: Marrying Convolution and Attention for All Data Sizes
논문정리
Abstract
트랜스포머로 인해 컴퓨터 비전에 대한 관심이 높아졌지만, SOTA 컨볼루션망에 비해서는 뒤쳐지고 있다.
이 연구에서는 트랜스포머가 더 큰 모델 용량을 갖지만 편향을 올바르게 유도하지 못해 일반화 능력이 컨볼루션 네트워크에 비해 떨어진다.
두 아키텍쳐의 장점을 효과적으로 결합하기 위한 하이브리드 모델 CoAtNets을 제안
depthwise Convolution와 self-Attention은 단순한 relative attention을 통해 결합
수직으로 컨볼루션층과 어텐션층을 쌓아 일반화, 용량, 효율성 대폭 개선
이때 일반화(generalization)는 train과 validation score의 최소 gap 용량(capacity)은 overfit없이 학습할 수 있는 데이터셋의 크기
실험에 따르면 CoAtNets은 다양한 데이터셋에서 SOTA를 달성함
추가 데이터 없이 ImageNet top-1 accuracy 86.0% 달성
CoAtNet은 21K의 13M 이미지로 사전훈련되어 88.56%의 top-1 accuracy를 달성하여 JFT-300M에서 300M 이미지로 사전 훈련된 ViT-huge보다 23배 적은 데이터를 사용하였지만 성능이 비슷하다.
특히, JFT-3B로 CoAtNet을 스케일업 하면 ImageNet에서 90.88%의 top-1 accuracy를 달성하여 새로운 SOTA 갱신
Introduction
AlexNet의 획기적인 발전 이후 컴퓨터 비전 분야에선 컨볼루션 신경망(ConvNets)이 지배적인 모델 구조가 되었다.한편, 자연어처리 task에선 트랜스포머와 같은 self attention 모델이 성공하면서 이전의 연구들이 컴퓨터 비전에 어텐션을 적용하려 시도함.최근, ViT(Vision Transformer)는 vanilla Transformer layer만으로 ImageNet-1K에 대해 합리적인 성능을 낼 수 있다는 것을 보여주었다.중요한것은, ViT는 레이블이 지정된 대규모 JFT-300M 데이터셋에서 사전 훈련하면 SOTA ConvNet에 필적하는 성능을 낸다.
Transformer 모델이 잠재적으로 ConvNets보다 대규모 용량을 가질 수 있음을 나타냄
하지만 작은 데이터셋에서 학습하면 ConvNet보다 성능이 떨어진다.
이후 vanilla ViT를 개선하기 위해 특별한 정규화와 데이터 증대를 더 사용하였지만, 이렇게 ViT를 변형해도 ImageNet 분류작업에서 동일한 양의 데이터와 계산량을 사용하여 SOTA 컨볼루션 모델을 능가할 수 없었다.
vanilla Transformer 레이어가 ConvNet에 비해 inductive bias가 부족하기 때문에 많은 데이터와 계산량을 요구한다고 해석.
최근 많은 연구들이 어텐션층의 receptive fields를 local로 제한하거나 컨볼루션 연산으로 어텐션/FFN 계층을 증대하여 ConvNet의 inductive bias를 Transformer모델에 주입하려 시도함
receptive field란 각 단계의 입력 이미지에 대해 하나의 필터가 커버할 수 있는 이미지 영역의 일부
하지만 이런 접근방식은 한정적이고 특정 property를 주입하는데 포커스하기 때문에 컨볼루션과 어텐션이 결합시 각 역할에 대한 이해가 떨어지게 된다.
본 연구에선 기계 학습의 "일반화"와 "모델 용량" 측면에서 컨볼루션과 어텐션을 결합하도록 한다.
컨볼루션 레이어는 strong inductive bias로 일반화 성능이 좋으며 빠른 속도로 수렴하고
어텐션 레이어는 높은 모델 용량을 가지기 때문에 대용량 데이터셋에서 유리하다.
