

논문정보
A Novel Plug-in Module for Fine-Grained Visual Classification
A Novel Plug-in Module for Fine-Grained Visual Classification
Visual classification can be divided into coarse-grained and fine-grained classification. Coarse-grained classification represents categories with a large degree of dissimilarity, such as the classification of cats and dogs, while fine-grained classificati
arxiv.org
논문정리
Abstract
이미지 분류는 course-grained, fine-grained classification으로 나눌 수 있다.
Fine-grained, course-grained은 하나의 프로세스를 세밀하게 할지, 큼직큼직하게 할지에 따른 정도를 표현함
가령 Cifar100, ImageNet, MNIST의 데이터셋을 이용해서 분류를 하면 course-grained,
fine-grained는 이보다 더 세밀하게 분류를 하는데, course-grained에서는 '개'라는 것을 분류했다면
fine-grained는 같은 개라는 동물종 내에서도 개의 품종을 분류하게 되는 것
https://light-tree.tistory.com/215
Coure-grained 분류는 '개'와 '고양이'의 분류 같은 차이가 큰 카테고리를 표현한다.
Fine-grained 분류는 '고양이 종', '새 종', '차종'들간의 분류와 같이 유사도가 큰 카테고리를 표현한다.
Course-grained 이미지 분류와 달리 fine-grained 이미지 분류는 데이터를 라벨링하는데 전문가가 요구되어 데이터 비용 up
따라서, 많은 연구에서 자동으로 discriminative region을 찾고, 더 정확한 특징을 찾기 위해 local feature을 사용했다.
이런 접근법은 image-level의 annotation만 필요로 하기 때문에 비용을 줄일 수 있다.
하지만, 이런 방법들은 2개 이상의 구조(multi-stage)를 사용하기 때문에 end-to-end학습이 불가능하다.
본 논문에서는 새로운 plug-in module을 제안하여 여러 백본 모델에 통합될 수 있도록 하고 차별성이 높은 영역을 제공한다.
CNN 기반, 트랜스포머 기반 네트워크
Plug-in module은 pixel-wise 특징맵을 출력으로 하고 필터링된 특징들을 융합하여 fine-grained 이미지 인식 성능을 높인다.
실험 결과를 통해 제안된 plugin 모듈이 SOTA 접근법을 능가하고, CUB200-2011, NABirds 데이터셋에 대해 각각 정확도 92.77%, 92.83%을 달성하였다.
소스코드는 https://github.com/chou141253/fgvc-pim에 배포함
Introduction
이미지 분류는 course-grained, fine-grained 분류로 나눌 수 있다.
"Fine-grained"는 일반적인 종을 분류하는 것에서 더 세밀하게 분류하는 것을 의미한다.
fine-grained 이미지 인식에서 어려운 점은 3가지
- 같은 카테고리 내 분산이 크다. 새를 예로 들면, 같은 새를 다른 각도에서 찍었을 때 모양과 색이 크게 다를 수 있다.
- 다른 하위 카테고리 내의 객체들이 유사하다. 그림 1에서 3가지 다른 새의 texture가 비슷비슷하다.
- course-grained 분ㄹ와 다르게 fine-grained 분류는 데이터를 라벨링하는데 전문가가 요구된다.

위 문제점 때문에, course-grained 분류 작업에서 성능이 좋은 프레임워크 (e.g., ResNet, Efficientnet, Vision Transformer)들이 fine-grained 분류에서는 한계점을 보인다.
차별성이 높은 영역을 찾아 fine-grained 이미지 분류성능을 높이기 위해 제안된 접근법들을 3가지로 나눌 수 있다.
- RPN(Region Proposal Network)를 통해 영역을 찾는다. e.g., NTS-Net, FDL, StackedLSTM
- 어텐션 구조를 통해 특징 맵을 강화한다. e.g., CAL, MA-CNN, MAMC, API-Net, WS-DAN
- 차별성이 있는 영역을 결정하는데 셀프 어텐션 구조 내의 어텐션 맵의 strength를 사용한다. e.g., TransFG, FFVT
처음 2개의 접근법은 (CNN)convolutional nerual network을 기반으로 하고 (such as ResNet, DenseNet, EfficientNet) 3번째 접근법은 ViT를 기반으로 한다.
