것.
미래에 들어올 입력에 대한 정보가 없기 때문
이를 해결하기 위해 각각 클래스의 샘플의 실행 통계를 유지하는 online memory maintenance 알고리즘을 개발
[꼼꼼한 논문 설명] Imbalanced Continual Learning with Partitioning Reservoir Sampling (ECCV 2020) - YouTube
위 유튜브 참조
음~근데 multi-label이네 안봐도 될듯
Bilateral-branch network (BBN) 네트워크 브랜치를 두개 개발하여 클래스 불균형을 다루었다.
conventional learning branch and re-balancing branch
conventional learning에는 균일하게 샘플링을 적용하여 기존의 long-tailed 훈련분포를 시뮬레이션 하고, re-balancing branch에는 역 샘플러를 적용하여 tail-class의 샘플을 더 많이 샘플링 할 수 있도록한다.
최종 예측은 두 네트워크 브랜치의 가중치를 더하여 수행
Multi-label visual recognition(LTML) 스킵 (BBN을 multi-label로 확장)
Geometric structure transfer(GIST) bilateral sampling 전략을 활용하여 head에서 tail 클래스로 지식 전달
이 외에도
Balanced group softmax(BAGs) 클래스를 각 클래스의 샘플 수에 기준으로 클래스들을 여러 균형 그룹으로 나누었다. 여기서 각 그룹은 비슷한 수의 샘플 수를 갖는 클래스로 구성된다.
그래서 이 각기 다른 샘플 그룹들로 각기 다른 classification head를 훈련하고 소프트맥스 연산을 수행하여 편향된 분류기가 되지 않도록 한다.
Learning to segment the tail 스킵
Ally complementary experts(ACE) 여러 균형 그룹으로 나누는 대신, 여러 skill-diverse 하위 집합으로 나누는데, 한 집합은 모든 클래스를 포함하고, 하나는 middle, tail 클래스만 포함하고, 다른 하나는 tail 클래스만 포함하는 식임
이런 하위집합들을 기반으로 앙상블 학습을 위한 기술을 갖도록 훈련시킨다.
Cost-sensitive Learning
앞에서는 데이터 수를 조절했다면 여기서는 손실 값을 조정하여 클래스의 균형을 맞춘다.
Class-level re-weighting

가장 직관적인 방법은 훈련 샘플의 label frequency를 이용하여 손실값을 재조정하는 것으로 이를 weighted softmax loss라 한다.
이런 손실은 loss weight에 대한 label frequency의 영향을 조정하여 개선 시킬 수 있다.
로스값을 재조정하는 것 외에도 balanced softmax는 label frequency를 사용하여 모델 예측을 조정하는데, 사전 지식에 의해 클래스 불균형으로 인한 편차가 줄어들게 된다.
LADE 학습된 모델을 long-tailed 훈련 분포로부터 분리하기 위해 label distribution disentangleling loss를 도입하였다. test label frequency를 사용할 수 있으면 테스트 클래스 분포에 대해 모델을 적응시킴
Class-balanced loss (CB) label frequency 대신, effective number라는 새로운 개념을 도입하여 서로 다른 클래스의 예상 표본 수를 근사시킴
이때, effective number는 훈련 샘플 수에 대한 지수함수로 표현된다.
CB loss는 effective number에 역비례한 class-balanced re-weighting항을 추가하여 불균형을 조절하였다.
Focal loss 가중치조정을 위해 class prediction hardness 를 탐색함. 클래스 불균형은 tail class의 예측 난이도를 증가시킨다는 것에 영향을 받았다. 따라서 focal loss는 예측 확률을 이용하여 클래스의 역으로 가중치를 재조정함. 따라서 tail class에는 높은 가중치를 할당하고, head class에는 낮은 가중치를 할당.
미리 정의된 가중치 함수를 사용하는 것 외에도 클래스 가중치가 데이터로부터 학습될 수 있다.
Meta-Weight-Net 가중치 함수는 one-layer MLP에 의해 근사되고 long-tailed 분포에 적합하도록 업데이트 된다. 따라서 균일한 테스트셋에 대해 잘 수행하도록 모델을 학습시킬 수 있다.
Distribution Alignment (DisAlign) 분류기를 조정하기 위한 adaptive calibration function을 개발하였음. 이 함수는 예측분포와 주어진 균형 reference 분포가 있으면 이들 사이의 kl-divergence값을 최소화하는 방향으로 학습한다.
KL Divergence는 데이터를 표현한 확률 모델이 정보 손실이 얼마나 있었는지를 측정하는 메트릭이다
KL Divergence(Kullback Leibler Divergence) 설명 (tistory.com)
KL Divergence(Kullback Leibler Divergence) 설명
출처) https://www.countbayesie.com/blog/2017/5/9/kullback-leibler-divergence-explained Kullback-Leibler Divergence Explained — Count Bayesie Kullback–Leibler divergence is a very useful way to mea..
dhpark1212.tistory.com
위 링크 참조
long-tailed에 대한 다른 문제는 음의 기울기 over-suppression (이게멀까?)
즉, softmax나 sigmoid cross-entropy에서 한 클래스의 positive sample이 다른 클래스에서의 negative sample로 보여질 수 있다는 것이다. 이렇게 되면 tail class는 suppressed gradient를 갖게 된다.
이를 해결하기 위해, distrubition-balanced loss로 negative tolerant 정규화를 통해 기울기 과잉억제를 완화한다.
또한, 각 클래스의 예상 샘플링 빈도와 실제 샘플링 빈도 차이를 계산한 다음, 이 빈도를 나누어서 손실값을 재조정한다.
Equalization loss 직접적으로 tail class 샘플이 head class 샘플에 대한 negative pair로 사용될 때 tail class에 대한 손실값을 하향 조정한다.
positive pair은 거리가 가까워지도록, negative pair은 거리가 멀어지도록 학습
Equalization loss v2 위 손실을 확장. 스킵. (detection)
Seesaw loss 각 클래스에 대한 양과 음의 기울기를 두개의 재조정 인자를 통해 균형을 맞춘다.
mitigation factor and copensation factor
그레디언트가 과억제되는 것을 해결하기 위해 mitigation 인자는 서로 다른 클래스간 누적 샘플 수의 비율을 기반으로 tail class에 대한 패널티를 완화한다. 한편, false negative 샘플이 발견될 경우, compensation인자가 해당 클래스에 패널티를 가중시킨다.