컨볼루션과 어텐션 레이어를 결합하면 더 나은 일반화와 용량을 얻을 수 있다.
관건은 그것을 어떻게 결합해야 정확도와 효율성간 좋은 trade-off 관계를 유지할 수 있는지
두가지 key insight
일반적으로 사용되는 depthwise convolution과 self attention은 단순 relative attention을 통해 결합이 가능하다
수직으로 conv layer와 atten layer를 쌓으면 일반화/용량 성능 up
이런식으로, ConvNet과 Transformers의 장점을 모두 누릴 수 있는 모델이 CoAtNet
CoAtNet은 low data regime 내에서, inductive bias가 좋아서 일반화 능력이 뛰어나다.
게다가 데이터가 풍부해지면 트랜스포머 모델의 뛰어는 확장성 덕에 더 빨리 수렴해서 효율이 높아진다.
훈련 시 ImageNet-1K만 사용해도 비슷한 조건의 이전 기술인 NFNet과 일치하는 top-1 accuracy(86.0%) 달성
23배 큰 데이터셋인 JFT-300M으로 사전교육을 받은 ViT-Huge와 맞먹음 심지어 CoAtNet을 JFT-300M으로 사전교육하면 효율성이 더 좋아진다. ▶ 계산량은 1.5배 줄어들고, ImageNet-1K에 대해서 90.88%의 top-1 accuracy를 보임
Model
컨볼루션과 트랜스포머를 어떻게 "optimal"하게 결합하는지에 초점을 맞춤
1. 컨볼루션과 셀프 어텐션을 어떻게 basic computation block으로 합칠 것인가? 2. 다른 유형의 compuational block들을 어떻게 쌓아야 네트워크를 완전히 형성할 수 있을까?
<Merging Convolution and Self-Attention>
컨볼루션의 경우, depthwise convolution을 사용하는 MBConv 블록에 초점을 맞춤
why? 트랜스포머와 MBConv의 FFN모듈에서 모두 "inverted bottleneck"을 사용하기 때문
입력 채널 크기를 4배 키우고 4배 커진 은닉상태를 다시 원래 채널 사이즈로 project해서 residual connection 할 수 있도록
또한, depthwise convolution과 self-attention이 predefined receptive field에서 차원 당 가중치 값의 합으로 표현될 수 있다는 것을 발견
컨볼루션은 local receptive field에서 정보를 수집하기 위해 고정 커널에 의존한다. ▶ Locality는 입력 이미지의 전체 픽셀을 고려하는 것이 아닌 일부 지역의 픽셀만 고려
식 1
xi,yi∈RD는 position i에서의 입력과 출력
L(i)는 i의 local neighborhood, 즉 이웃 픽셀들의 위치 index
i−j를 통해 상대적인 위치를 얻음 e.g. 이미지 프로세싱에서 i를 중심으로 하는 3*3 격자
즉, Conv의 각 Weight가 이미지 안에서 입력 픽셀의 위치가 어디에 있는지가 아닌 Weight와 입력 픽셀의 상대적인 위치를 고려
반면 Self-attention은 receptive field를 전체 공간(global)으로 하며, (xi,yi)간의 renormalized similarity에 기반한 가중치를 계산한다.
global rective field는 vision에는 적합하지만 연산량이 방대해 실용적이지 않아 Conv에는 잘 사용되지 않았다. 반면, 토큰(이미지에서는 픽셀)들의 개수가 적은 자연어에서는 사용되어 Attn은 global receptive field를 가짐
식 2
G는 global spatial space
어떻게 결합해야 하는지에 대해 알아보기 전에, 각각에 대한 장단점을 비교한다.
depthwise convolution 커널인 wi−j는 input에 독립적인 정적변수지만 attention weight인 Ai,j는 입력 표현에 따라 dynamic하다. 따라서, self-attention은 서로 다른 공간 위치 사이의 복잡한 관계를 이해하기 쉬움 ∵ 여러 spatial positon들 사이의 복잡한 관계성을 잘 포착 하지만 데이터가 제한된 경우 과적합되기 쉽다.