어찌됐던 영역을 찾으면, 원본 이미지와 특징 맵을 crop하거나 resize해서 네트워크에 다시 입력으로 넣을 수도 있고
어텐션 구조를 사용하여 특징맵간의 관계를 강화할 수 있다.
위 접근법들의 단점은 대부분 2개 이상의 stage 즉, multi-sage complex architecture를 필요로 하고 end-to-end 학습이 불가능 하다는 것
게다가 이렇게 영역을 구하는 방법들이 미세하고 지역적인 특징을 찾기 보다는 큰 영역을 찾아낸다는 점이다.
반면 ViT 기반의 방법은 셀프어텐션 구조의 어텐션맵을 영역을 선택하는 기준으로 사용한다.
avoid the feedback-based architecture and achieving effecient end-to-end training
하지만 이 방법은 CNN이나 다른 구조에 일반화하기 어려워 scalability가 제한적이라 할 수 있다.
특징맵과 객체의 위치 관계를 더 이해하기 위해선 객체탐지모델과 FGVC 방법간의 관계를 살펴보았다.
Faster-RCNN, YOLO, RetinaNet에선 특징맵에 위치와 카테고리에 대한 정보가 풍부하게 있다는 점을 발견
Mask-RCNN와 같은 분할 메소드는 픽셀 단위로 예측을 한다. 즉, fine-grained predictions임
위 방법들은 특징맵에 의미론적인 정보가 풍부함을 보여주지만 결국 사람이 표시한 영역에 의존하여 학습한다.
image-level annotation만을 훈련에 사용하는 FGVC 와는 다르다.
따라서 본 연구진은 Weakly Supervised Object Detection(WSOD)방법 (e.g., WSDDN, OICR, WCCN)을 사용한다.
WSOD 방법의 컨셉은 특징맵의 response가 객체의 위치를 반영한다는 것이고 이 특징맵을 활용하여 weakly suprvised multi-stage 구조와 손실함수를 설계하여 완벽한 바운딩박스를 예측할 수 있다.
plug-in module을 제안하는데 이는 여러 일반적인 백본모델(CNN/Transformer 기반)에 추가될 수 있다.
게다가 output은 pixel-level 특징맵이며 필터링된 특징들을 융합한다.
다양한 크기의 주요 특징들을 잘 찾아내기 위해서 백본 네트워크에 FPN(Feature Pyramid Network)를 추가하여 각기 다른 크기의 공간적인 특징들을 mix하였다.
이 구조는 객체탐지 작업에서는 일반적이며, 이런 접근법으로 인해 local 표현의 퀄리티가 개선될 수 있다.
Plugin module의 개념은 'division', 'competition', 'combination'의 3가지가 있다.
그림 2에서처럼 배경을 잘라서 얻은 패치는 대부분 단색이며, 이런 패치들은 각기 다른 카테고리 데이터 내에서도 자주 등장할 것이다.
이 패치를 훈련에 쓴다면, 테스트 이미지에 대한 예측 분포는 평평하게 나올 것이다.
반면, 확실히 구별되는 물체가 있는 패치를 훈련에 쓴다면, 예측 결과도 좀 더 구분될 것이다.
거의 동일한 훈련이미지인데 라벨이 다르게 지정되면 역전파 시 샘플공간에 수렴하기 어려워진다.
따라서, 예측된 클래스 점수를 사용하여 특징맵을 object candidate region, background candidate region으로 나눌 수 있다는 아이디어가 생김.
각기 다른 스케일의 분할된 객체 특징들은 융합되어 분류예측에 사용되는 반면, 배경영역의 correction은 평평한 확률분포를 목적으로 한다.
이런식으로 하면 배경 노이즈를 없애고 중요한 영역에 집중할 수 있다.
Two main contributions
Novel plug-in 네트워크를 제안하여 다양한 모델에서 사용될 수 있도록 한다. 이 네트워크는 새로운 배경분할과 특징융합 기술을 포함하여 fine-grained 이미지 인식 성능을 효율적으로 개선할 수 있다.
제안된 네트워크는 SOTA를 뛰어넘었고 CUB200-2011, NABirds 데이터셋에 대해 92.77%(+0.97%), 92.83%(+1/83%)의 정확도를 달성하였다.
