

논문정보
Multi-Evidence and Multi-Modal Fusion Network for Ground-Based Cloud Recognition
논문정리
Abstract
많은 딥러닝 네트워크가 ground-based 구름 영상분류에 쓰였음
하지만 여태까지는 이미지에서 얻어지는 글로벌특징에 주심을 두어서 구름에 대해 완벽하지 않은 표현을 얻었음
이 논문에선 MMFN (Multi evidence and Multi-modal Fusion Network)를 제안하여 하나의 통합된 프레임워크에 여러 종류의 특징들을 융합하여 확장된 구름 정보를 학습함
즉, MMFN은 메인네트워크와 주의 네트워크로 여러개의 evidence(global and local visual features)을 이용한다.
main network and attentive network
Attentive netowrk에선 컨볼루션 활성화 맵에서 나온 중요한 패턴들을 정제하여 얻어지는 attentive map으로부터 local visual feature을 얻음
그동안 Multi-modal Network는 ground-based 구름 이미지에서 multi-modal feature을 학습한다.
multi-modal과 multi-evidence의 특징을 완전히 융합하기 위해서 본 연구진은 두개의 융합 레이어(fusion layer)를 설계하여 multi-modal feature과 global/local visual feature을 각각 통합하였다.
Introduction
구름 관측을 위한 3 major way : space-based satellite, air-based radiosonde, ground-based remote sensing
그중에서도 ground-based remote sensing 관측을 위한 장비(total sky imager, all sky imager)가 빠른 속도로 개발되어 저비용으로 구름 분석을 위한 고해상도 remote sensing image를 제공한다.
지상기반 구름 인식은 필수적이고 어려운 과제이다.
충분한 양의 지상기반 구름이미지로 이 구름 인식은 최근 수십년동안 학계에서 광범위하게 연구됨
but 기존 알고리즘의 대부분은 hand-crafted feature (밝기, 질감, 모양, 색상, ...)을 이용하여 구름이미지를 나타내어 복잡한 데이터 분포를 모델링하는 데는 역부족
최근엔 CNN이 여러분야에서 놀라운 성능을 보여주면서 몇몇 연구진들은 CNN을 통해 지상기반 구름 이미지에서 visual feature을 활용하고 이에 대한 인식 성능을 새로운 차원으로 끌어올림
여러 레퍼런스가 있는데 skip (논문 참조)
아무튼 이런 CNN 기반의 방법들은 전체 구름 이미지만을 이용해서 global visual feature을 학습함
서로 다른 운형의 구름이 비슷한 패턴을 가지는 경우가 있는데, 이렇게 되면 분류기에 혼란을 주게 된다.Ye et al은 여러 컨볼루션층에서 패턴마이닝과 선택전략을 통해 local visual feature을 모아 피셔벡터를 통해 인코딩하였다.
Ye, L.; Cao. Z.; Xiao, Y. DeepCloud: Ground-based cloud image categorization using deep convolutional features. IEEE Trans. Geosci. Remote 2017, 55, 5729–5740
but, 이렇게되면 local visual feature만 고려하게 되고 이런 특징들은 학습과정 없이 사전훈련된 CNN에서 얻는 것이다.
지상기반 구름이미지들은 클래스간 차이는 적고 클래스 내 차이는 다양해서 매우 복잡하기 때문에 현재 존재하는 방법들은 정확한 구름 인식을 만족시키지 못한다. ▶ 그림 1 참고

구름 이미지에 포함되어있는 시각적 정보는 구름을 단지 시각적인 특성만을 이용하여 표현하는데, 구름의 외형이 (같은 클래스 내에서도) 너무 다양하기 때문에 구름을 정확하게 묘사할 수 없다.
large variances in cloud apperance
구름의 형성은 온도, 습도, 기압, 풍속 등 다양한 자연적 요인들에 의해 복합적으로 이뤄지고 구름은 이런 정보들과 강한 상관관계를 맺는다.
multi-modal information
예를들어, 습도는 구름의 발생확률과 관련이 있고 구름의 외형은 바람의 영향을 받는다.
그렇기때문에 단순히 구름의 visual representation만을 이용하는 것보다 이런 multi-modal information을 같이 활용하는 것이 더 합리적이다.
Liu and Li는 심층 컨볼루션층의 특징맵에서 같은 위치별로 pooling activation을 하여 얻어진 sum convolutional map을 stretch하여 심층 특징을 추출하여 multimodal 특징과 융합하였음.