Adaptive class suppression loss (ACSL) output confidence를 사용하여 negative label에 대해 그레디언트를 억제할 지 여부를 결정한다. negative label에 대한 예측 확률이 미리 지정된 임계값보다 높을 경우 이 클래스에 대한 가중치가 1로 설정되도록 한다. 반대의 경우, 0으로 set해서 negative over-suppression을 피한다.
Class-level re-margining
서로 다른 클래스에 대해 학습된 특징들과 모델 분류기 사이의 최소 margin을 조정하여 클래스 불균형 처리
Label-distribution-aware margin (LDAM) label frequency를 기반으로 tail class가 더 큰 margin을 갖게 하면서 기존의 soft margin loss를 확장하였다. 단순히 LDAM loss를 사용하는 것은 클래스 불균형을 처리하는데 충분하지 않다. 따라서, 일정 기간동안 LDAM loss로 학습 한 후에 LDAM loss를 재조정하여 클래스 균형을 맞추는 re-balancing 최적화 스케쥴을 추가로 도입하였다.
Bayesian estimate 클래스 예측 불확실성이 training label frequency에 역비례함을 발견함
tail class가 더 불확실하다.
따라서 class-level 불확실성으로 손실을 re-margin한다. 따라서, 불확실성이 높은 tail-class가 더 큰 손실 값을 겪고, 분류기와의 margin이 더 클 수 있도록 한다.
Domain balancing 적은 수의 도메인(여러 클래스 포함)이 자주 나타나고 다른 도메인은 적게 존재하는 long-tailed 도메인 문제를 연구하였다. 이 문제를 해결하기 위해 클래스 간 compactness를 기반으로 새로운 domain frequency indicator를 도입하였다. 이 indicator를 사용하여 tail-domain의 특징공간을 re-margin한다.
LOCE 평균 분류 예측 점수(mean classification prediction score)를 사용하여 학습 상태를 모니터링 하고 tail-class의 성능을 높이기 위해 class-level margin 조정.
Progressive margin loss (PML) 2개의 margin 항을 사용해서 class-wise margin 조정
ordinal margin and variational margin
ordinal margin은 분류특징들을 추출하고 나이 순서 관계를 유지하려고 한다.
varidational margin은 long-tailed 훈련 샘플의 클래스 불균형을 처리하기 위해 head class를 차차 억제한다.
RoBal margin tail class에 대한 margin을 넓히는 방법으로 margin을 조정하는 것은 head class의 성능을 저하시킬 수 있다고 주장. 그래서 추가로 margin term을 도입하여 head class에 대한 feature margin도 키울 수 있도록 하였다.
Logit Adjustment
logit을 조정하는 것은 클래스 불균형 문제에서 상대적으로 큰 margin을 얻기 위한 고전적인 아이디어
logit이란 최종 레이어가 내놓는 결과값 (확률화되지 않은 예측 결과)
$[-\infty,\infty]$의 값이 나올 수 있고 양수인지 음수인지에 따라서 어느 class인지 구분
다중 분류에서는 이를 softmax의 입력으로 넣으면 신경망의 결과를 확률로 바꿔준다.
최근 한 연구는 logit을 조정하는 것이 클래스별 평균 오차를 최소화한다는 것을 이론적으로 보여주었음
이 아이디어를 이어서 RoBal이 훈련 label frequency를 기반으로 코사인 분류 경계를 적용하기 위해 사후 처리 전략을 적용하였음
LADE 훈련 데이터의 label frequency 대신 테스트 데이터의 label frequency로 모델 출력을 후처리하여 훈련된 모델이 테스트 클래스 분포에 보정될 수 있도록하였음
UNO-IC balanced meta validation set으로 조정된 하이퍼파라미터를 사용하여 클래스 불균형을 해결하기 위해 모델 분류기를 보정하였다.
De-confound 훈련 중에 특징의 exponential 이동 평균을 계산하여 편향 정보를 기록하는 causal classifier을 소개하였다. 그 후 추론 시에 편향 정보를 빼서 나쁜 인과관계를 제거
DisAlign 보정함수를 적용했는데 이는 보정된 예측 분포와 상대적으로 균형잡힌 클래스 분포를 일치시키면서 학습
Discussions
class-rebalancing은 상대적으로 단순하지만 괜찮은 성능을 보여준다. 하지만 대부분의 re-balancing 방법들은 tail-class 성느을 높이지만 head-class에 대한 성능은 떨어짐 (시소같은 느낌)
게다가 전체적인 성능은 오를지 몰라도 여전히 정보가 부족하다는 문제는 해결하지 못하고 있다.
<Information Augmentation>
모델에 추가적인 정보를 주어서 long-tailed 학습 시 성능을 향상
전이 학습과 데이터 증강이 있다.
Transfer Learning
source 도메인(e.g. 데이터셋, task, 클래스...)으로부터 정보를 전이하여 타겟 도메인에 대한 모델 훈련을 강화한다.
Head-to-tail knowledge transfer
head class의 정보를 전이하여 tail class에 대한 모델 성능을 증대한다.
Feature transfer learning (FTL) tail-class 샘플들의 클래스 내부의 variance가 더 작아 특징공간과 결정경계가 편향되었다.
이를 해결하기 위해 head class의 클래스 내부의 분산을 활용하여 tail-class에 대한 성능을 높여 tail-class 특징들이 더 높은 클래스 내부 분산을 가지도록 한다.
LEAP 각 클래스 별로 "feature cloud"를 구성하여 tail-class feature cloud의 클래스 내부 분산을 키우기 위해 head-class의 feature cloud 정보를 전이한다.