위치 (i,j)가 주어졌을 때, 해당 컨볼루션 가중치 wi−j는 상대적인 이동(i−j)만 고려한다. 이것은 translation equivalence(해당 위치의 값이 바뀌면 출력도 바뀌는 성질)라고도 하는데, 제한된 데이터셋에서 일반화 성능이 좋음 ViT의 경우 absolution positional embedding을 사용해서 위 property가 부족함 ▶ 데이터셋이 엄청 크지 않으면 ConvNet이 트랜스포머보다 나은 이유
self-attention과 convolution의 가장 큰 차이는 receptive field의 크기 receptive field가 클 수록 상황에 대한 정보를 더 많이 제공하므로 모델 용량이 커진다. ▶ self-attention이 vision분야에서 global receptive field를 사용하는 이유 하지만 크기가 커지면 더 많은 계산량을 요구함
표 1
목표는 위 표의 3가지 특성을 모두 결합할 수 있도록 하는 것
Cnv의 Translation Equivarirance + Atten의 Input-adaptive Weighting + Global Receptive Field
이를 위한 아이디어는 global static convolution kernel을 adaptive attention matrix에 합치는 것!
Softmax normalize 이전 or 이후에 이를 적용한다.
Softmax 이후
식 3-1
Softmax 이전
식 3-2
그 중 ypre의 경우에는 서로가 연관이 되어서 relative self-attention이며 어텐션 가중치 Ai,j가 input-adaptive xTixj와 translation equivaraicne wi−j에 의해 결정되어 양 모델의 장점을 끌어온다.
중요한 것은, global convolution kernel의 파라미터 수가 방대해지지 않으려면 wi−j의 값이 식 1에서 처럼 벡터가 아니라 스칼라 값이 되어야 한다. i.e., w∈RO(|G|)
또한, w가 스칼라값이면 모든 (i,j)에 대해 wi−j은 pairwise dot-product attention에 의해 계산될 수 있어서 추가 비용이 최소화된다.
이런 장점때문에 Transformer block에서 pre-normalization relative attention variant를 사용한다.\
▶ 이것이 CoAtNet 모델의 key component!
<Vertical Layout Design>
컨볼루션과 어텐션을 결합하는 방법을 알았으면, 이제는 어떻게 활용해야 네트워크를 효율적으로 쌓을 수 있을지에 대해 알아본다.
global context는 공간 크기에 대해 quadratic complexity를 갖는다.
Quadratic Time Complexity 복잡도가 입력 데이터셋의 제곱에 비례 ∴ O(n2)
따라서 raw image 입력에 대해 식3의 relative attention을 그대로 적용하면 보통의 이미지 크기내의 수많은 픽셀에 의해서 연산속도는 굉장히 느려진다.
실제로 실현 가능한 네트워크를 구성하기 위해서는 3가지 옵션이 존재한다.
(A) down-samplng으로 공간 크기(spatial size)를 줄이고 특징맵의 size가 충분히 작아지면(감당할만한 수즌이 되면) global relative attention. (B) Conv처럼 global receptive field G를 local field L로 어텐션 범위를 제한한 local attention을 수행 (C) quadratic Softmax 어텐션을 선형 복잡도를 갖는 선형 어텐션으로 대체
option C로 실험했을 때는 좋은 결과를 얻지 못했다고 한다.
option B의 경우 local attention을 구현하는데 shape formatting 연산에서 과도하게 메모리에 접근해야 했다.
연산 속도고 매우 느렸고 이렇게 하면 global attention 연산속도를 올리기 위한 목적에도 어긋나고 모델 용량에서 비효율적이다.
따라서, 본 연구진은 option A를 선택하였다.
다운 샘플링을 하기 위해서는 ViT에서 처럼 매우 큰 stride로 convolution stem (e.g. stride 16* 16)하거나 ConvNets처럼 여러개의 네트워크(multi-stage layout)를 거치면서 점진적으로 풀링하는 방법이 있다.