Liu, S.; Li, M. Deep multimodal fusion for ground-based cloud classification in weather station networks. EURASIP J. Wirel. Comm. 2018, 2018, 48
Liu et al은 two-stream network를 제안하여 구름이미지와 multi-modal 정보를 공동으로 학습한 후, 이 두가지 정보를 융합하기 위해 weighted strategy 사용
S. Liu, M. Li, Z. Zhang, B. Xiao and X. Cao, Multimodal ground-based cloud classification using joint fusion convolutional neural network. Remote Sens. 2018, 10, 822
하지만, 이미지와 정보를 동시에 이용하여 구름을 인식하는 것은 여전히 문제이다.
게다가 현재 공식적으로 사용할 수 있는 구름 데이터셋은 데이터가 풍부하지 않기 때문에 구름 인식에 제한이 있다.
이 논문에선 위에 언급된 문제들을 고려하여 multi-evidence and multi-modal fusion network(MMFN)을 제안하여 global visual feature, local visual feature, multi-modal information을 융합할 수 있도록 하였다.
MMFN은 주로 3가지 요소로 구성되어있다.
main network, attentive network, multi-modal network.
main network, attentive network는 multi-evidence (global and local visual feature)를 추출하여 시각적 정보를 제공한다.
multi-modal network는 multi-modal 특징들을 학습하기 위해 완전연결층으로 구성되어있다.
데이터셋 MGCD에 대한 설명은 skip
아무튼 이 논문을 요약하면 다음과 같다.
제안된 MMFN은 multi-evidence와 multi-modal 특징들을 end-to-end으로 결합하여 구름 인식 성능 최대화
Attentive network는 컨볼루션 활성맵에서 패턴을 정제하여 더 믿을수있고 차별적인 local visual 특징을 학습
MGCD 데이터셋 배포
Methods
MMFN은 ground-based 구름 이미지와 multi-modal 정보를 결합하여 구름 인식에 사용된다.
위 그림에서 볼 수 있듯, MMFN은 3개의 네트워크(main, attentive, multi-modal)와 2개의 결합 레이어(concat 1, concat 2), 2개의 완전연결층 (fc5, fc6)으로 이뤄져있다.
<Main Network>
메인 네트워크는 전체 이미지로부터 global visual feature을 학습하는데 사용되며 널리 사용되는 ResNet-50을 활용하였다.
그림 3은 ResNet-50의 구조를 요약
크게 6개 요소로 구성되어 있다.
conv1, conv2_x ~ conv5_x, fc layer
conv2_x ~ conv5_x는 각각 3,4,6,3의 residual 빌딩블록을 가짐
conv3_x를 예로 들면, 4개의 residual 빌딩블록이 있고, 각 블록에는 3개의 컨볼루션층이 있는 셈
최종 fc층은 메인네트워크에서 사용하지 않고 conv5_x의 출력값이 average pooling layer (avgpool1)을 거친 후 2048-차원의 벡터가 되어 fusion layer (concat1)의 input으로 들어감
<Attentive Network>
CNN은 구름의 구조와 텍스쳐 정보가 반영되는 local region에 더 주의를 둔다.

그림 4에서 CNN의 특징을 시각화하였고, 이미지에서 두드러진 영역이 인식 과정에서 결정적인 역할을 함을 보여줌
그래서 global feature을 보완할 수 있는 local feature을 추출하는 것이 중요하다.
게다가 얕은 컨볼루션층에서 convolutional activation map은 풍부한 저수준특징(구조, 텍스쳐,...)을 담고 있다.
attentive network을 설계할 때, attentive map과 2개의 컨볼루션층 (conv2, conv3), 1개의 average pooling layer(avgpool2)으로 구성하고 convolutional activation map에서 local visual feature을 추출하였다.
특히, 먼저 컨볼루션 활성맵에서 두드러진 패턴을 정제하여 semantic 정보를 포함하는 attentive map을 얻고, 여기서 나온 local visual feature을 최적화한다.
신뢰성과 차별성이 있는 local visual feature을 학습하기 위해서, attentive map을 attentive network의 첫 파트로 제안하였고, 이는 컨볼루션 활성맵 이후에 나온 도드라진 패턴들을 정제해서 만들어진 것이다.
연구진은 conv3_x에 있는 첫번째 residual 빌딩 블록의 컨볼루션 활성맵을 attentive map의 입력값으로 사용함
Xi=xi,j|j=1,2,⋯,h×w이라 하고 이는 i번째 컨볼루션 활성맵을 의미한다.