이를 위해 tail-class 샘플을 특정 분포에 맞게 증강
Online feature augmentation (OFA) 클래스 활성맵을 사용하여 샘플 특징을 class specific / class agnostic으로 분리함
tail-class 샘플의 class-specific 특징과 head-class샘플의 class-agnostic 특징을 결합하여 tail-class를 증강한다.
그 후, 증강되었거나 기존의 특징들은 모델 분류기를 파인튜닝하는데 사용
Rare-class sample generator (RSG) tail class의 특징 공간이 head-class에서보다 훨씬 작다는 걸 발견함
따라서 tail class의 특징 공간을 확장하기 위해 새로운 샘플들을 만들어내고 결정경계를 밀어낸다.
각 클래스 별로 feature center을 추정한 후, head-class의 샘플 특징과 이와 가까운 intra-class feature center간 feature displacement를 사용하여 tail sample의 특징을 보강한다.
Major-to-minor translation (M2m) 여태껏 특징수준에서 head-to-tail전이였다면 이번엔 major-to-minor임
perturbation기반의 최적화를 통해 head class 샘플을 tail class로 변환하여 tail class를 보강함
변환된 tail class 샘플은 모델 훈련 시 훈련셋의 균형을 맞추는데 쓰임.
GIST 분류기 단에서 head-to-tail 전이를 수행함 tail class에 대한 분류기 가중치를 강화하고 성능을 높임
MetaModelNet few-shot 모델 매개변수를 many-shot 모델 매개변수에 매핑하는 메타 네트워크 학습 제안
few-shot 모델은 적은 샘플로 훈련되었고, many-shot 모델은 방대한 샘플로 훈련 됨
메타 네트워크는 head class로 훈련되는데, 여기서 many-shot 모델은 head class 훈련셋에서 직접 훈련되는데 few shot 모델은 이 클래스들의 하위 집합에 대해 훈련
head class에 대해 훈련된 메타 네트워크는 tail class에 대해 훈련된 few show 모델에 적용되어 tail class에 대한 성능을 높인다.
Model pre-training
심층 모델 훈련시 많이 쓰이는 방식임
Domain-specific transfer learning (DSTL) 처음엔 long-tailed 샘플들로 모델을 훈련한 후 클래스 균형이 맞는 하위집합으로 모델을 파인튜닝함
이렇게하면, tail-class쪽으로 천천히 특징들을 전이시키게 됨
Self-supervised pre-training (SSP) 처음에는 자기지도학습을 사용해서 모델을 사전훈련 한 후, long-tailed 데이터셋에 대해 standard 훈련.
tail class에 대해 성능 향상을 보였음
Knowledge distillation
기계 학습에서 지식 증류는 큰 모델에서 작은 모델로 지식을 전달하는 과정
Transfer learning은 서로 다른 도메인에서 지식을 전달
Knowledge distillation은 같은 도메인 내 모델A에게 모델B가 지식을 전달
잘 훈련된 teacher model의 output을 기반으로 student model을 훈련
LST 스킵 (semgentation)
Learning from multiple experts (LFME) long-tailed 데이터셋을 여러 하위집합으로 나눈다
클래스 불균형 정도가 작게 있음
그리고 각기 다른 하위집합들을 이용해서 여러 experts 모델을 훈련시킴
expert에 기반하여 easy-to-hard instance 선택 방식으로 student모델을 훈련
Routing diverse distribution aware experts (RIDE) multi-expert 모델의 파라미터를 줄이는 지식증류 방법을 소개한다.
적은 expert로 student 네트워크를 학습.
Self-supervision to distillation (SSD) 새로운 자기증류 방식을 개발.
먼저 분리된 (decoupled) 훈련 체계를 통해 지도 및 자기지도 정보를 기반으로 보정된 모델을 훈련한 다음 이 모델을 사용하여 모든 샘플에 대한 soft label을 생성
생성된 soft label과 기존의 long-tailed hard label을 동시에 이용해서 studnet 모델 증류
이후, 분류기 미세조정 단계 시작
Distill the virtual examples (DiVE) 균형된 클래스 모델을 teacher모델로 사용하는 것의 효율성을 보여줌
Self-training
소량의 라벨링된 샘플과 다량의 라벨링되지 않은 샘플들로부터 성능좋은 모델을 만들기 위함
처음에는 라벨링된 데이터를 가지고 지도학습 후, 라벨링되지 않은 데이터의 pesudo label을 만듦
라벨링된 데이터와 psudo labeled 데이터를 가지고 모델을 재훈련함
그러면 self-training을 하면서 다량의 라벨이 없는 데이터에서부터 지식을 추출하여 long-tailed학습 성능을 높임
하지만, 이런 패러다임은 long-tailed 문제를 직접적으로 다루는데 사용할 수 없다.
왜냐면 애초에 labeld, unlabeld 데이터셋이 long-tailed 분포를 따를 거기 때문
지금까지 long-tailed semi-supervision learning을 해결하기 위해 self-training을 향상하는 방법은 아직 탐구되지 않았다.
알고리즘 skip
self training 안할거니까
Data Augmentation
모델 훈련 시 데이터셋의 양과 질을 향상시키기 위한 증강 기술
long-tailed에는 두가지 유형의 증강기법이 있다.
transfer-based augmentation and conventional(non-transfer) augmentation
non-transfer 증강은 long-tailed 문제를 해결하기 위해 기존의 데이터 증강기법을 개선하거나 설계함
MiSLAS long-tailed 학습에서 데이터 혼합(mix up)을 조사하였고 아래와 같은 점을 발견
(1) 데이터 혼합이 모델의 과잉확신 (over confidence)를 해결하는데 도움을 준다.
over confidence
틀린 답에 대해 과도한 확신을 가짐
실제 정확도보다 높은 확률로 물체를 예측
(2) 혼합은 표현학습에서는 긍정적인 영향을 미치지만, 분류 학습에는 부정적이거나 영향이 없음
따라서 decoupled scheme에서 표현학습을 강화하기 위해 데이터 혼합을 사용
Remix 데이터 혼합을 사용하였고 re-balanced 혼합방법을 소개하였다.
