

그래..시작하자..
일단 영화 리뷰를 크롤링 하기전에 url을 살펴보았다.
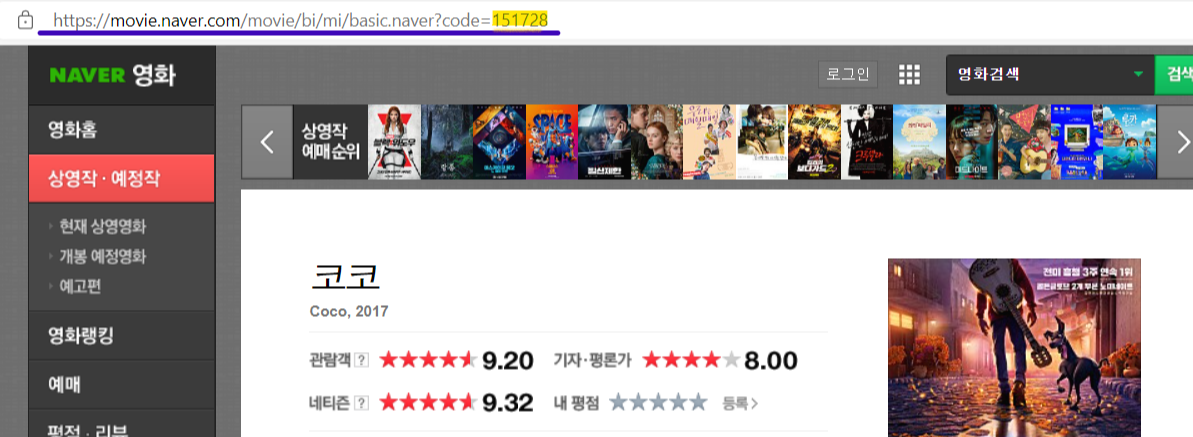
영화마다 고유 code를 갖고 있고 이거를 조합해서 영화페이지에 접근한다.
영화코드 데이터셋이 있으면 좋겠지만 없으니 사용자가 원하는 영화키워드로 검색을 시도하고
검색결과를 크롤링해 결과리스트에 href속성에있는 주소에서 code를 추출하기로 했다.
그러면 사용자가 입력한 영화검색키워드에 해당하는 검색결과는 어떻게 받아올까.

하이라이트한 위치에 검색키워드를 조합해서 접근하면 될 것 같다.
from bs4 import BeautifulSoup
movie = input("어떤 영화를 검색하시겠습니까? ")
url = f'https://movie.naver.com/movie/search/result.naver?query={movie}§ion=all&ie=utf8'
검색결과가 여러개가 있으므로, 이 리스트들을 크롤링해서 추출하자.
우리가 받아야 하는 것은, 영화들의 리스트, 그리고 해당 영화의 상세페이지 링크이다.
그 링크에서 code=숫자를 뽑아 해당 영화의 코드를 알아낼 수 있다.
개발자도구에서 코드를 확인해보자.

원하는 영역은 파란 네모부분이고, old_layout클래스에서 ul.search_list_1이다.
그런데 아래로 내리다보면 또 같은 클래스의 ul이 있어서 그 부분은 포함하지 않도록 잘 해야한다.
검색결과는 더보기하지 않는 이상 5개까지 제공한다. 키워드를 이상하게 하지만 않으면 대부분 이 안에서 나올것같다.
사용자에게 검색결과의 영화목록 5개를 보여줘서 몇 번째 영화를 검색하고싶은지 물을 것이다.
딕셔너리를 만들어 영화마다 key : 영화명, value : 영화코드를 만들고, 사용자가 원하는 영화의 코드를 사용할 것이다.
사용자가 영화 이름만 보고 정하기는 어려울 것 같으니, 영화 내용에 대한 부분도 크롤링해서 출력하였다.
res = requests.get(url)
index = 1
user_dic = {}
if res.status_code == 200:
soup=BeautifulSoup(res.text,'lxml')
for href in soup.find("ul", class_="search_list_1").find_all("li"):
print(f"=============={index}번 영화===============")
print(href.dl.text[:-2])
user_dic[index] = int(href.dl.dt.a['href'][30:])
index = index+1
사실 초짜라 애는 먹었지만 검색결과대로 잘 출력하니 뿌듯하다..ㅠㅠ
user_dic을 확인해보면 다음과 같다.

다음은 사용자가 정한 번호를 받고, 코드를 저장하는 간단한 코드이다.
이 코드를 영화리뷰사이트의 code = 뒤에 껴넣을 것이다.
movie_num = int(input("몇 번 영화를 선택하시겠습니까? (숫자만 입력)"))
code = user_dic[movie_num]
base_url = f'https://movie.naver.com/movie/bi/mi/pointWriteFormList.nhn?code={code}&type=after&onlyActualPointYn=N&onlySpoilerPointYn=N&order=sympathyScore&page='base_url 뒤에 페이지부분은 아직 설정하지 않았다. 리뷰가 여러 페이지 있을테니 크롤링하면서 저 뒤에 조합할것이다.

베이스주소가 잘 만들어졌다.
다음은 위에서 만들어진 링크에서 리뷰를 추출하는 포스팅을 할 것이다.
전체코드는 여기 Click!!
from bs4 import BeautifulSoup
def search() :
movie = input("어떤 영화를 검색하시겠습니까? ")
url = f'https://movie.naver.com/movie/search/result.naver?query={movie}§ion=all&ie=utf8'
res = requests.get(url)
index = 1
user_dic = {}
if res.status_code == 200:
soup=BeautifulSoup(res.text,'lxml')
for href in soup.find("ul", class_="search_list_1").find_all("li"):
print(f"=============={index}번 영화===============")
print(href.dl.text[:-2])
user_dic[index] = int(href.dl.dt.a['href'][30:])
index = index+1
movie_num = int(input("몇 번 영화를 선택하시겠습니까? (숫자만 입력) : "))
code = user_dic[movie_num]
base_url = f'https://movie.naver.com/movie/bi/mi/pointWriteFormList.nhn?code={code}&type=after&onlyActualPointYn=N&onlySpoilerPointYn=N&order=sympathyScore&page='
return base_url+'{}'
#페이지 포매팅하기 위함