여기서 xij는 j 위치에서의 response
h,w는 컨볼루션 활성맵의 높이와 폭
그러면 conv3_x의 첫번째 블록에는 512개의 컨볼루션 활성맵이 있고 이때 h=w=28이 된다.
i번째 컨볼루션 활성맵에 대해 xi,j xi,h×w를 내림차순으로 정렬하고 그 중 상위 n×n개의 response를 선택한다.
그 후, 이들을 다시 n×n의 attentive map으로 내림차순을 유지한 채 재구성한다.
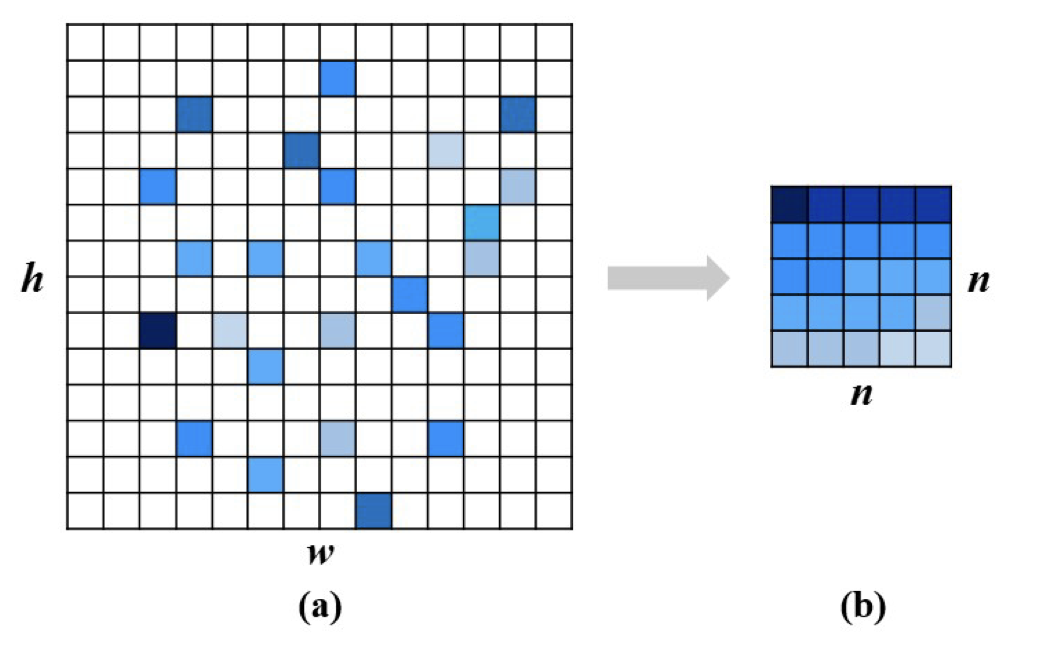
그림 5에서 이 과정을 시각화해서 보여준다. 이제 이 전략을 모든 컨볼루션 활성맵에 적용하면 512개의 attentive map을 얻게 된다.
즉, attentive map은 의미있는 content에 대해 더욱 높은 response를 모으게 되는거고, 도드라지지않은 response에 대한 부정적 영향을 제거하게 됨.
이후, attentive map은 드롭아웃층을 거친다. conv2, conv3, avgpool2는 비선형 변환을 통해 attentive map을 더 고차원 벡터로 변형시킨다.
conv2, conv3의 컨볼루션 커널은 각각 2와 1의 스트라이드의 3×3,1×1 size
conv3에서 1×1의 컨볼루션 커널을 사용하는 이유는 출력 차원을 높이기 위함이란 걸 잊지 말자!!
conv2, conv3의 컨볼루션 커널의 수는 각각 512와 2048이다. 이들은 모두 batch normalization에 의해 정규화되고 Leaky ReLU를 거친다.
avgpool2의 출력은 2048-이며 concat2로 들어간다.
즉, 제안된 MMFN은 main과 attentive network을 이용해서 multi-evidence를 추출하고 통합된 프레임워크 내에서 구름 ㅣ미지를 표현할 수 있게 된다.
<Multi-Modal Network>
multi-modal feature을 학습하기 위해 multi-modal network를 적용하였음. multi-modal feature은 벡터 형태로 네트워크의 입력값으로 들어가고 네트워크는 4개의 완전연결층 fc1 fc4로 설계되었다. 각 층의 뉴런 수는 64, 256,512,2018.