FASA 이전에 관측한 샘플에서 추정된 평균과 분산을 통한 가우시안을 기반으로 class-wise 특징을 생성한다.
balanced 검증셋을 통한 모델 분류손실을 활용하여 각기 다른 클래스에 대한 특징 샘플링 비율을 조정한다
따라서, 표현력이 떨어지는 tail class가 더 증강될수 있도록 한다.
Meta semantic augmentation (MetaSAug) IDSA의 varient으로 tail class를 증강하는 것을 제안함
IDSA는 클래스 조건부 확률을 추정하여 semantic direction을 얻고,이를 활용해 샘플의 특징을 변환하여 다양한 증강 샘플을 생성한다. tail-class 샘플이 충분하지 않으면 이에 대한 공분산 행렬을 추정하는 것이 효과적이지 않다
따라서, MetaSAug는 CB loss를 활용하여 각 클래스에 대한 공분산 행렬을 학습하는 meta-learning을 가이드함
이 방식으로, tail class에 대한 공분산 행렬이 더 정확하게 추정될 수 있었고 생성된 특징들이 더욱 유익해짐
Discussions
전이학습 기반의 방법은 head class 성능을 해치지 않으면서 tail class에 대한 성능을 높였다.
데이터 증강은 비교적 기본적인 기술이며 다양한 long-tailed문제에 사용할 수 있다.
하지만,클래스와 무관한 증강 기법을 사용하는 것은 X
head class가 더 많은 샘플을 가져갈 수 있기 때문에 불균형을 높일 수 있음
어떻게 long-tailed 학습에서 데이터 증강을 잘 활용할 수 있는지는 여전히 문제이다.
<Module Improvement>
Representation Learning
Metric learning
input data 간 거리를 학습하는 것을 의미
데이터간의 유사도를 수치화
객체간 유사성/비유사성에 대한 task specific 거리함수 (distance metric)를 설계하는 것이 목표
LMLE 클래스 간 /클래스 내의 간극(margin)을 유지하는 표현을 학습하는 quintuplet loss 도입
Range loss 하나의 미니배치 내에서 가능한 모든 샘플쌍들의 거리들을 사용하여 표현학습
즉, instance 수준이 아니라 전체 배치에 대한 통계값을 사용하므로 전체 클래스에 대한 데이터 수 불균형에 관한 편향을 완화한다
구체적으로는, 클래스 간의 거리는 키우면서 (미니배치 내의 두 클래스 간 센터 거리를 최대화시킴) 클래스 내 분산은 줄임 (클래스 내의 샘플들 사이의 최장 거리를 최소화시킴)
결론적으로 더 나은 구별 능력과 덜불균형화된 편향을 얻을 수 있다.
Class rectification loss (CRL) tail class 샘플 표현을 향상시켜서 클래스 내 compactness와 클래스 간 거리를 키울수 있도록 한다
intra-class compactness
동일한 레이블을 가진 feature가 서로 얼마나 가까운지를 나타냄
이를 위해, tail class에 대해 hard-pair triplets을 구성하고 CRL을 클래스 균형 제약으로써 적용시킴
학습된 모델이 클래스 불균형의 부정적 영향을 극복하게됨
최근 연구는 lon-taile 문제에 대조학습 (contrastive learning)도 탐구하였다.
Contrastive learning is an approach to formulate the task of finding similar and dissimilar things for an ML model
대상들의 차이를 더 명확하게 보여줄 수 있도록 학습
Contrastive learning이란? (Feat. Contrastive loss) :: Time Traveler (tistory.com)
KCL 균형된 특징 공간을 학습하기 위한 $k$-positive constrastive loss 제안하였고 이는 클래스 불균형을 완화하고 일반화 능력을 향상시킴
Hybrid prototypical 대조학습을 도입
Parametric contrastive learning (PaCo) 클래스 중심을 분류기 가중치로 간주하여 분류기와 동일한 역할을 하는 parametric 학습이 가능한 class center를 추가함으로써 지도 대조학습을 개선시킴
DRO-LT distribution robust 최적화로 prototypical 대조학습을 확장하여 학습된 모델이 데이터 분포 변화에 더 robust하게 함
Sequential training
Hierarchical feature learning (HFL) 각 클래스는 visual representation에서 각각의 개별성을 갖는다는 점에서 시작
따라서, 객체를 시각적으로 비슷한 클래스 그룹으로 계층적으로 클러스터리하여 계층적 클러스트 트리를 생성
클러스트 트리에서는, origihnal node의 모델이 ImageNet-1K로 사전학습 됨. 각각의 자식 노드는 부모 노드로부터 파라미터를 상속받고 클러스터 노드의 샘플을 기반으로 파인튜닝함
이런 방식으로, 다수의 클래스가 있는 그룹으로부터 차차 적은 수의 하위 그룹으로 지식 전달
Unequal-training 데이터셋을 head-class와 tail-class 하위집합으로 나눈 뒤 훈련할 때 다른 것으로 취급함
일단 head class로는 noise-resistant loss를 이용해서 discriminative하고 noise-resistant한 특징들을 훈련한다.
그 뒤, tail class로 새로운 center-dispersed loss를 이용해 클래스 내 구별을 향상시킴
center-dispersed loss는각 클래스의 정규화된 특징을 기반으로 한다.
Prototype learning
Open long-tailed recognition (OLTR) 테스트셋이 head, tail, open class를 포함하는 open world에서 long-tailed 인식을 처리하기 위해 feature prototype의 개념을 탐구함
여기서 open class란 훈련셋에는 없는 테스트 클래스를 지칭한다
이 task를 다루기 위해 , discriminative feature prototype을 포함하는 visual meta memory를 유지하고 visual 메모리에서 주입된 특징들로 기존의 특징을 보강한다
ㄹ학습된 특징공간은 더 구별적이게 되고, 새로운 클래스에서의 샘플 특징이 메모리보터 멀어지고 원점에 가까워짐
이러한 특징공간을 통해서 인접한 클래스를 구별하고, 새로운 클래스를 감지할 수 있다. 게다가 특징학습을 강화하기 위해서 self-attention 방법도 탐구하였다.
