

탐색
이제 데이터를 수집하는 것은 끝이 났다.
지금부터는 이 데이터를 가공하는 작업이다.
사실 이 데이터 전처리가 제일 중요하지만, 제일 귀찮고 번거롭다. 암튼 또 시작 ㅠㅠ
이번 단계에서 사용할 패키지는 다음과 같다.
#import할 패키지 목록
import re
import pandas as pd
from tqdm import tqdm
from konlpy.tag import Okt
from pykospacing import Spacing
from collections import Counter
일단, 이전에 만들어놓은 함수들을 사용해서 다시 데이터프레임을 생성해보자.
url = search()
data = crawl_review(url)
data = save_and_load(data)
좋다. 아주 잘 되는 것 같다. 뿌듯하다.
전처리를 시작하기 전에 맛보기로 데이터를 분석해보자. (별거없음)
print("주토피아 영화의 평균 평점은 {:.2f}".format(data['Rank'].mean()))예상대로 높다. 데이터를 보면 죄다 9점, 10점이었는데 그래서그런지 역시 평점이 높다.
feeling = [0 if rank in range(0,6) else 1 for rank in data['Rank']]
pos_cnt = len([x for x in feeling if x==1])
neg_cnt = len([x for x in feeling if x==0])
print(("긍정비율 : {:.4f}%,".format(pos_cnt/len(feeling))+" 긍정개수 : {}개".format(pos_cnt)))
print(("부정비율 : {:.4f}%,".format(neg_cnt/len(feeling))+" 부정개수 : {}개".format(neg_cnt)))10점까지 있는데, 긍정/부정을 실제로 모델을 학습시켜서 분리하기 전에 임의로 네티즌들이 부여한 평점에서
0~5점을 부정, 6~10점을 긍정이라고 간주하고 데이터를 분류해보았는데 긍정비율이 압도적으로 많았다.
data.isnull().sum()별점을 등록할때 아무런 리뷰도 쓰지 않고 점수만 기재한 경우이다.
전체 17000여개 중에 68개면 제거해도 영향을 주지 않을 것이다.
data = data.dropna()
data.isna().sum()
이제 null값들은 다 처리를 해주었고, 중복행이 있는지 살펴보자.
data.duplicated().sum()
실제 데이터들을 보니 겹치는 것끼리 인덱스가 꽤 멀어서 우연일 수도 있겠다 싶다.
그래서 제거할까 말까 했는데 이도 역시 62개밖에 안되서, 딱히 지워도 영향을 주진 않을 것이다.
쳐내자.
data = data.drop_duplicates()
data.duplicated().sum()
데이터들을 쳐낸 것이 좀 있으니 인덱스를 재배열해주도록 하자. 이후에 전처리하는 과정에서 KeyError가 발생할 수 있다.
data = data.reset_index(drop=True)전처리
대충 훑어봤으니 본격적으로 전처리를 시작해보자.
사람들이 리뷰를 쓸 때, 딱히 맞춤법/띄어쓰기를 생각하지 않고 쓰는 경우가 많다. 우리는 그렇게 쓰여있어도 다 이해하기 때문이다. 하지만 이를 가지고 컴퓨터가 이해하게 만들어야하므로 전처리 과정이 필요하다. 실제 야생의(?) 환경에서 긁어온 데이터들은 굉장히 지저분하고 깔끔하지 못하다. 일단 신조어도 많고, 발음대로 적힌 것도 많으니까.
일단 내가 하려는 과정은 다음과 같다.
1. 리뷰에서 영어표현, puncation, 이모티콘은 모두 제거한다. (=한글 표현만 남긴다)
2. 띄어쓰기 변환기를 통해 띄어쓰기가 되어있지 않은 문장들을 제대로 변환한다.
3. 형태소 분석기를 통해 각각의 리뷰를 형태소 단위로 분리한다.
4. 한글자로 되어있는 것 제거
5. 빈도수가 많은 순으로 정렬 후 의미없는 단어(불용어) 제거
6. 최소빈도수 이하의 것들은 제거한다.
