

전단계에서 못다한 전처리를 마무리하자. 이전까지는 데이터를 쪼개고, 필요없는 것을 걸러내는 작업을 했다면 지금부터는 그렇게 해서 남은 단어들을 벡터화하는 단계이다. 생각보다 전처리가 오래걸리고 힘들었다.
그냥 긍정/부정을 나누는 것만 했다면, 어느정도 정제만 하고 성능에 영향을 주지 않을 정도만 하면 되는데, 우리는 키워드 추출까지 해야한다. 추출한 키워드가 최대한 불용어가 되지 않도록 데이터를 많이 살펴보아야한다.
아무튼 시작한다.
CountVectorizer
from sklearn.feature_extraction.text import CountVectorizerCountVectorizer에 대해서는 강의 03 단어 카운트 (CountVectorizer) - 토닥토닥 파이썬 - 텍스트를 위한 머신러닝 (wikidocs.net) <= 여기를 참조하면 좋다.
CountVectorizer는 단어들의 출현빈도로 여러 문서들을 벡터화한다.
여기서, 단어들을 벡터화할때 tokenizer로 앞서 정의한 preprocess함수를 사용할 것이다.
vectorizer = CountVectorizer(tokenizer = lambda x: preprocess(x,word_list))
data_features = vectorizer.fit_transform(data['Review'].tolist())
list_of_word = vectorizer.get_feature_names()전에는 Counter객체를 사용해서 확인했는데 이번엔 CountVectorizer을 이용해서 각 단어가 등장한 횟수를 확인해보자
count_list = data_features.toarray().sum(axis=0)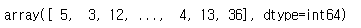
count_list와 word_list의 갯수는 같을 수 밖에 없다. 왜냐면 각 리뷰들을 preprocess를 통해 전처리하기로 했는데, preprocess내에서는 word_list에 속하는 것들만 남겨두었기 때문
count_list배열의 각 값은 단어의 빈도수를 뜻한다. 0번째 단어는 5회, 1번째 단어는 3회 등장했다.
몇번째 단어가 어떤 단어인지 나타내는 것은 list_of_word에 저장되어있다.

이 둘을 조합해서 보면 '가기'가 5번, '가깝다'가 3번, '가끔'이 12번 등장했다.
이렇게 따로따로 보기 귀찮은데, zip함수를 사용하면 같은 인덱스에 있는 것 끼리 묶어준다.
word_count_dict = dict(zip(word_list, count_list))
결과는 Counter객체로 연산했을 때와 같다.
data_features에 대해서 이해해보자.

크기는 17790*2641의 2차원 배열이다. 사실 모두 익숙한 숫자다.
리뷰갯수가 17790개였고, word_list가 2641개였다.
word_list는 전체 리뷰에서 뽑을 수 있는 조건을 만족하는 형태소의 집합이다.
따라서 모든 단어들을 인덱싱시켜놓고, 각 리뷰별로 형태소를 뽑은 후 원하는 위치에 1을 표시한 것이다.
쉽게 이해하기 위해서 다음과 같은 예시를 들어보자
txt1="사과는 맛있다.
txt2="바나나는 맛있다."
txt3="사과가 없다."
이때 word_list는 ['사과', '바나나', '맛있다', '없다']가 될 것이다.
이제 txt들을 변환할 것인데 [1,0,0,0] 이라면 사과라는 단어가 있다는 뜻이다.
[1,1,0,0]라면 txt내에 사과와 바나나가 들어있다는 뜻이 된다. 그랬을때 txt를 변환해보자
txt1 = [1,0,1,0]
txt2 = [0,1,1,0]
txt3 = [1,0,0,1]이 된다. 이 세 배열을 하나의 리스트로 저장하면 3*4의 배열이 될테고 이것이 곧 data_features이다.
17790개의 review들을 2641개의 인덱싱된 벡터로 표현한 것이다.
우리가 크롤링한 리뷰 데이터로 확인해보자.
첫번째 리뷰는 다음과 같다.

data_features의 첫번째 원소는 이 리뷰를 전처리 해 인덱싱 한 것이다. 확인해보자.