ViT stem은 16*16 stride로 raw image를 patch로 만드는 layer
ViT Stem
L 개의 트랜스포머 블럭을 relative attention으로 쌓고 이를 ViTREL이라 표기한다
Multi-stage layout
ConvNet를 모방해서 5단계 네트워크(S0, S1, S2, S3, S4)를 구축 이때, 공간 해상도는 S0에서 S4로 가면서 점차 줄어든다. 각 단계의 시작 부분에서는 공간 크기를 2배 줄이고 채널 수를 늘린다. 첫 단계인 S0는 단순한 2-layer convolutional Stem이고 S1은 SE(squeeze-exciation)-module이 사용된 MBConv block S2~S4는 MBConv나 Transformer block을 사용하는데 이때, Conv가 Transformer보다 먼저 나오도록 설계한다. ∵ 컨볼루션이 초기단계에서 local pattern을 더 잘 처리하기 때문 4가지 변형이 존재한다 ▶C-C-C-C, C-C-C-T, C-C-T-T, C-T-T-T (C: convolution, T: Transformer)
이제 '일반화 성능'과 '모델 용량'의 두가지 관점에서 모델 구조를 평가한다.
일반화의 경우, 훈련손실과 평가 정확도의 차이에 중점을 둔다.
두 모델의 훈련 손실이 같다면 모델의 평가 정확도가 높은 것이 일반화 능력이 좋다고 할 수 있다.
모델이 훈련 때 보지 못했던 데이터에 대해서 더 일반화 했다는 뜻이므로
일반화 성능은 훈련 데이터 크기가 제한적일때 데이터 효율에 있어서 굉장히 중요함!
모델 용량은 큰 훈련데이터셋에 fit할 수 있는 능력을 의미한다.
훈련데이터가 충분히 많고 과적합이 문제될 것 같지 않으면 높은 옹량의 모델이 훈련 후 최종적으로 가장 좋은 성능을 보일 것이다.
모델 사이즈를 키우면 모델의 용량이 커진다!
의미있는 비교를 위해서 모델 크기를 5개로 나눠서 비교해보자.
일반화능력과 모델용량을 비교하기 위해서 ImageNet-1K와 JFT 데이터셋에 대해서 어떠한 정규화나 증강을 거치지 않고 하이브리드 모델 5개를 훈련하였다.
아래는 각 데이터셋에 대해 훈련 손실과 평가 정확도
Fig 1
일반화 성능
ImageNet-1K에 대해서는 아래와 같이 나온다.
VITREL이 최악! 훨씬 안좋음.
ViT stem에서 aggressive하게 다운샘플링을 거치면서 저수준 정보를 얻기 힘들어졌기 때문이라고 추측한다.
5가지 variant 중에서는 컨볼루션층이 많을수록 일반화 성능이 좋았다.
모델 용량
JFT로 비교해봤을 때 훈련과 평가 후 아래의 순위를 보였다.
단지 트랜스포머층을 늘린다고 해서 visual processing에서 높은 용량을 얻는 것이 아님을 보여준다.
VITREL이 두개의 variant를 따라잡으면서 트랜스포머층의 capacity advantage를 보여주지만
C-C-T-T 와 C-T-T-T가 VITREL을 압도하면서 과도한 stride를 사용하는 ViT stem이 정보를 너무 손실하고 따라서 모델 용량에 한계를 가져온다는 것을 시사한다.
재밌는건(?) C-C-T-T와 C-T-T-T가 비슷하다는 것은 저수준 정보를 처리할때 컨볼루션과 같은 static local operation과 global attention mechanism의 성능이 비슷하다는 점
연산과 메모리 사용량은 더안정적으로!
그래서 C-C-T-T와 C-T-T-T 중에 결정하기 위해 transferability test를 진행하였다.
표 2
JFT로 사전훈련된 모델을 ImageNet-1K에 대해 30에폭으로 파인튜닝하고 능을 비교해보았다.