처음 3개의 층은 batch normalization과 Leaky ReLU 활성화를 거친다.
fc4의 출력은 Leaky ReLU를 거치고 concat1,concat2의 입력으로 들어간다.
이를 multi-modal network의 출력으로써 앞으로는 fm이라 표기한다.
<Heterogeneous Feature Fusion>
feature을 결합하는 것은 다양한 분야에서의 풍부한 정보들을 학습하기 위한 효과적인 방법
feature fusion method는 homogeneous feature fusion과 heterogeneous feature fusion으로 나뉘는데, 전자는 skip,,
heterogenous 특징 결합은 각 특징들이 상당히 다른 분포와 데이터 구조를 가지고 있기 때문에 더 복잡한 편
메인 네트워크, 주의 네트워크, 멀티모달 네트워크에 대한 출력을 각각 fg,fl,fm으로 표기하고 각각 2048- 차원
처음부터 global visual feature, local visual feature, multi-modal feature
fg는 전체적인 구름 이미지를 학습한 특징이고, 메인 네트워크에서 깊은 층을 거쳤기 때문에 semantic한 정보가 더 담겨있음
fl은 얕은 컨볼루션 활성맵에서 나온 두드러진 패턴으로 texture information을 담고 있음
위의 visual feature과는 다르게 fm은 multi-modal information측면에서 구름을 표현함
따라서, 위의 특징들이 각각 다른 측면에서 구름을 표현하고 각각 상호보완적인 정보를 갖고 있다.
이를 최대환 활용하기 위해선 multi-modal 특징을 각각 global, local visual 특징과 결합할 수 있어야 함
이 논문에선, 두개의 결합 레이어를 제안한다.
concat1은 fm,fg을 결합하고, concat2는 fm,fl를 결합
먼저, concat1에서 fg,fm을 결합하는 알고리즘
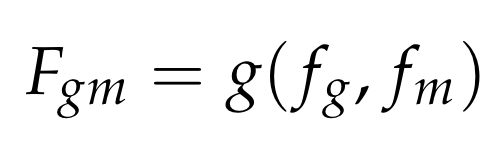
이때 g(⋅)은 결합연산
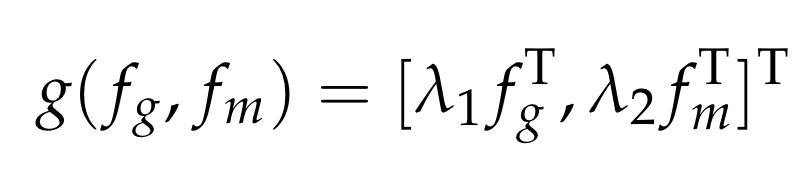
[⋅,⋅]은 두 벡터를 concatenate
λ1,λ2는 fg,fm의 비중에 대한 계수
이제, fl,fm을 결합한 concat2도 유사하게 표현할 수 있다.
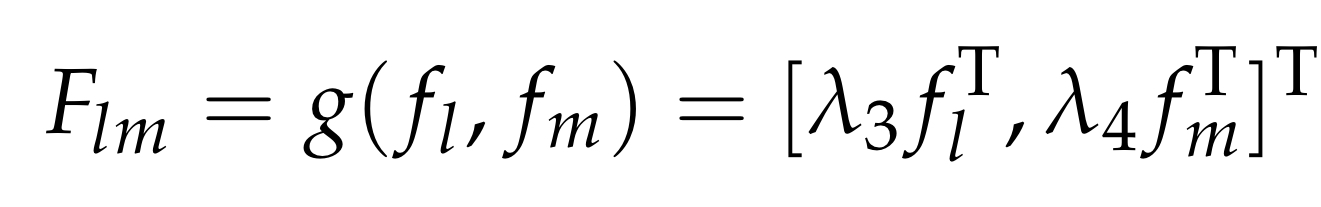
λ3,λ4는 fg,fm의 비중에 대한 계수
최종 완전연결층 fc5,fc6은 인식작업에 사용되고 각각 concat1,concat2에 연결되어있다.