Inflated epiodic memory (IEM) 각 클래스가 독립적이고 차별화되는 메모리 블럭을 갖고, dynamical update ceheme를 통해 meta-embeddiing 메모리 혁신.
이때, 각 메모리 블럭은 해당 카테고리에 대해 가장 구별적인 특징 프로토타입을 기록한다
dynamic memorhy bank가 가장 구별적인 특징 프로토타입만 포함하고 있기 때문에 클래스 수 불균형 문제에 영향을 받지 않는다. 게다가, 이후에 표현학습을 더 강화하기 위해 셀프 어텐션 메커니즘도 탐구하였다.
Transfer learning
Unsupervised discovery (UD) 자기지도학습을 사용하여 새롭고 더 세밀한 객체를 찾는 것을 제안
처음에는 사전훈련된 class-agnostic 마스크 제안 네트워크를 사용하여 모든 가능한 객체에 대해 객체 바운딩 박스와 분할 마스크를 생성한다
class-agnostic
class-agnostic 탐지기는 객체가 어떠한 분류(class)에 속해 있는지에 대해 구분하지 않고 객체만을 검출하여 bounding box로 인식한다. 이러한 의미에서 class-agnostic은 "클래스를 구분하지않는" 으로 생각할 수 있겠다.
[용어정리] class-agnostic (tistory.com)
그 후, 3개의 새로운 자기지도 triplet loss를 사용하여 hyperbolic 특징 공간을 학습한다
마지막으로, 학습된 특징에 기반하여 비지도 클러스터링을 하고, eclusive하게 라벨을 할당하여 새롭고 세밀한 객체를 발견한다
Decoupling instance-balanced, class-balanced, square-root, progressively-balanced sampling의 다른 샘플링 전략을 통해서 long-tailed 표현학습을 혁신
MisLAS instance-balanced sampling을 이어서 데이터 혼합과 long-tailed 표현학습을 연구함
Classifier Design

표현학습 외에도, long-tailed 문제를 해결하기 위해 여러가지 유형의 분류기를 설계하였다.
일반적인 이미지 문제에서, 가장 흔한 딥러닝 관행은 선형 분류기를 이용하는 것이다
$p = \phi(w^Tf+b)$
이때, $\phi$는 softmax함수이며 편향 $b$는 무시해도 됨
하지만, long-tailed 클래스 불균형은 head class에 대해 분류기 가중치가 더 크기 때문에 선형분류기가 dominant class쪽으로 치우치게 됨
이를 해결하기 위해 크기에 무관한 코사인 분류기를 제안하고, 이때 분류기 가중치와 샘플 특징은 모두 정규화된다
$p=\phi((\frac{w^Tf}{||w||||f||})/\tau+b)$
여기서, temperature $\tau$는 잘 선택되어져야 하는데, 그러면 분류기 성능이 더 안 좋아짐
$\tau$-normalized classifier $\tau$-정규화 과정을 통해 클래스 가중치의 norm을 조정하면서 결정 경계 불균형 해결
$\tilde{w}=\frac{w}{||w||^\tau_2}$
$\tau$는 정규화를 위한 temperature factor
$\tau=1$이면 $L_2$정규화로 감소하고, $\tau=0$이면, 스케일링 하지 않음
하이퍼 파라미터 $\tau$는 class-balanced sampling으로도 훈련될 수 있다.
nearest class mean classifier는 $L_2$ normalized mean feature를 계산하고 코사인 유사도와 유클리드 거리를 사용하여 예측을 수행한다
Realistic taxonomic classifier (RTC) 이미지를 class taxonoic tree에 매핑함, 이때 계층은 분류노드와 노드관계를 기반으로 정의됨
다른 샘플들은 다른 계층레벨로 분류된다.
이런 구조에서는 리프노드보다는 중간노드에서 예측을 수행하는 것을 선호함
Casual classifier 인과에 의존함. 좋은 인과관계는 기울기를 안정화시키고 훈련을 가속화하지만, 나쁜 인과관계는 성능을 저하시키는 long-tailed 편향을 나타냄
편향 정보를 더 잘 근사하기 위해서, 멀티헤드 전략을 사용해서 모델 가중치와 데이터 특징의 채널(차원)을 K 그룹으로 동등하게 나눔
$p=\phi(\frac{\tau}{K} \sum^K_{k=1} \frac{(w^k)^T f^k}{(||w^k||+\gamma)||f^k||})$
이때 $\tau$는 temperature factor, $\gamma$는 하이퍼 파라미터
$\gamma=0$일때 분류기는 코사인 분류기와 동일하다
추론시 casual classifier는 입력이 null일때의 예측을 제외해서 나쁜 인과관계를 제거한다.
$p=\phi(\frac{\tau}{K} \sum^K_{k=1} \frac{(w^k)^T f^k}{(||w^k||+\gamma)||f^k||}-\alpha \frac{cos(x^k,\hat{d}^k)(w^k)^T\hat{d}^k}{||w^k||+\gamma})$
이때 $\hat{d}$는 exponential moving average feature의 단위 벡터
$\alpha$는 trade-off 파라미터 (직접/간접 효과를 조절)
그니까 분류기가 ,exponential moving average feature를 계산하면서 편향을 기록하면, 추론하는 동안 예측된 로짓에서 편향을 빼서 나쁜 인과관계를 제거함
GIST classifier head class의 기하학적 구조를 tail class로 전달함
class-specific weight center (클래스 위치 인코딩용)와 displacement 집합(클래스 지오메트리 인코딩용)으로 구성
head-class에서 상대적으로 큰 변위(displacement)를 이용할수록 성능이 좋아짐
Decoupled Training
학습절차를 표현학습과 분류기 훈련으로 분리함
첫번째 단계에서 표현학습을 위한 샘플링 전략들을 평가 후, 다음 단계에서 특징 추출기를 고정하여 분류기 훈련 방식 평가
알아둘 것은 다음과 같다
- intantce-balanced sampling이 표현학습에서는 가장 좋은 전략임
- 분류기를 조정하면 엄청난 성능 개선으로 이어짐
KCL 균형된 특징 공간이 long-tailed 학습에 효과적임을 알아냄
따라서, class-balanced & class-discriminative 특징 공간을 학습하기 위해 k-positive 대조 손실을 개발하여 decoupled 훈련 방식을 혁신함
MisLAS 데이터 혼합이 표현학습에는 좋지만 2단계 분리훈련 체제에선 분류기에게 안좋거나 거의 없는 영향을 미치는 것을 발견함
따라서, 첫 단계에서 데이터 혼합으로 표현학습을 향상시키기를 제안
두번째 단계에서는 레이블 인식 스무딩 전략을 사용하여 모델 일반화성능을 높였다.