Related Work
관련연구는 중요한 부분만 진짜 짤막하게 정리하고 스킵.
<Backbone>
SwinTransformer는 멀티레이어 셀프어텐션 구조를 통해 각기 다른 스케일의 local 영역의 특징을 추출해낸다.
위 구조가 성공적이었기 때문에, 제안된 모듈의 capability를 시험하기 위해 해당 모델을 백본모델로 사용하였다.
<Object detection>
객체 탐지의 목표는 위치를 찾고 그 위치의 물체를 분류한다는 점에서 전반적인 구조와 아이디어는 fine-grained 이미지 분류 작업과 유사하다.
다른 점은 fine-grained 이미지 분류 작업은 물체가 어디있는지 그 영역을 찾는 것이 아니라, 구분되는 특징이 있는 영역이 어디있는지를 찾고 그 영역이 효율적으로 인식에서 사용되느냐이다.
훈련단계에서 네트워크는 물체가 있는 영역을 찾는데 초점을 둔 후, 해당 영역에 대해 분류 예측을 실행한다.
전체 프로세서는 FGVC에 제안된 방법과 유사하다.
하지만 FGCD는 물체가 있는 그 영역에 대한 위치정보를 훈련데이터로 사용하지 않는다.
그 대신, 수동으로 annotation할 필요 없도록 객체 탐지의 weakly suprvised learning method로 확장한다.
<Weakly supervised object detection>
Weakly Supervised Object Detection(WSOD)는 심층 신경망을 통해 나온 유의미한 특징맵에 의존
클래스 라벨 객체를 학습하는 과정에서 공간 내 객체의 표현도 학습될 수 있다는 것을 발견함
여러 알고리즘이 있는데, 논문에서 멘션된 알고리즘들은 카테고리 라벨이 객체의 위치에서 풍부한 특징을 제공하고 클래스를 구분할 수 있는 영역을 찾을 수 있다는 점을 보여준다.
하지만, WSOD 작업은 여전히 FGVC와 똑같다고 할 수 없다.
FGVD의 목표는 완전한 객체를 감지하는 것이 아니라, 가장 중요한 영역을 찾고 이 영역을 활용해서 인식 성능을 높이는 데에 있다.
<Fine-grained visual classification>
FGVC의 주 목표는 가장 차별점이 있는 영역을 찾아내는 것
어텐션 구조는 전반적으로 FGVC에서도 쓰인다.
MACN, WS-DAN, CAL에서 처럼 어텐션맵을 사용하여 객체의 위치를 학습하고 특징맵내의 특정 위치의 특성을 추출한다.