각각 K개의 뉴런을 가지며 이때 K는 구름 클래스 수를 의미한다.
fc5의 출력은 소프트맥스 활성화를 거치며 k 카테고리에 대한 라벨 예측은 각 카테고리에 대한 확률을 표현
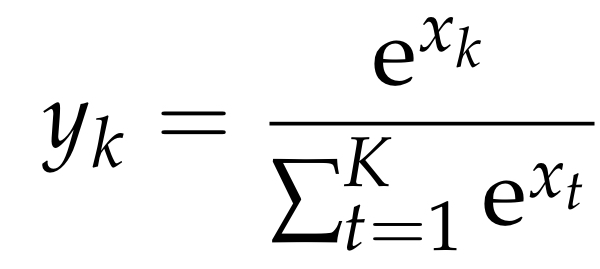
식 4는 소프트맥스 활성화 연산이며 이때 xk,yk∈[0,1]는 fc5의 k번째 뉴런의 값이고 k번째 카테고리에 대한 확률을 나타냄
크로스 엔트로피 손실은 손실값을 계산하기 위해 사용되었다.
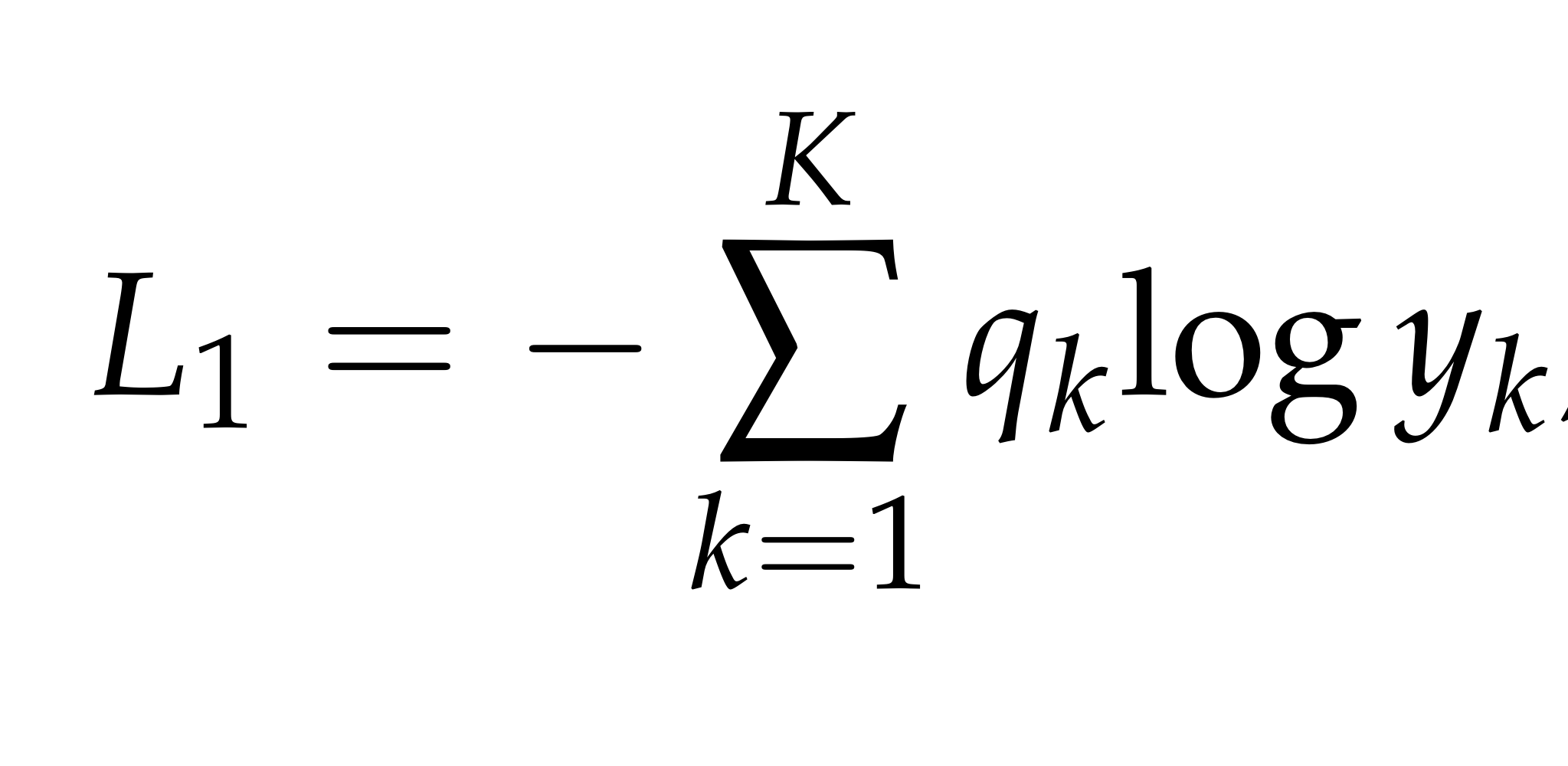
식 5는 크로스 엔트로피 손실에 대한 식이고, 이때 qk는 ground-truth 확률을 의미한다.