최근 많은 연구가 분류기 훈련 단계를 향상시켜 decoupled 훈련 체제를 개선하였다.
OFA tail class에서 추출된 클래스 특화된 특징과 head class의 클래스 일반 특징을 결합하여 tail class의 특징을 보강하였다.
SimCal skip (segmentation)
DisAlign 새로운 adaptive calibration 전략으로 분류기 훈련을 개선함
즉, 보정된 예측 분포와 균형된 레퍼런스 분포 사이의 KL-divergence를 최소화하여 분류기의 출력 로짓을 조정함
DT2 skip
Ensemble Learning
Bilateral-branch network (BBN) 네트워크 브랜치를 두개 개발하여 클래스 불균형을 다루었다.
conventional learning branch and re-balancing branch
conventional learning에는 균일하게 샘플링을 적용하여 기존의 long-tailed 훈련분포를 시뮬레이션 하고, re-balancing branch에는 역 샘플러를 적용하여 tail-class의 샘플을 더 많이 샘플링 할 수 있도록한다.
최종 예측은 두 네트워크 브랜치의 가중치를 더하여 수행
LTML skip (multi-label)
SimCal skip (segmentation)
BAGS skip (detection)
Learning from multiple experts (LFME) long-tailed 데이터셋을 여러 하위집합으로 나눈다
클래스 불균형 정도가 작게 있음
그리고 각기 다른 하위집합들을 이용해서 여러 experts 모델을 훈련시킴
expert에 기반하여 easy-to-hard instance 선택 방식으로 student모델을 훈련
Ally complementary experts(ACE) 여러 균형 그룹으로 나누는 대신, 여러 skill-diverse 하위 집합으로 나누는데, 한 집합은 모든 클래스를 포함하고, 하나는 middle, tail 클래스만 포함하고, 다른 하나는 tail 클래스만 포함하는 식임
여러 expert들로 이 다양한 클래스 하위집합을 훈련시킴
다양한 하위집합이 서로 다른 샘플 수를 가지고 있다는 것을 고려하여, 다양하게 학습률을 조정한다.
RIDE 데이터를 나누지 않고, 모든 훈련 샘플에 대해 각 expert를 소프트맥스 손실로 독립적으로 훈련하고 expert들의 다양성을 높이기 위해 KL-divergence 기반 손실을 사용
각 소프트맥스 손실로 expert를 개별적으로 훈련하면 long-tailed learing에서 앙상블 성능이 많이 향상
Test-time aggregating diverse experts (TADE) 테스트 분포에 관계 없이 long-tailed 인식을 다루기 위해 multi-expert 방법을 사용했다.
테스트 클래스 분포가 균일하거나, long-tailed일 수 있다.
다양한 expert가 다양한 클래스 분포를 처리하도록 훈련하는 diversity-promoting epertise-guided loss를 도입
훈련된 expert는 더 다양해지고, 앙상블 성능을 높인다.
Discussions
Decoupled training은 최근 연구에서 관심을 많이 끌었다.
이 방법은, 두번째 스테이지 (class-balanced classifier learning)가 많은 연산량이 필요 없음에도 상당히 성능을 높였다.
앙상블기반 방법은, 다른 방법들과 비교해서 head와 taill 클래스들의 성능을 모두 높였다.
Empirical Studies
시작하기 전에, 새로운 평가 지표를 소개한다.
<Novel Evaluation Metric>
long-tailed 문제에서 성능을 높이기 위해 클래스 불균형을 해결하는 것이 목표
가장 흔히 사용되는 평가 프로토콜이 top-1 test accuracy
$A_t$로 표기
하지만 이 지표는 클래스 불균형을 처리할때는 부적절함
클래스 불균형 이외의 다른 요인에 의해 영향을 받기 때문
예를들어, 앙상블 학습이나 데이터증강에서 균형된 훈련셋을 사용하면서 모델의 성능을 높인다
이런 경우, 클래스 불균형의 완화로 성능이 높아진 것인지, 모델 구조가 좋아져서 높아진 것인지 알 수 없다.
클래스 불균형을 다뤘을때의 효율성을 평가하기 위해서 새로운 평가지표를 제안한다
이름하여 "relatively accuracy"
$A_r$
upper reference accuracy인 $A_u = max(A_v, A_b)$는 둘 사이에서 높은 정확도를 계산하는데
이때 $A_v$는 일반적인 정확도 (balanced training set with cross-entropy)
$A_b$는 균형된 정확도 (long-tailed method에 해당)
balanced training set은 long-tailed 훈련 셋의 변형으로 총 데이터 수는 적지만 각 클래스가 같은 데이터 수를 가지고 있다.
relative accuracy는 $A_r = \frac{A_t}{A_u}$
이 실험에서는 upper reference accuracy, relative accuracy 모두 사용됨
<Experimental Settings>
Datasets
ImageNet-LT 사용
1000개의 방대한 클래스가 있고 불균형 비율이 256
모든 클래스에 대한 성능 외에도, ImageNet-LT에 대한 3가지 하위 집합에 대한 성능도!