7. 잘못 분리 된 의미있는 단어들을 찾아서 사용자 단어 사전에 추가 (ex. 디테일 => 디 + 테일로 분리됨)갈길이 멀다..차근차근 해보자ㅠㅠ
< 한글 표현만 남기기 >
정규표현식을 통해 한글 단어만 남기고 모두 제외할 것이다.
def extract_word(text):
hangul = re.compile('[^가-힣]')
result = hangul.sub(' ', text)
return result
특정 리뷰를 통해 전과 후를 비교해보자
print("Before Extraction : ",data['Review'][658])
print("After Extraction : ", extract_word(data['Review'][658]))
print("Before Extraction : ",data['Review'][7894])
print("After Extraction : ", extract_word(data['Review'][7894]))의미없는 기호, 이모티콘, 초성, 영어들이 제거되어 조금 더 깔끔해진 것 같다.
data['Review'] = data['Review'].apply(lambda x:extract_word(x))전체 데이터에 대해 extract_word를 적용하였다.
< 띄어쓰기 고치기 >
이 부분은 우리 팀원중에 한 명이 소개해준 pykospacing 모델을 사용할 것이다.
10) 한국어 전처리 패키지(Text Preprocessing Tools for Korean Text) - 딥 러닝을 이용한 자연어 처리 입문 (wikidocs.net) 여기를 참고하면 좋을 것 같다.
spacing = Spacing()
print("Before Fixing : ",data['Review'][7894])
print("After Fixing : ", spacing(data['Review'][7894]))
print("Before Fixing : ",data['Review'][14454])
print("After Fixing : ", spacing(data['Review'][14454]))정규표현식으로 띄어쓰기가 많이 된 부분도 조정이 되었고, 원래 잘 되어있지 않은 문장들도 깔끔해졌다.
다만 kospacing을 전체데이터셋에 적용하는 부분에선 시간이 좀 걸린다.
13분 걸렸다... 지루해죽는줄 ㅠ
그런데 문제가 있다.
spacing = Spacing()
spacing("나무늘보가 젤 귀여워")이렇게 의미있는 단어인데 잘못 띄어쓰기 되는 경우도 있다.
그래서 일단은 스킵하고 진행하기로 했다. (추후에 얘기해볼 예정)
< 형태소 분석 >
여러 분석기가 있는데 일단은 가장 기본적인 Okt모델을 사용하려고 한다.
mecab이 빠르고 좋다고 했는데, 내 실력부족인지 윈도우환경에서는 사용자단어를 추가하는게 너무 힘들었다.
okt = Okt()
words = " ".join(data['Review'].tolist())
words = okt.morphs(words,stem=True)
일단은 형태소 단위로 분리해서 count를 세는게 목적이므로 리뷰 하나하나마다 하기보다는 여러 리뷰들을 하나의 리스트 원소로 합쳐서 형태소를 분리한 뒤 Counter 객체로 빈도수를 보려 한다.
17000여개의 리뷰들을 형태소 별로 쪼개니 정말 많았다. 개수를 출력해 보니 211445개가 나왔다.
사실 이렇게 많은 단어들이 모두 의미있는 것은 아니다.
< 한 글자, 불용어 제거 >
리스트들을 쭈욱 훑어보니, 한 글자인 것들은 주로 조사가 많았고 그렇지 않아도 대체로 의미없는 단어들이었다.
그 중 '닉'은 한글자지만 중요한 의미이기 때문에 냅뒀다.
remove_one_word = [x for x in words if len(x)>1 or x=="닉"]
len(remove_one_word)개수가 확연히 줄어든 것을 확인하였다.
collections의 Counter객체를 이용하여 단어별 빈도를 확인해보았다.
from collections import Counter
frequent = Counter(remove_one_word).most_common()빈도수 위주로 출력하였는데, 의미없는 단어(불용어)가 많았다.
'하다', '너무', '있다', '이다' 이런 것들은 불용어리스트로 정의해 쳐내야 한다.