이 값은 k가 ground-truth 라벨이 맞을때 1이 되고 이 외에는 0.
fc6층은 fc5와 유사하다.
즉, 출력이 소프트맥스를 거친 후 크로스 엔트로피 손실 L2에 의해 평가된다.
MMFN모델에 대한 총 비용은 다음과 같이 계산한다.
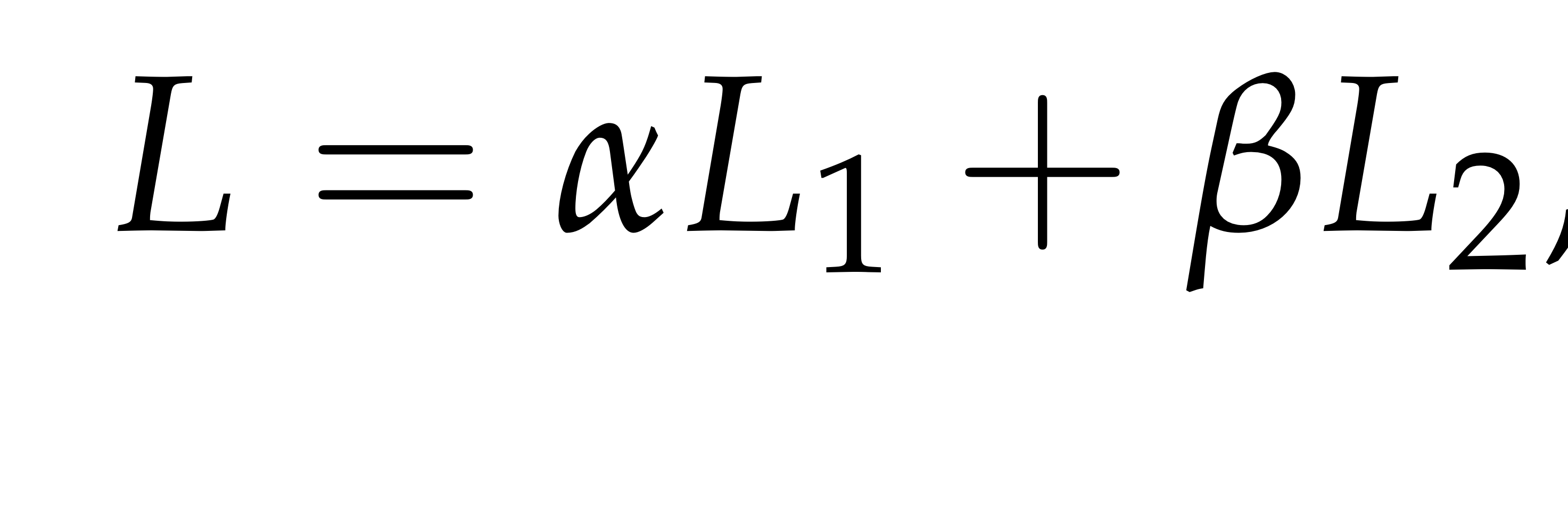
이때, α,β는 L1,L2에 대한 균형을 맞추기 위한 가중치이다.
그러므로, MMFN을 최적화하기 위해서는 식6을 최소화시키는 것을 의미하고 MMFN 훈련은 end-to-end process!
하나의 네트워크에서 global, local, multi-modal feature을 결합할 수 있게 된다.
MMFN 훈련 이후에는 식2와 식3을 통해 결합된 특징 Fgm,Flm을 추출하고 이 둘은 직접적으로 concatenate 되어서 구름 샘플에 대한 최종 표현으로 사용된다.
요약하자면, 제안된 MMFN은 다음의 세가지 특성을 갖는다.
- attentive network는 구름 이미지에 대해서 더 신뢰성있고 차별성있는 local visual feature을 학습하기 위해 컨볼루션 활성맵에서 도드라진 패턴을 정제하기 위해 사용된다.
- MMFN은 heterogeneous data를 다룰 수 있다. MMFN의 3가지 네트워크는 각각의 다른 데이터들을 하나의 통일된 포맷으로 변형킴
- MMFN은 결합된 특징에서 더 학습할 수 있는데, 각각의 다른 특징들이 2개의 fusion layer에 의해 결합되고 하나의 통일된 프레임워크내에서 최적화되기 때문이다.