Head (100 이미지 이상)
Middle (20~100 이미지)
tail (20 이미지 이하)
Baseline
다음 기준에 따라 learning method를 선택함
- 공식 코드를 사용할 수 있거나 구현하기 쉬운 경우
- 논문에서 ImageNet-LT를 다룬 경우
베이스라인(softmax)을 포함하여 그 결과로, 20개 이상의 방법들이 있다.
baseline(Softmax),
cost_sensitive learning (Weighted Softmax, Focal loss, LDAM, ESQL, Balancfed Softmax, LADE)
logit adjustment(UNO-IC)
transfer learning(SSP)
data augmentation (RSG)
represnetation learning(OLTR, PaCo)
classifier design (De-confound)
decoupled training(Decoupling-IB-CRT)
ensemble learning (BBN, LFME, RIDE, ResLT, TADE)
Implementation details
파이토치로 구현
네트워크 백본으로 ResNeXt-50 사용
옵티마이저는 SGD
배치사이즈 256
모멘텀 0.9
weight decay factor 0.0005
학습률 0.1
알고리즘에 관련된 하이퍼파라미터는 기존 논문에서 참조하거나 성능이 안좋을 경우 임의로 조절함
증강은 똑같이 기본으로 적용 (크기 조절후 224로 crop, 좌우 전환, color jitter, 정규화)
위에서 언급된 증강 기법은 위의 기본 증강을 거친후 적용
<Results on all classes>

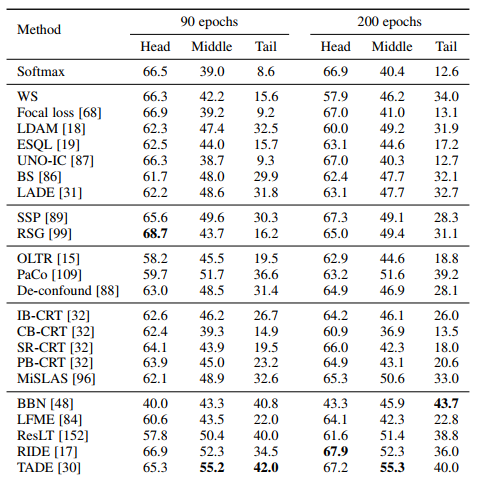

표 5와 그림4에서 모든 클래스에 대한 평균 성능을 보여준다
Observations on all methods
표 5를 보면, 정확도 측면에서는 거의 모든 long-tailed 방법들이 softmax 베이스라인 보다는 성능이 좋다
그럼에도, 소프트맥스보다 조금 성능이 떨어지는 방법이 두가지 있다.
Decouple-CB-CRT, BBNc
Decouple-CB-CRT에서 성능이 떨어진 이유는 decoupled training의 첫번째 단계에서 class-balanced sampling에 의한 표현학습이 떨어져서라고 추측
BBN (공식 코드사용)의 경우는 head class에서 점점 tail class로 학습 초점을 조정하는 culuative learning 전략에서 비롯된 것으로 추측
훈련이 끝났을 때 너무 많은 focus가 tail class에 주어짐
따라서, tail class 성능은 더 낫지만 head class의 정확도는 떨어지게 됨
정확도 외에도 upper reference accruacy(UA)와 relative accuracy(RA)를 보면 대부분의 방법들이 베이스라인과 똑같은 UA를 가지는데 몇 개의 방법에서는 더 높은 UA를 가지기도 함
SSP, MiSLAS, TADE
이 경우에는 클래스 완화에 의한 것뿐만이 아니라 데이터 증강이나 더 나은 네트워크 구조 등 다른 요인으로 인해서도 성능이 개선되었다.
정확도를 사용하는 것만으로는 불충분한 이유
제안된 RA 지표는 클래스 불균형을 제외한 요인의 영향을 완화한다.
훈련 에폭 90에서는 데이터 혼합 기반의 MiSLAS는 Balanced Softmax보다 더 높은 정확도를 가지며 UA도 더 높다.
그 결과로 relative accruacy는 Balㅎanced softmax보다 더 낮다.
그 의미는, Balanced softmax가 클래스 불균형을 MiSLAS보다 더 완화 한다는 의미이다.
훈련에폭 200에서는 MiSLAS가 Balanced softmax보다 RA 값이 더 높다.
즉, 성능을 높이는 데 다른 요소가 있음에도 불구하고 MiSLAS는 충분한 훈련이 있으면 Balanced softmax보다 클래스 불균형을 처리하는 능력이 더 우수하다.
일부 정확도가 높은 방법들은 RA가 낮긴 하지만 long tailed 학습의 발전 경향은 긍정적이다.
성능 트렌드를 보면 long-tailed 학습이 발전중이라는 것을 확인
게다가, SOTA TADE에 대한 RA는 93.0이므로 더 발전할 가능성이 있다.
또한, 훈련 에폭을 달리하여 이에 대한 영향도 평가하였다.
전반적으로, 대부분의 방법에 대해 훈련 에폭 200으로 하는 것이 성능이 좋았다.
충분한 훈련이 있어야 심층 모델이 데이터에 최적화되고 visual representation에서 더 잘 학습하기 때문
but, 90에폭정도만 훈련해야 더 좋은 경우도 있다.
De-cofound, Decouple-CB-CRT
이 경우는, 90에폭 정도가 모델을 훈련하기에 충분하다고 추측
Observations on different method types
대부분의 CB (class re-balancing) 방법은 베이스라인에 비해 성능이 좋았다.
특히, LADE, Balaned softmax, LDAM은 SOTA 달성
Focal loss는 객체탐지의 불균형을 다루기 위해 제안되었는데, 방대한 양의 long-tailed 클래스들을 다루면 그렇게 성능이 좋진 않았다.
LDAM의 경우, cost-sensitive LDAM loss 외에도 deffered re-balancing optimization schedule이 있다.
이게 없이 그저 LDAM loss로만 학습을 할 경우 그렇게 좋은 성능을 달성하지 못할 것
대부분의 cost-sensitive 학습 방법의 UA는 같다.
따라서, relative accuray는 accuracy와 비례할 것 (Fig.4 (b))
이 경우에서는 정확도를 개선하는 것이 클래스 불균형 완화를 반영한다.