어텐션 구조는 위치정보를 학습하는 것 외에도 특징의 표현력을 향상시킬 수 있다.
Vision Transformer의 등장 이후에 이미지 인식 분야에서 ViT가 꽤 잘 수행되었다.
FGVC에서 많은 부분들이 이 구조를 따라 적용되었다.
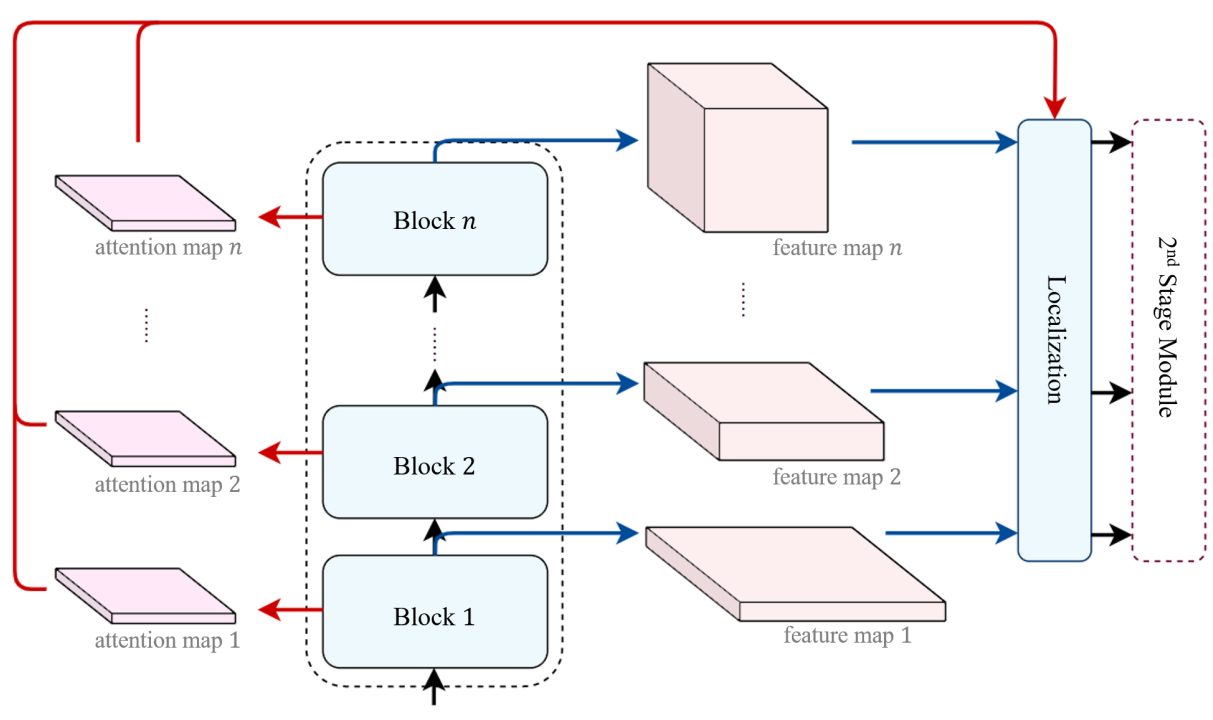
논문에 언급된 모델들은 앞서 언급된 컨볼루션 네트워크와 유사한데 차이점은 그림 3의 왼쪽 부분에서처럼, 특징맵의 response대신 어텐션 맵의 strength가 사용된다.
A NOVEL PLUG-IN MODULE FOR FINE-GRAINED VISUAL CLASIFICATION
fine-grained 분류 작업에서 강한 차별성이 있는 영역들을 찾기 위해서, plug-in 모듈을 제안하여 주요 백본 네트워크들에 적용될 수 있도록 한다.
ResNet, EfficientNet, ViT...
전체적인 컨셉은 특징 맵에서의 각 픽셀(or 패치)을 각각의 독립적인 특징으로 간주하여 그것의 영역을 표현하도록 한다.
그 뒤, 특징들을 분류하고 분류 능력을 구별하는 근거로써 사용한다.
마지막으로 네트워크 전체가 end-to-end 학습이 가능하도록 한다.
<Module design>
FGVC와 WSOD 방법의 공통점은 다른것들과 강하게 구별되는 영역을 찾는 것
FGVC에서는 이 영역을 잘라내거나 2차 훈련 단계에서 어텐션을 증가시킨다.
반면 WSOD에서는 정확한 localization을 위해서 종종 MIL(multiple instance learning)을 사용한다.
위 두 작업은 타겟을 지정하는데 있어서 살짝 다르지만 두 구조 모두 특징맵의 픽셀단위 특징이 분류단계에서 해당 영역의 중요도를 표현할 수 있다는 것을 보여준다.
앞으로는 특징맵의 픽셀 값을 특징점(feature point)이라고 지칭한다.
특징점의 차원은 Rc (c는 해당 블록의 출력 특징의 차원 크기)
단순한 디자인을 채택하였다. 바로 어떤거나면...! 두근두근..
완전연결층을 통해 각 특징점을 전달하여 카테고리를 예측하는 것이다.
소프트맥스를 거친 예측 결과에서 가장 높은 확률이 특정 값보다 크게 된다면, 특징점이 유일한 특징이라고 간주되고 이 후 융합된다. 거꾸로, 특징점은 fine-grained 분류에서는 덜 유용한 것으로 여겨진다.