그래도 이것만 보더라도 닉의 인기를 체감할 수 있었다 ㅎ
우리의 최종 목표는 키워드 추출이다. 결국 결과물이 n개의 키워드일텐데 최대한 불용어가 검출되지 않도록 사전작업이 필요하다.
일단 기본 불용어는 https://raw.githubusercontent.com/yoonkt200/FastCampusDataset/master/korean_stopwords.txt에 있는 자료로 사용하고, frequent를 살펴보면서 불용어리스트를 추가하였다.
이 파일을 추가해서 새로운 불용어리스트로 사용하자.
with open('data/stopwords.txt', 'r') as f:
list_file = f.readlines()
stopwords = list_file[0].split(",")
remove_stopwords = [x for x in remove_one_word if x not in stopwords]
len(remove_stopwords)이번에도 수치가 확연하게 차이가 나는 게 보인다.
그럼 불용어를 제거했으니 다시 counter객체로 빈도수를 확인해봐야겠다.
Counter(remove_stopwords).most_common()확실히 아까보다 훨씬 더 의미있는 단어들이 남았고, 사람들이 어떤 부분에서, 어떤 감정을 느꼈는지 명확해졌다.
< 최소 횟수 이하 단어 제거 >
for item, count in Counter(remove_stopwords).most_common():
if count==1:
print(item)거꾸로, 가장 빈도수가 적은 단어들을 출력해보았다.
확실히, 맞춤법에 어긋나거나 띄어쓰기가 잘못되어있는 경우가 많다.
리뷰들 중에선 맞춤법이나, 띄어쓰기가 잘못 되어있는 게 많은데, 그런 것들이 겹칠 확률은 적다.
따라서 빈도수도 적게 나올것이고, 낮은 빈도수의 값들을 쳐내면 어느정도는 자연스럽게 처리가 될 것이다.
minimum_count = 3
more_than_one_time= []
for i in tqdm(range(len(remove_stopwords))):
tmp = remove_stopwords[i]
if remove_stopwords.count(tmp) >= minimum_count:
more_than_one_time.append(tmp)위의 코드처럼 나는 일단 최소횟수를 3회로 정했다.
위의 for문은 O(n^2)연산이므로 시간이 좀 오래걸릴것이다.
리스트컴프리헨션을 쓰면 시간이 단축될수도 있겠는데 난 기약없이 기다리는거 못해서
tqdm으로 진행상황을 보려고 구현했다.
<konlpy에 사용자 단어 추가>
마지막으로 정보가 없어서 잘못 분리된 단어를 제대로 분리하도록 konlpy 사전에 추가하는 작업이다.
러닝타임 => '러닝', '타임'
디테일 => '디','테일'
귀여움 => '귀', '여', '움'
강추하다 => '강', '추하다'
특히 강추하다 같은 경우는 '강', '추하다' 로 분리되는데, 빈도가 꽤 높다.
'강'은 한글자라 버려지기 때문에 '추하다'만 남아서, 의미가 잘못 전해질 수 있다.
나는 앞서 말했듯, 윈도우 운영체제로 anaconda 가상환경을 통해 jupyter notebook으로 작업하고 있다.
colab으로도 konlpy사전에 단어를 추가할 수 있다고 한다.
꽤 귀찮은 작업이다ㅠㅠ
[Python] KoNLPy 사용자 사전 추가 - Eraser’s StudyLog (sirzzang.github.io)
이 게시물은 코랩환경에서 작업한건데, 나는 여기를 참조해서 주피터노트북으로 작업했다.
일단 내가 사용하고 있는 anaconda 가상환경의 경로를 알아야 한다.
anaconda prompt 창을 열어 가장 먼저 나오는 경로를 찾으면 된다.
해당 경로에서 anaconda 폴더를 찾고 envs로 들어간다.

envs에서 내가 사용중인 가상환경폴더로 들어간다. 그러면 다음과 같이 보일 것이다.