<Comparison Methods>
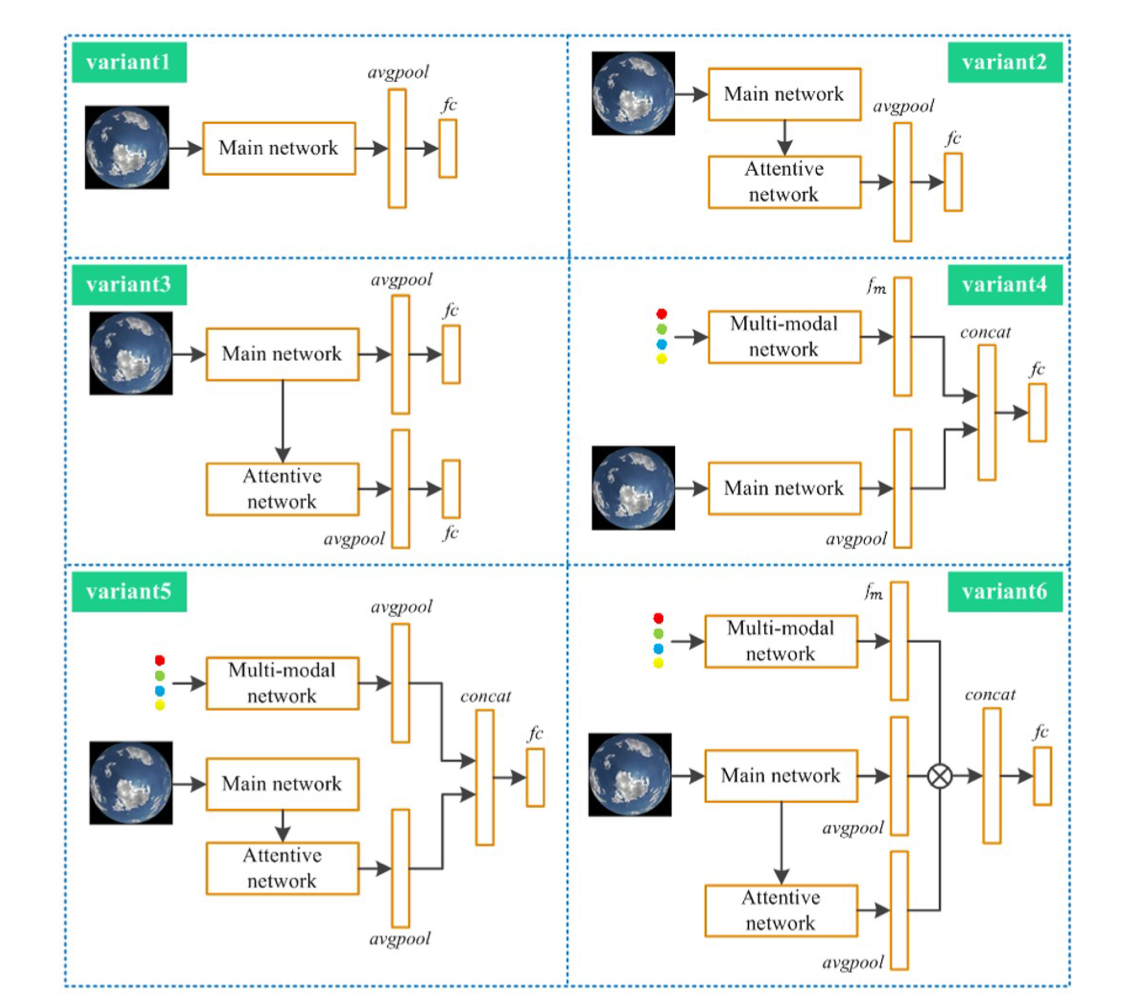
Variants of MMFN
성능을 실험하기 위해 6개의 케이스로 나눠 훈련함
각 variant는 아래 그림에서 참조 (설명은 skip)
Hand-crafted and Learning-Based Methods
구름 분류에 대해 hand-crafted method, learning-based method에 대한 연구들을 설명함
여기서는 skip
<Implementation Deatils>
먼저 구름 이미지를 252x252 크기로 조절 한 다음 랜덤하게 크롭하여 224x224의 크기로 맞춘다.