표 2에서 볼 수 있듯이 C-C-T-T가 더 좋은 transfer accuracy를 가지고 있기 때문에 (사전훈련 성능은 비슷했음) 최종적으로 C-C_T_T multi-stage layout을 채택하였다.
Related Work
<Convolutional network budiling blocks>
Convolutional Networks(ConvNets)은 많은 컴퓨터 비전 태스크 분야를 지배해온 신경망 구조였다.
이때까지는 Resnet block과 같은 일반적인 컨볼루션은 large-scale ConvNets에서 인기였고 depthwise convolution은 연산 비용과 파라미터 크기가 작은 덕에 모바일 플랫폼에서 인기였다.
최근 연구에서는 depthwise convolution을 기반으로 하는 inverted residual bottlenecks을 개선한 것이 (MBConv) 더 높은 정확도화 효율을 보여준다고 한다.
MBConv와 트랜스포머 block의 강한 연결성때문에 해당 논문에선 MBConv를 컨볼루션 빌딩 블록으로 사용한다.
<Self-attention and Transformers>
셀프어텐션의 핵심 요소로, 트랜스포머는 많은 neural language processing, speech understanding에서 널리 쓰였다.
초기 연구에서는 stand-alone 셀프 어텐션 네트워크가 다른 vision task에서도 잘 쓰일 수 있다는 것을 보여주었다.
실질적인 어려움이 있긴 하지만...
최근 ViT가 ImageNet분류에 vanilla Transformer을 적용하고 대형 데이터셋인 JFT를 사전훈련한 후로 어마어마한 결과를 달성했다.
하지만 ViT는 훈련데이터가 제한적인 경우에는 SOTA ConvNet에 비해 많이 뒤쳐졌다.
그래서 데이터의 효율성과 모델 효율성에 대해 비전 트랜스포머를 개선하는 데에 많은 연구가 집중되었다.
<Relative attention>
relative attention이라는 이름으로 엄청난 많은 변형모델이 생겨났다.
두개의 카테고리로 분류할 수 있는데
(a) input-dependent version where the extra relative attention score is a function of the input states f(xi,xj,i−j)
(b) input-independent version f(i−j)
CoAtNet의 경우에는 input-independent version에 속한다.
T5에서 사용된 것 중 하나와 비슷하지만 T5와 다르게 본 연구에서는 타 계층 간 relative attention 파라미터를 공유하지 않고 bucketing mechanism을 사용하지도 않는다.
input independence를 쓸 때의 이점은 모든 (i,j)에 대해서 f(i−j)를 얻는 것이 input-dependent와 비교했을 때 훨씬 저렴하다는 것
추론시에도 한번만 연산하면 되고 나중을 위해 캐싱할 수 있다.
최신 연구에서도 이런 input-independent parameterization을 사용하지만 receptive field를 local window 로 제한한다.
<Combining convolution and self-attention>
vision recognition 분야에서 컨볼루션과 셀프어텐션을 결합하는 것이 새로운 것은 아니다.
explicit 셀프 어텐션이나 non-local module로 ConvNet backbone을 보강하거나, 특정 컨볼루션층을 standard 셀프어텐션이나 선형어텐션과 컨볼루션을 혼합하여 대체하는 것이 일반적인 접근이다.
셀프 어텐션이 정확도를 개선하긴 하지만 추가적인 연산비용이 들기 때문에 Convnet의 추가기능 정도로 간주된다.
ViT와 ResNet-ViT가 성공하면서 인기를 얻게된 연구 주제는 explicit convolution이나 몇몇 괜찮은 컨볼루션 특성을 트랜스포머 백본에 통합하려는 것.
현재 연구가 이 분야에 속하긴 하지만 본 논문에서의 relative attention instantiation은 최소 비용으로 depthwise 컨볼루션과 content-based attention을 자연스레 결합한 것이다.
또, 일반화와 모델 용량에서 시작해서 본 연구진은 수직으로 레이아웃을 설계하는 체계적인 접근방식을 취하고(?) 서로 다른 네트워크가다른 타입의 레이어를 선호하는 이유와 방법을 보여준다. (무슨말인지..)