이제 여기서 konlpy폴더를 찾아야 하는데 그냥 검색창에 konlpy 입력해서 나오는 폴더를 찾으면 된다.
위 사진처럼 보인다면 성공이다.
이제 java폴더에서 open-korean-text-2.1.0압축파일을 해제한다.
압축해제한 폴더에서 org > openkoreantext > processor > util 을 찾는다.
일단 명사부터 수정하기 위해 noun을 들어가 후 원하는 파일을 연다.
나는 일단 이렇게 추가했다.
그리고 귀여움의 경우는 형태소가 어떻게 구성되는지 몰라서
util > typos > typos.txt에서
이렇게 추가했다. 이제 아까 압축해제했던 폴더를 다시 jar로 압축해야되는데
윈도우에서는 그냥 압축이안되고 cmd명령어로 해야된다.
근데이게 내 java 버전에서는 안되서 일단 그냥 zip파일로 압축한다.
이제 원래 있던 open-korean-text-2.1.0 파일을 버리고 zip파일을 jar로 변환하면 된다.
ZIP JAR 변환 (온라인 무료) — Convertio << 여기 사이트에서 zip파일을 업로드하면 변환해준다.
변환한 파일로 zip파일을 대체하고 다시 주피터노트북으로 돌아간다.
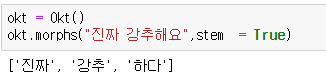

대충 테스트 해보니 잘 된 것 같다.
그럼 이제 이때까지 한 작업을 함수화하면 끝이다.
1. 전체 리뷰를 하나로 연결해 일정개수 이상의 단어들의 리스트를 만드는 함수
2. 하나의 리뷰를 전처리하는 함수 (이후에 리뷰들을 벡터화할때 쓰인다)
#이전의 save_and_load를 다음과 같이 수정
def save_and_load(dataframe):
basepath = 'data/'
dataframe.to_csv(basepath+'주토피아review.csv' , index= False)
df = pd.read_csv(basepath+'주토피아review.csv')
df = df.dropna()
df = df.drop_duplicates()
df = df.reset_index(drop=True)
return dfdef load_stopwords():
with open('data/stopwords.txt', 'r') as f:
list_file = f.readlines()
return list_file[0].split(",")def extract_word(text):
hangul = re.compile('[^가-힣]')
result = hangul.sub(' ', text)
return resultdef make_wordlist(reviews,stopwords): #reviews = " ".join(data['Review'].tolist())
print("리뷰들을 모아 분석하는 중입니다.....")
#정규표현식 적용
print("데이터 정제 중....")
words = extract_word(reviews)
#형태소 추출
print("형태소 추출 중....")
words = okt.morphs(words,stem=True)
#한글자 제거
print("한글자 제거 중....")
words = [x for x in words if len(x)>1 or x =='닉']
#불용어 제거
print("불용어 제거 중....")
words = [x for x in remove_one_word if x not in stopwords]
#최소횟수 미만 제거
print("의미있는 단어리스트 생성 중....")
time.sleep(1)
minimum_count = 3
final = []
for i in tqdm(range(len(words))):
tmp = words[i]
if words.count(tmp) >= minimum_count:
final.append(tmp)
return set(final) #조건을 만족하는 단어 리스트def preprocess(text, word_list):
text = extract_word(text)
okt = Okt()
text = okt.morphs(text, stem = True)
text = [x for x in text if x in word_list]
return text
<테스트>


(기존 data는 아까 정규표현식 써본다고 데이터프레임에 적용해서, 한글만 남은 상태였음)
완전히 clean하진 않지만 아무튼 성공
전체코드는 여기 Click!!