구름 이미지는 랜덤하게 수평전환하여 증강하고 mean subtraction을 이용하여 정규화
multi-modal 정보 (온도, 습도, 압력, 풍속)은 [0,1]로 조정
Main network는 ImageNet 데이터셋으로 사전훈련된 ResNet-50으로 초기화
conv2, conv3, fc 층에 대해서 레퍼런스 [59]의 가중치 초기화를 적용함
He, K.; Zhang, X.; Ren, S.; Sun, J. Delving deep into rectifiers: Surpassing human-level performance on imagenet classification. In Proceedings of the IEEE International Conference on Computer Vision; Santiago, Chile, 7–13 December 2015; pp. 1026–1034.
배치 정규화 층의 가중치는 평균이 1이고 표준편차가 0.02인 정규분포를 따라 초기화하고,
컨볼루션 층, 완전연결층, 배치정규화 층의 편향은 모두 0으로 초기화
Attentive map을 만들때는 노이즈나 이상치의 영향을 줄이기 위해 top-5 response는 제외함
훈련하는 동안 SGD 옵티마이저를 사용하여 파라미터 업데이트하고 배치크기 32로 50에폭 학습
weight decay는 2×10−4에 momentum은 0.9로 세팅
학습률은 3×10−4으로 초기화 한 뒤 에폭 14, 에폭35에 0.2만큼 감소
Leaky ReLU의 slope는 0.1로 고정하고, attentive network의 드롭아웃층에서 drop rate는 0.5
Multi-modal network에서 파라미터는 [-0.01, 0.01]로 제한한다.
MMFN 훈련이 끝나면, 각 샘플은 8192-의 차원으로 표현된다.
결합벡터 fgm,flm을 concatenate하여 생성
이는 곧 SVM classifier를 훈련하는데 사용됨
논문에서 소개된 매개변수도 있다.
attentive network에서의 n
식2와 식3에 사용된 λ1, λ4
식 6에 사용된 α,β
n=7,(λ1,λ2)=(0.3,0.7),(λ3,λ4)=(0.3,0.7),α=β\1로 정하였음
섹션 4.3에 각기 다른 세팅에 대한 성능 정리되어있음
Data
Multi-modal Ground-based Cloud Dataaset (MGCD)는 구름 이미지와 multi-modal 정보가 포함되어 있다.
22개월동안 각기 다른 장소와 시간에서 촬영되었다.
총 8000개의 샘플이 있으며, 각 샘플 하나하나마다 이미지에 대응되는 multi-modal 정보가 있음
구름 이미지 해상도는 1024x1024 (JPEG format)
multi-modal 정보는 (온도, 습도, 압력, 풍속)의 벡터로 표시
구름 종류는 WMO 기준과 시각적 유사도에 따라 7개로 나누었음
- cumulus
- altocumulus and cirrocumulus
- cirrus and cirrostratus
- clear sky
- stratocumulus, stratus and altostratus
- cumulonimbus and nimbostratus
- mixed cloud
구름 이미지에서 운량이 10%미만인 것들은 clear sky로 분류
첫11개월 사진은 훈련셋으로, 이후 11개월 사진은 테스트셋으로 사용해서 각 셋마다 4000개의 이미지

Results
스킵
Discussion
<Overall Discussion>
관련 연구 소개와 한계점 언급
성능이 높은 연구방법들도 많지만 데이터셋이 작거나 공개되지 않음
특히 JFCNN은 이미지와 멀티모달 정보를 이용하여 구름 분류 정확도 93.37%를 달성했지만 오직(?) 3711개의 이미지만 사용하였고 훈련/테스트 셋 사이에 높은 의존성이 있을 것이라고 보았음
따라서 새로운 공개 데이터셋 MGCD 소개하고 MMFN 네트워크 정리
<Potential Applications and Future Work>
이후 연구에선 비지도 방식 활용
Conclusion
본 연구에선 구름 인식을 위해 MMFN이라는 새로운 방법 제안.
제안된 MMFN은 heterogeneous feature을 통합된 프레임워크 내에서 결합하여 학습할 수 있음.
게다가 attentive map이 제안되었는데 이는 두드러진 패턴에서 local visual feature을 추출하기 위함
두개의 결합레이어를 활용하여 multi-modal 특징을 각각 global visual, local visual 특징과 결합함
또한, 구름 이미지와 multi-modal 정보가 있는 새로운 구름 데이터셋 MGCD를 공개함
MMFN을 평가하기 위해서, 다양하게 실험을 수행했고 MMFN이 sota method로써 보일 수 있다고함
MGCD is available at https://github.com/shuangliutjnu/Multimodal-Ground-based-Cloud-Database.