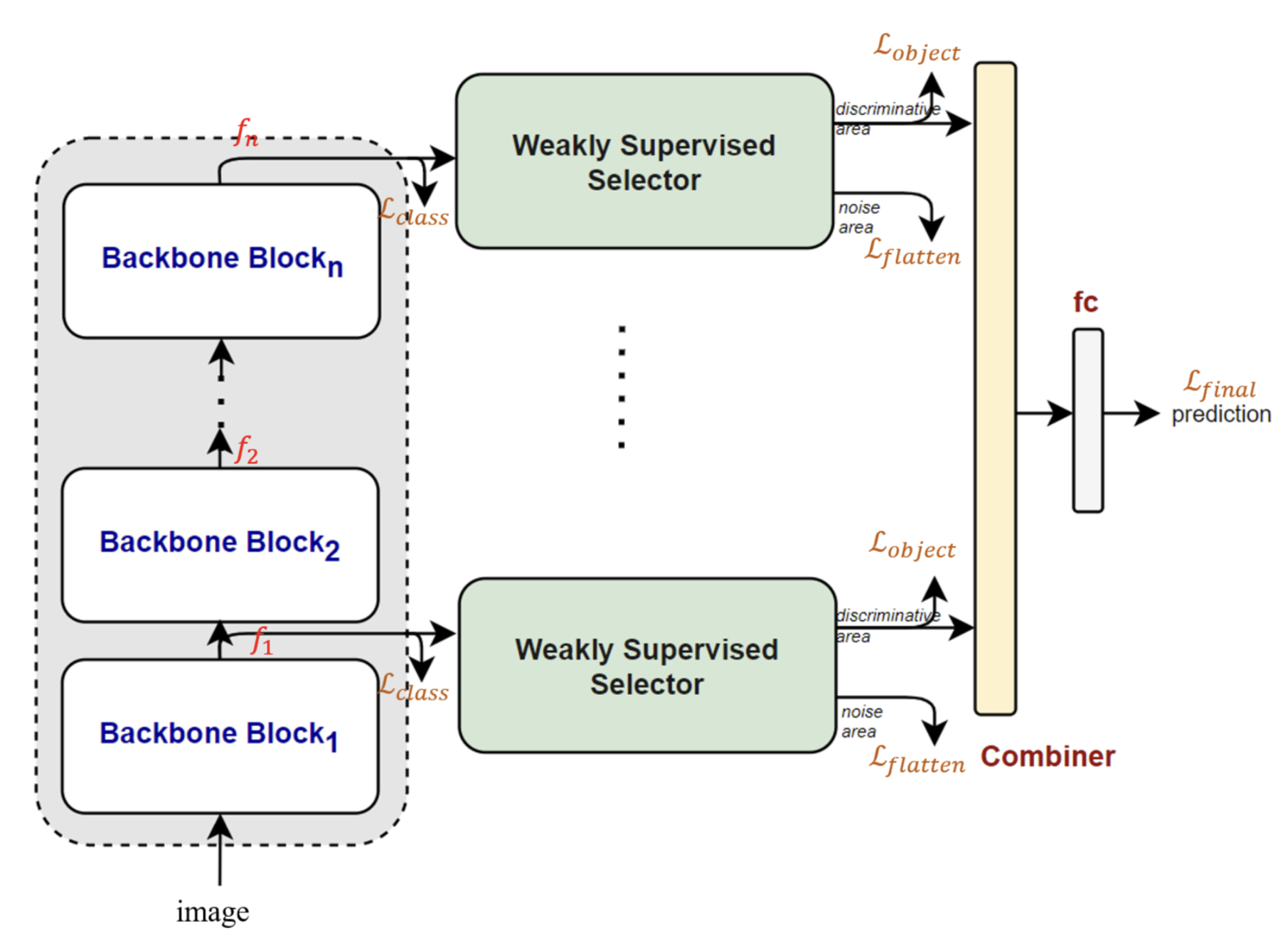
위 개념을 기반으로 본 연구진은 end-to-end로 학습될 수 있도록 구조를 설계하였다. (그림 4)
점선으로 되어있는 영역은 백본으로 사용되는 모델
fi∈RC×H×W는 백본 네트워크의 i번째 블록의 특징맵 출력을 표현한다
H 특징 맵의 높이
W 특징 맵의 너비
C 특징 차원의 크기
이 특징맵은 weakly supervised selector에 제공되고 각 특징점은 선형 분류기에 의해 분류된다.
이 단계 이후 특징맵은 fi∈RC′×H×W로 표시
C′ 타겟 클래스 수
각 특징점에 대한 클래스 예측 확률이 소프트맥스를 통해 얻어지면, 가장 높은 점수를 얻은 처음 몇개가 weakly supervised selector에 의해 선택될 것

선택하는 알고리즘은 Algorithm 1에서 볼 수 있고 선택된 특징들은 융합모델 (그림4에 표기)에 의해 합쳐진다.