1*2641배열 중에, 본 리뷰가 가지고 있던 형태소가 의미하는 위치에 1이 표시되어있을 것이다.
1인것들의 인덱스를 뽑아보자.
index = []
i = 0
for x in data_features.toarray()[0]:
if x==1:
index.append(i)
i = i+1
그럼 이제 이 인덱스가 어떤 단어인지 확인하기 위해 list_of_word에서 찾아보자.
[list_of_word[x] for x in index]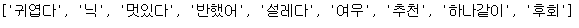
TF-IDF
from sklearn.feature_extraction.text import TfidfTransformer위에서 data_features가 리뷰에 나오는 단어들을 배열로 벡터화시킨 것이라는 걸 이해했다.
TF-IDf는 문사의 유사도를 구하는 작업, 특정 단어의 중요도를 구하는 작업등에서 쓰인다고 한다.
4) TF-IDF(Term Frequency-Inverse Document Frequency) - 딥 러닝을 이용한 자연어 처리 입문 (wikidocs.net)
tf-idf에 대해 자세하게 알고 싶으면 위 링크를 추천한다.
tfidf_vectorizer = TfidfTransformer()
tf_idf_vect = tfidf_vectorizer.fit_transform(data_features)여기서 각 단어에 대한 인덱스가 어떻게 배정되었나 확인해보자.
vectorizer.vocabulary_
반대로, 나중에 변환하기 위해 각 인덱스가 어떤 단어를 나타내는지에 대한 것도 정의하자
invert_index_vectorizer = {v: k for k, v in vectorizer.vocabulary_.items()}
리스트에 강동원, 황정민이 있다니....
3번이상 등장했다는 건데 주토피아랑 무슨 연관이 있었을까..?
아무튼 다음은 이때까지 처리한 것을 가지고 긍/부정별 키워드를 추출할 것이다.
전체코드는 여기 Click!!
def no_space(text):
text1 = re.sub(' | |\n|\t|\r', '', text)
text2 = re.sub('\n\n','', text1)
return text2
def extract_word(text):
hangul = re.compile('[^가-힣]')
result = hangul.sub(' ', text)
return result
def load_stopwords(basepath):
print("불용어셋을 가져오고 있습니다.")
with open(basepath+'stopwords.txt', 'r') as f:
list_file = f.readlines()
return list_file[0].split(",")
class Review_keyword:
def __init__(self, minimum_count:int)->None:
self.basepath = input("데이터를 저장하고 불러올 기본 경로를 입력해주세요 ")
self.minimum_count = minimum_count
self.word_list = None
self.name = None
self.url = None
self.data = None
self.stopwords = load_stopwords(self.basepath)
self.vocab = None
def search(self) :
self.name= input("어떤 영화를 검색하시겠습니까? ")
url = f'https://movie.naver.com/movie/search/result.naver?query={self.name}§ion=all&ie=utf8'
res = requests.get(url)
index = 1
user_dic = {}
if res.status_code == 200:
soup=BeautifulSoup(res.text,'lxml')
for href in soup.find("ul", class_="search_list_1").find_all("li"):
print(f"=============={index}번 영화===============")
print(href.dl.text[:-2])
user_dic[index] = int(href.dl.dt.a['href'][30:])
index = index+1
movie_num = int(input("몇 번 영화를 선택하시겠습니까? (숫자만 입력) : "))
code = user_dic[movie_num]
base_url = f'https://movie.naver.com/movie/bi/mi/pointWriteFormList.nhn?code={code}&type=after&onlyActualPointYn=N&onlySpoilerPointYn=N&order=sympathyScore&page='
self.url = base_url+'{}'
def save_and_load(self,dataframe):
dataframe.to_csv(self.basepath+f'{self.name}review.csv' , index= False)
df = pd.read_csv(self.basepath+f'{self.name}review.csv')
df = df.dropna()
df = df.drop_duplicates()
df = df.reset_index(drop=True)
return df
def crawl_review(self):
res = requests.get(self.url)
if res.status_code == 200:
soup=BeautifulSoup(res.text,'lxml')
total = soup.select('div.score_total > strong > em')[0].text
pages = int(total.replace(',','')[:-1]) #17,921 > 17921로 변환 후 캐스팅
print()
print(f"{pages}개의 페이지에서 {self.name} 영화 리뷰를 모으고 있습니다.")
time.sleep(1)
comments = []
stars = []
for page in tqdm(range(1,pages+1)):
url = self.url.format(page)
res = requests.get(url)
if res.status_code == 200:
soup=BeautifulSoup(res.text,'lxml')
star = soup.select('div.score_result > ul > li > div.star_score > em')
tds = soup.select('div.score_result > ul > li > div.score_reple > p > span')
for st in star:
stars.append(int(st.text))
for cmt in tds:
if cmt.text != '관람객' and cmt.text !='스포일러가 포함된 감상평입니다. 감상평 보기':
comments.append(no_space(cmt.text))
if(len(comments) != len(stars)):
print(url)
break
assert len(comments) == len(stars)
self.data = self.save_and_load(pd.DataFrame({"Review":comments, "Rank":stars}))
def make_wordlist(self,reviews): #reviews = " ".join(data['Review'].tolist())
print("리뷰들을 모아 분석하는 중입니다.....")
#정규표현식 적용
print("데이터 정제 중....")
words = extract_word(reviews)
#형태소 추출
print("형태소 추출 중....")
okt = Okt()
words = okt.morphs(words,stem=True)
#한글자 제거
print("한글자 제거 중....")
words = [x for x in words if len(x)>1 or x =='닉']
#불용어 제거
print("불용어 제거 중....")
words = [x for x in words if x not in self.stopwords]
#최소횟수 미만 제거
print("의미있는 단어리스트 생성 중....")
time.sleep(1)
minimum_count = 3
final = []
for i in tqdm(range(len(words))):
tmp = words[i]
if words.count(tmp) >= minimum_count:
final.append(tmp)
self.word_list = set(final) #조건을 만족하는 단어 리스트
def preprocess(self,text):
text = extract_word(text)
okt = Okt()
text = okt.morphs(text, stem = True)
text = [x for x in text if x in self.word_list]
return text
def tf_idf(self):
vectorizer = CountVectorizer(tokenizer = lambda x: self.preprocess(x))
data_features = vectorizer.fit_transform(self.data['Review'].tolist())
tfidf_vectorizer = TfidfTransformer()
tf_idf_vect = tfidf_vectorizer.fit_transform(data_features)
self.vocab = {v: k for k, v in vectorizer.vocabulary_.items()}
return tf_idf_vect
def ready(self):
self.search()
self.crawl_review()
self.make_wordlist(" ".join(self.data['Review'].tolist()))
self.tf_idf()
time.sleep(0.5)
print("작업을 완료했습니다.")