Experiments
CoAtNet과 이전의 결과를 비교한다.
모든 하이퍼파라미터는 별첨 A.2에 기입됨
<Experiment Setting>
CoAtNet model family
표 3
크기가 다른 기존의 모델과 비교하기 위해 CoAtNet모델의 제품군도 설계하였다.
전반적으로는 S1에서 S4까지 채널의 수를 2배씩 키우고 Stem S0의 너비는 S1보다 더 작거나 같게 함.
단순화를 위해서 네트워크의 깊이를 늘릴 때는 S2와 S3의 블록 수만 키운다.
실험에 사용된 CoAtNet 모델군은 표 3에 요약되어있다.
Evaluation Protocol
실험은 이미지 분류에 초점을 둔다.
다른 데이터 크기의 모델 성능을 평가하기 위해서 크기순으로 ImageNet-1K, ImageNet-21K, JFT 데이터셋을 사용한다.
이전의 연구를 따라서 먼저 해당 모델을 각각의 3 데이터셋으로 사전 훈련한다.
resolution 224 for 300, 90 and 14 epochs respectively
사전훈련된 모델을 ImageNet-1K로 파인튜닝한다.
at the desired resolution for 30 epochs and obtaing corresponding evaluation accruacy
한가지 예외 사항은 해상도 224에서 ImageNet-1K의 성능이며 사전훈련이 끝나면 얻을 수 있다.
트랜스포머 블록을 활용하는 다른 모델과 비슷하게, 파인튜닝 없이 high resolution으로 ImageNet-1K를 사전평가한 모델을 평가하는 것은 성능저하를 야기한다.
그러므로 resolution이 변경되면 항상 파인튜닝을 시행해야 한다.
Data Augmentation & Regularization
널리 알려진 두 데이터 증강기법을 사용한다.
RandAugment, Mixup
그리고 모델을 정규화하기 위해서는 3가지 기법을 사용한다.
stochastic depth, label smoothing, weight decay
증강, 정규화에서 하이퍼 파라미터는 모델 크기와 데이터 사이즈에 따라 달라진다.
일반적으로는 큰 모델과 작은 데이터셋에 대해 정규화를 강력하게 적용
현재 패러다임에서는 데이터 크기가 변할 수 있기 때문에 사전 훈련과 파인튜닝을 위해 정규화를 조정하는 방법이 복잡하다.
연구진은 흥미로운 것을 관찰하였는데 특정 증강기법이 사전훈련에서는 완전히 불능이었다는 것
파인튜닝 시에 단순하게 그냥 적용하기만 하면 성능 개선 보다는 오히려 하락을 야기할 수 있다.
데이터 분포가 변형되었기 때문이라고 가정함.
결론은, 제안된 모델의 특정 실행 시, 두개의 큰 데이터 셋(ImageNet-21K, JFT)에 대해 사전훈련할 때 RandAugment와 stochastic depth을 사용한다.
이런 정규화는 사전훈련 metric에 손상을 줄 수 있지만 파인튜닝동안 정규화/증대를 다양하게 하고, 다운스트림 성능을 개선한다.
<Main Results>
Fig 2, Fig 3
ImageNet-1K 데이터셋만을 사용한 실험 결과는 표4에 있다.
비슷한 환경에서는 제안된 CoAtNet 모델이 ViT 변형보다 성능이 좋을 뿐만이 아니라 컨볼루션만을 사용한 구조(i.e. Efficientnet-V2, NFNets)와 일치한다.
위 그림은 224*224 해상도에서 모든 결과를 시각화한 것.
사진에서 보듯이 CoAtNet이 이전의 어텐션모듈을 사용한 모델보다 더 확장한다.
표 4
ImageNet-21K
표4와 그림3에서 보듯이 ImageNet-21K가 사전훈련에 쓰이면 이전 모델들을 많이 압도하면서 CoAtNet의 장점이 도드라진다.