IA (information augmentation)의 경우, transfer learning (SS)와 data augmentation (RSG) 모두 클래스 불균형을 다루는 데 도움이 된다
SSP는 UA를 개선 하였지만, RA는 더더욱 개선되었다.
이는, 성능 향상이 클래스 불균형 처리에서 비롯됨을 의미한다.
MI (module improvement)에서는, 모든 하위 카테고리의 방법들이 클래스 불균형을 해결.
정확도와 RA 관점에서 현재까지 SOTA는 앙상블 기반 학습 방법임 (TADE, RIDE)
앙상블 학습이 UA를 향상하기도 하지만, 불균형 처리로 인한 성능 개선이 더 중요함
즉, RA가 더 높다 (그림 4(d))
<Results on Class Subsets>
다른 클래스 하위 집합에 대한 성능을 분석
표 6을 보면, 대부분의 방법들은 head-class의 성능을 희생하며 tail-class와 middle-class의 성능을 개선하였다.
하지만, head class도 long-tailed 학습에서 중요한 부분임
따라서, head에 대한 성능을 해치지 않으면서 long-tailed 성능을 높이는 방법이 필요하다
information augmentation, ensemble learning이 잠재적임
ex. SSP, RIDE, TADE(200에폭으로 충분히 학습)
표 5와 6을 비교해보면 전반적인 성능 향상은 주로 middle/tail 클래스의 개선에 의존함
따라서, 성능을 어떻게 높여야 하는지가 여전히 long-tailed 학습에 중요한 과제임
지금까지는 TADE가 정확도와 RA에서 전체적으로 좋은 성능을 달성했지만, TADE는 모든 하위클래스에 대해 SOTA인것은 아님
200에폭으로 훈련하였을때, head-class에대한 성능은 TADE보다 RIDE가 더 좋고 tail-class에 대한 성능은 BBN이 더 좋다.
즉, TADE의높은 성능은 long-tailed 성능이 클래스 성능에 대한 절충안이다.
요약하면 현재 심층 긴꼬리 학습에서 가장 좋은 방법은 ensemble learning과 class re-balancing
여기에서는 기본적인 증강 기법만 사용하였다.
RandAugment나 Cutmix같은 강한 데이터 증강을 사용한다면 모델 성능이 더 개선될 수 있다.
<More Discussions on Cost-sensitive Losses>
decoupled 학습 방법을 기반으로 다양한 cost-sensitive learning loss의 성능을 평가한다
첫번째 단계에서, 표현을 학습하기 위해 다른 cost-sensitive 학습 손실을 사용하여 백본모델을 훈련하였다.
두번째 단계에서, 분류기를 학습하는데 4가지 다른 전략을 사용하였다.
- joint training without re-training
- nearest class mean classifier (NCM)
- class-balanced classifier re-training (CRT)
- learnable weight scfaling (LWS)
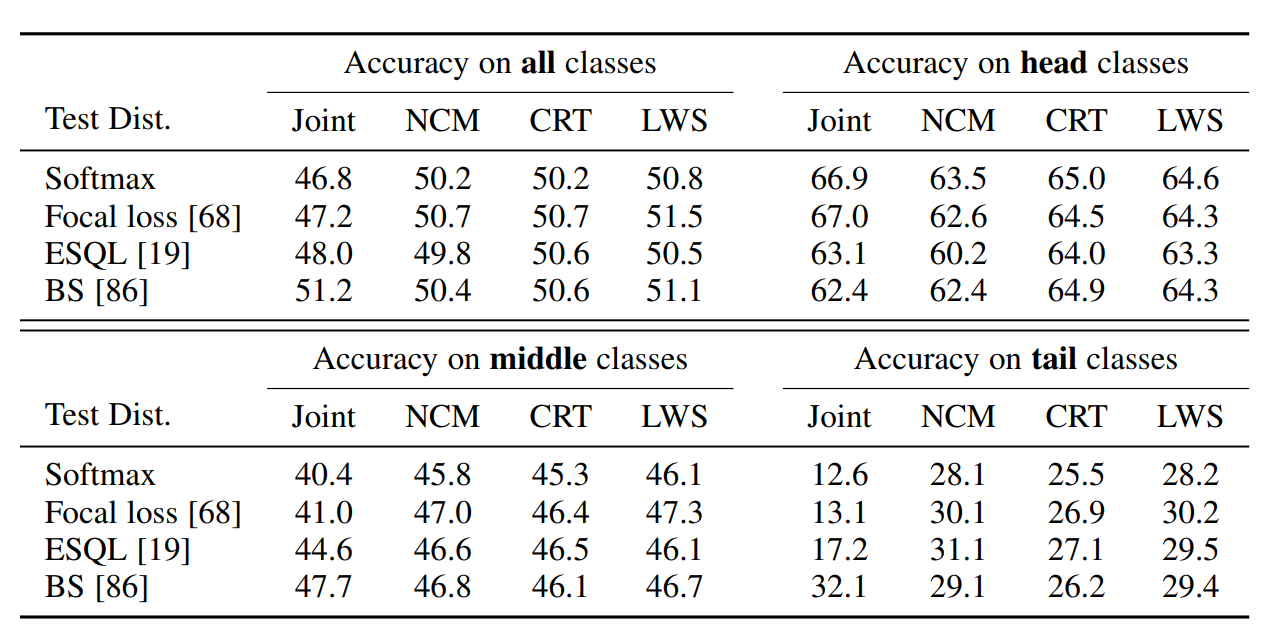
decoupled training은 balaned softmax (BS)를 제외하고 joint에서보다 전반적인 성능을 향상함
따라서, decoupled 훈련에서 해당 method를 활용하면 joint 훈련에서 가장 잘 먹히는 BS에 필적하는 성능을 얻을 수 있다.
즉, cost-sensitive loss는 joint training에서와 다르게 수행하지만 본질적으로는 유사한 특징 표현을 학습한다는 의미가 있기 때문에 흥미롭다