특징 융합을 완성하기 위해 2개의 다른 구조를 설계함
첫번째는 완전연결층으로 구현되었다.
선택된 특징점의 개수를 N이라 하자.
특징맵들이 완전연결층의 입력으로 들어가기 전에, 특징 차원에 대해 먼저 concatenate된다.
따라서, 완전연결층을 거치면 RN×C차원의 특징맵이 R^C'차원의 예측결과를 생성해냄
이 구조는 선택된 로컬 특징들을 전체 이미지를 표현하는 글로벌 특징으로 재결합할 수 있다.
두번째 구조는 선택된 ㅁ든 특징점들을 graph structure로 사용하는 그래프 컨볼루션으로 구현되었다.
노드는 여러 공간적 위치와 크기를 가진 특징을 표현한다.
그래프는 그래프 컨볼루션 네트워크의 입력으로 들어가 각기 다른 노드에 대한 관계를 학습하고, 이후 특징점들이 풀링층을 거쳐 여러개의 슈퍼 노드로 합쳐지게 되면 최종적으로 슈퍼 노드의 특징들의 평균을 계산하고 선형분류기로 예측을 수행한다.
이 접근법의 장점은 각 위치의 특징들이 백본 모델의 출력 결과를 손상시키지 않고 효율적으로 합쳐질 수 있다는 것
따라서, 본 연구직은 그래프 컨볼루션을 특징 융합 메커니즘으로 사용하였다.
모델이 작은 영역에 대한 특징을 효율적으로 추출하게 하기 위해 백본 네트워크에 FPN 를 추가하여 다른 스케일의 특징을 더 효율적으로 융합할 수 있게 하여 더 정확하게 인식할 수 있도록 하였다.
<The process of forward and backward propogation>
이 구조의 목표는 fine-grained 분류를 수행하는 것
따라서 image-level annotation외에 다른 어떤 인공라벨도 훈련 데이터로 사용하지 않음
첫번째 훈련 목표는 각 특징맵 fi의 특징들이 분류 능력을 가지도록 하는 것이다.
전반적인 손실을 계산하기 위해 먼저 전체 특징점의 예측결과를 평균한다. (식 1)
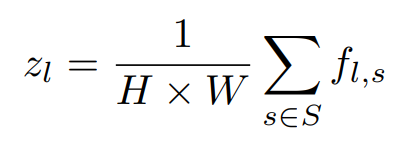
이때, fl,s∈RC′는 l번째 특징맵 블록에서 s위치의 특징점을 나타낸다.
S는 블록의 출력 특징맵 공간을 의미하며, 크기는 H×W
전체 블록에 대한 클래스 손실은 Cross Entropy를 통해 구한다 (식 2)
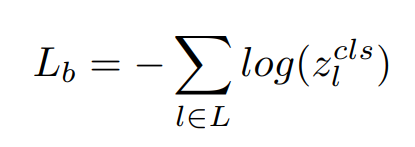
전반적으로 분류를 훈련하는 것 외에도 특징맵은 Masi∈RH×W에 의해 마크된다.
Mask는 이진 데이터이며 1은 선택된 영역을 표기하고 0은 버려진 영역을 표기한다.
이제 S⨀(Mask)는 강하게 구별되는 특징점들을 나타내고 S⨀( Mask)는 drop된
특징점을 나타낸다.
식 3은 i번째 블록에서 선택된 영역의 합을 나타낸다.
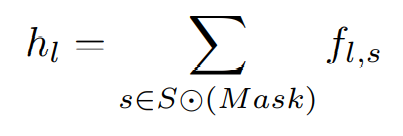
선택된 카테고리에 대한 손실함수는 Ls이며 식 4로 정의한다.
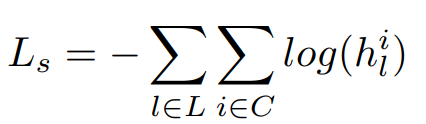
식 5는 선택되지 않은 (또는 배경으로 선택된) 특징의 합을 표현한다.