이때까지 진행했던 모든 작업을 클래스화 하였다.
def no_space(text):
text1 = re.sub(' | |\n|\t|\r', '', text)
text2 = re.sub('\n\n','', text1)
return text2
def extract_word(text):
hangul = re.compile('[^가-힣]')
result = hangul.sub(' ', text)
return result
def load_stopwords():
with open('data/stopwords.txt', 'r') as f:
list_file = f.readlines()
return list_file[0].split(",")
class Review_keyword:
def __init__(self, minimum_count:int)->None:
self.minimum_count = minimum_count
self.word_list = None
self.name = None
self.url = None
self.data = None
self.stopwords = load_stopwords()
def search(self) :
self.name= input("어떤 영화를 검색하시겠습니까? ")
url = f'https://movie.naver.com/movie/search/result.naver?query={self.name}§ion=all&ie=utf8'
res = requests.get(url)
index = 1
user_dic = {}
if res.status_code == 200:
soup=BeautifulSoup(res.text,'lxml')
for href in soup.find("ul", class_="search_list_1").find_all("li"):
print(f"=============={index}번 영화===============")
print(href.dl.text[:-2])
user_dic[index] = int(href.dl.dt.a['href'][30:])
index = index+1
movie_num = int(input("몇 번 영화를 선택하시겠습니까? (숫자만 입력) : "))
code = user_dic[movie_num]
base_url = f'https://movie.naver.com/movie/bi/mi/pointWriteFormList.nhn?code={code}&type=after&onlyActualPointYn=N&onlySpoilerPointYn=N&order=sympathyScore&page='
self.url = base_url+'{}'
def save_and_load(self,dataframe):
basepath = input("csv파일을 저장할 기본 경로를 입력해주세요")
dataframe.to_csv(basepath+f'{self.name}review.csv' , index= False)
df = pd.read_csv(basepath+f'{self.name}review.csv')
df = df.dropna()
df = df.drop_duplicates()
df = df.reset_index(drop=True)
return df
def crawl_review(self):
res = requests.get(self.url)
if res.status_code == 200:
soup=BeautifulSoup(res.text,'lxml')
total = soup.select('div.score_total > strong > em')[0].text
pages = int(total.replace(',','')[:-1]) #17,921 > 17921로 변환 후 캐스팅
print()
print(f"{pages}개의 페이지에서 {self.name} 영화 리뷰를 모으고 있습니다.")
time.sleep(1)
comments = []
stars = []
for page in tqdm(range(1,pages+1)):
url = self.url.format(page)
res = requests.get(url)
if res.status_code == 200:
soup=BeautifulSoup(res.text,'lxml')
star = soup.select('div.score_result > ul > li > div.star_score > em')
tds = soup.select('div.score_result > ul > li > div.score_reple > p > span')
for st in star:
stars.append(int(st.text))
for cmt in tds:
if cmt.text != '관람객' and cmt.text !='스포일러가 포함된 감상평입니다. 감상평 보기':
comments.append(no_space(cmt.text))
if(len(comments) != len(stars)):
print(url)
break
assert len(comments) == len(stars)
self.data = self.save_and_load(pd.DataFrame({"Review":comments, "Rank":stars}))
def make_wordlist(self,reviews): #reviews = " ".join(data['Review'].tolist())
print("리뷰들을 모아 분석하는 중입니다.....")
#정규표현식 적용
print("데이터 정제 중....")
words = extract_word(reviews)
#형태소 추출
print("형태소 추출 중....")
okt = Okt()
words = okt.morphs(words,stem=True)
#한글자 제거
print("한글자 제거 중....")
words = [x for x in words if len(x)>1 or x =='닉']
#불용어 제거
print("불용어 제거 중....")
words = [x for x in words if x not in self.stopwords]
#최소횟수 미만 제거
print("의미있는 단어리스트 생성 중....")
time.sleep(1)
minimum_count = 3
final = []
for i in tqdm(range(len(words))):
tmp = words[i]
if words.count(tmp) >= minimum_count:
final.append(tmp)
self.word_list = set(final) #조건을 만족하는 단어 리스트
def preprocess(self,text):
text = extract_word(text)
okt = Okt()
text = okt.morphs(text, stem = True)
text = [x for x in text if x in self.word_list]
return " ".join(text)
def clean_dataset(self):
self.search()
self.crawl_review()
self.make_wordlist(" ".join(self.data['Review'].tolist()))