특히, CoAtNet의 변이 모델 중 하나는 top-1 accuracy를 88.56% 달성하면서 ViT-H/14의 성능인 88.55%와 비슷해졌고 이는 2.3배 큰 ViT 모델을 23배의 취약데이터(JFT)를 가지고 2.2배 학습시킨 결과와 비슷하다.
이것은 데이터 효율과 연산 효율을 모두 엄청나게 개선한 것이다.
JFT
마지막으로 표5를 보면 JFT-300M, JFT-3B의 대규모 데이터 체제에서 CoAtNet을 평가한다.
CoAtNet-4가 JFT-300M에서 연산시간과 파라미터수를 2배 줄이면서 이전의 NFNet-F4+가 기록한 최고 성능을 거의 따라잡았다.
NFNet-F4+와 연산 자원을 비슷하게 모델을 키웠을대는 CoAtHNet-5가 89.77% top-1 accuracy를 기록하면서 이전의 결과를 능가하였다.
게다가 ViT-G/14의 수준으로 훈련자원을 키우고 훨씬 더 큰 크기의 JFT-3B를 활용하면 CoAtNet-6이 1.5배 적은 연산량으로 90.45%를 기록한 ViT-G/14의 성능을 따라잡았다.
CoAtNet-7은 90.88%의 top-1 accuracy를 기록하면서 새로운 SOTA를 갱신하였다.
<Ablation Studies>
표 6
이제는 CoAtNet의 설계를 축소해보자.
먼저, 컨볼루션과 어텐션을 하나의 computation unit으로 결합하는데에 relative atrtention이 중요하다는 것을 알았다.
ImageNet-1K와 ImageNet-21K에 대해 relative attention을 쓴 것과 아닌 두개의 모델을 비교하였다.
표 6에서 보면 ImageNet-1K만 쓰였을 땐, relative attention이 standard attention을 더 좋은 일반화 성능으로 확실히(?) 능가하였다.
게다가, ImageNet-21K 전이학습에서는 사전학습 정확도는 비슷하지만 relatvie attention variant가 상당히 더 나은 transfer accuracy를 달성하였다.
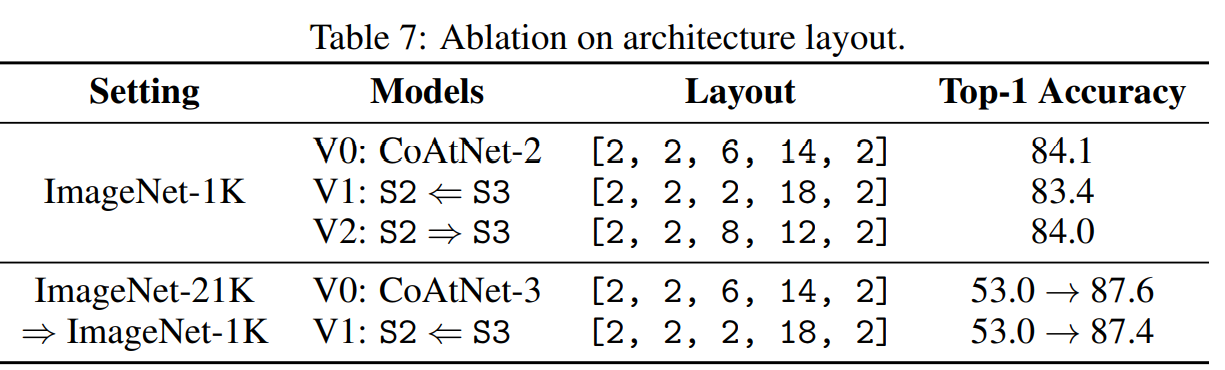
표 7
다음으로 MBConv block인 S2와 relative Transformer block인 S3가 CoAtNet 연산의 대부분을 차지하는데 문제는 어떻게 S2와 S3의 연산을 분리해서 더 좋은 성능을 얻을까 하는 것이다.
실제로는, 각 스테이지에서 몇개의 블록을 사용하는지 결정하는 것으로 이를 "레이아웃"설계라 한다.