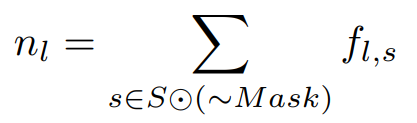
drop된 영역에 대한 flattening 손실 함수는 Ln (식 6)
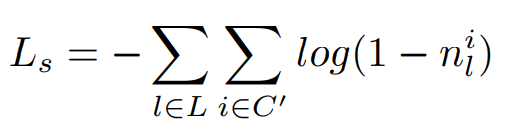
바로 Ln을 구하지 않고 Ls로 표기 하기 위해서 nil를 그대로 안쓰고 1에서 빼서 사용하는듯,,,
함정인가?.............사실 밑에서도 오타가 있는것 같아서 오타인지 뭔지 모르겟따
아무튼 flattened output은 해당 영역이 분류에 도움이 되지 않는다는 것을 표현하기 위해 설계되었다.
이런 접근법은 detection framework에서 순전파와 역전파 시 "score"을 구하는 것과 유사하다.
본 논문에선, 소프트맥스를 거친 가장 높은 확률값을 점수로 사용한다.
이제 선택 영역 fs∈RN×C가 Combiner에 입력으로 들어가서 다양한 스케일의 출력 결과를 생성해낼 것이다.
출력 차원은 fcomb∈RN′×C으로 이 때, N′은 입력노드를 고려한 슈퍼 노드의 수
최종적으로 슈퍼 노드의 특징들의 평균을 구하고 선형분류기의 입력으로 들어가 예측값을 출력한다.
Combiner category prediction loss는 Cross entropy를 통해 구해지며 이 손실함수는 Lc로 표현
전체 손실 함수는 식7처럼 표기한다.
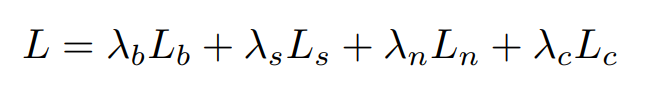
이때, λb,λs,λn,λc는 각각 Lb,Ls,Ln,Lc의 가중치이다.
실험에서는 이 값을 각각 λb=1,λs=0,λn=5,λc=1로 사용하였다.
논문에서는 값을 할당한게 λ가 아니라 L이었지만
lambda가 가중치라는 점에서도 그렇고, 이후에 설명을 보니 λ같아서 이렇게 정리함
오타있는걸 보면 논문에서 잘못 쓴게 맞는 거 같음
아무튼 λs=0이라는 의미는 selected category loss function Ls를 사용하지 않았다는 건데,
Cambiner category를 거친 예측 손실 Lc안에 이미 같은 함수가 존재하기 때문이다.
전체 훈련 목표는 강한 차별성이 있는 로컬 영역을 찾고 그 영역의 특징을 이용하여 인식 결과를 개선하는 것
차별성 있는 local location (or 객체의 위치)을 찾는 것이 히트맵이라고 불리는 특징맵의 반응값에 의해서 라는 점을 제외하면 이전의 WSOD, FGVC 프레임워크의 기능과 매우 유사하다.
이런 접근(WSOD, FGVC)의 단점은, 히트맵을 얻기 위해 많은 알고리즘을 필요로 하고 모델을 수정하기 위해 two-stage 접근이 필요하다는 것이다.
본 논문에선 주로 로컬 특징을 이용해서 클래스를 예측하는 간단하고, 구현하기 쉬운 방법을 제안하였다.
이로인해 로컬 배경 영역이나 타 클래스에서 지역적으로 유사한 부분을 구별하기 어려워진다.
이 경우에 가장 강력한 선택 기준은 예측 확률의 최댓값이 된다.
마지막으로, 선택된 로컬 특징이 글로벌 특징과 융합되어 최종 예측을 수행하는데, 이 방법은 다양한 주류 백본 네트워크에 사용할 수 있고 end-to-end 훈련이기 때문에 단 하나의 stage만을 필요로 한다.
대조학습은 FGVC 작업에서 많이 사용된다. FGVC 모델에서 대조학습은 중요한 역할을 한다.
하지만 대조학습을 통해 모델을 훈련하면 margin distance, temperature, ... 와 같은 추가적인 파라미터를 필요로 하게 됨
가능한 훈련과정을 단순하게 만들기 위해, 해당 설계에서는 대조학습은 사용하지 않고 Cross Entropy만을 이용한다.