이를 위해 표7에서는 레이아웃을 달리 설정하여 실험해 비교하였다.
V0가 S2와 S3에의 총 블록 수는 고정하고 각 단계에서의 수를 변화시킨 V1와 V2의 sweet spot! 기본적으로 S2의 MBConv 블록수가 너무 적어져 일반화 성능이 줄어들기 전까지는 S3에서 트랜스포머 블럭을 많이 가져갈수록 성능이 좋아진다.
위의 sweet spot이 용량이 중요하게 여겨지는 전이학습에서도 잘 유지되는지 평가하기 위해, V0과 V1을 ImageNet-21K를 ImageNet-1K로 전이학습시킨 결과를 비교한다. 재밌는 것은 V1고 V0이 ImageNet-21K에 대해서는 같은 성능을 보였지만 V1의 transfer accuracy가 v0보다 떨어지게 된다는 것. 다시말해 좋은 전이능력과 일반화를 위해서는 컨볼루션이 중요한 역할을 한다.
표 8
마지막으로 모델 세부사항의 두가지 선택지를 연구한다.
어텐션 헤드(기본적으로는 32)의 차원과 MBConv에서 사용되는 정규화 유형(기본적으로는 BatchNorm)
표 8에서는 어텐션 헤드를 32에서 64로 늘렸을 때 TPU속도는 향상시켰지만 성능이 떨어진 것을 볼 수 있다.
사실 이것은 quality와 speed의 trade-off 관계때문이라고 할 수 있다.
반면 BatchNorm과 LayerNorm은 거의 같은 성능을 보였는데, BatchNorm이 TPU에서 10-20% 빠르다.
Conclusion
이 논문에선, 컨볼루션과 트랜스포머의 특성을 체계적으로 연구하여 CoAtNet이라는 모델로 결합하는 방법을 이끌어냈다.
많은 실험을 통해 CoAtNet이 좋은 ConvNets처럼 좋은 일반화 성능과 트랜스포머처럼 우수한 모델 용량을 모두 갖췄다는 것을 보여주어 각기 다른 데이터 크기에서 SOTA성능을 기록하였다.
이 논문은 ImageNet 분류에 초점을 두었지만 이 접근법이 객체탐지나 의미적분할 등의 더 많은 응용으로 적용할 수 있다고 믿는다.
이 부분은 후속 연구에 맡긴다
Appendix
<2D Relative Attention>
식 3에서 [H,W]이미지에 대해 각 헤드에서 relative attention의 pre-norm 버전을 구현하기 위해 [(2H−1)×(2W−1)]크기의 학습가능한 파라미터 P를 선언한다.
maximum distance는 각각 2H-1, 2W-1
그리고 공간에 대한 위치 2개 (i,j), (i′,j′)의 경우 대응하는 상대편향(relative bias)은 Pi−i′+H,j−j′+W이다.
상대 편향(relative bias) 편향을 참값으로 나누어 백분위(percentage)로 표준화한 척도
구현을 위해서 [(2H−1)×(2W−1)] 행렬로부터 H2W2 원소들을 인덱스할 필요가 있다.
TPU상에서 상대편향을 인덱스하기 위해 각 height과 width 축을 따라서 두개의 einsum연산을 적용한다.
이때 연산복잡도는 어텐션복잡도 O(H2W2D)보다 작은(?) O(HW(H+W))가 되도록
GPU상에서 gather로 더 효율적으로 인덱싱할 수 있는데 메모리 접근만을 필요료 한다.
추론 시에는 처리량 증가를 위해 [(2H−1)×(2W−1)]크기의 행렬에서 H2W2원소에 대한 인덱싱을 사전에 연산되고 캐싱할 수 있도록 한다.
높은 해상도를 파인튜닝할 때 단순히 이중선형 보간법(bilinear interpolation)을 이용한다.
크기를 [(2H−1)×(2W−1)]에서 원하는 크기의 [(2H′−1)×(2W′−1)]로 증가 이때 H′>HandW′>W