

논문정보
TransFG : A Transformer Architecture for Fine-Grained Recognition
TransFG: A Transformer Architecture for Fine-grained Recognition
Fine-grained visual classification (FGVC) which aims at recognizing objects from subcategories is a very challenging task due to the inherently subtle inter-class differences. Most existing works mainly tackle this problem by reusing the backbone network t
arxiv.org
논문정리
Abstract
하위 카테고리의 물체를 인식하는 Fine-grained visual classification (FGVC)는 클래스 간 미묘한 차이 탓에 힘든 작업이다.
많은 연구들이 이 문제를 백본 네트워크를 재사용하여 차별성이 있는 영역의 특징들을 추출하는 방식으로 다루는데,
이런 방식은 파이프라인을 복잡하게 만들고 제안된 영역이 객체의 많은 부분을 포함하도록 강제하기 때문에 정말 중요한 부분을 찾는 데 실패할 수 있다.
최근에는 비젼 트랜스포머 (ViT) 가 전통적인 분류 작업에서 좋은 성능을 보여왔다.
트랜스포머의 셀프 어텐션 구조가 모든 패치토큰을 분류토큰에 연결한다.
본 연구에선 fine-grained 인식 환경에서 ViT 프레임워크의 효용성을 평가한다.
Attention link의 강도(strength)를 토큰의 중요성을 타나내는 지표로 고려할 수 있다는 점을 동기로 하여, 네트워크가 효과적이고 정확하게 차별성있는 이미지 패치를 선택하고 그들의 관계를 계산하도록 가이드하기 위해서 트랜스포머의 모든 원시 어텐션 가중치를 어텐션맵과 통합하는 새로운 "Part Selection Module"을 제안한다.
대조손실(constrastive loss)이 혼동되는 클래스에 대한 특징 표현의 거리를 확장하기 위해 사용된다.
이 증강 트랜스포머 기반의 모델을 TrarnsFG라고 지칭하고 5가지 대표 fine-grained 벤치마크에 대한 실험을 통해 SOTA를 달성하여 그 가치를 증명한다.
Introduction
Fine-grained 이미지 분류는 주어진 객체 카테고리의 하위 클래스를 분류하는 작업이다.
새, 차, 항공기, ...
클래스 간 변화가 크고 클래스 내 변화가 작은 특성 탓에 데이터가 결핍한 long-tailed class와 함께 까다로운 작업으로 여겨져왔다.
심층 신경망이 발전하면서 최근 FGVC의 성능이 꾸준히 개선되었다.
Annotation에 많은 노동이 필요하기 때문에 이를 피하기 위해, 이미지 라벨만을 필요로하는 약지도(weakly supervised) FGVC에 많이 집중되었다.
크게는 localization과 feature-encoding의 두가지 방법으로 나눌 수 있다.
Feature encoding 방법과 달리, localization은 더 해석하기 쉽고 좋은 결과를 가져오는 하위클래스간의 미묘한 차이를 포착할 수 있는 장점이 있다.
localization의 초기 연구는 주석(annotation)에 의존해서 차별성있는 영역을 찾는 것에 집중하였지만 최근 연구는 Region Proposal Networks(RPN)을 채택하여 차별성 있는 영역을 포함하는 바운딩박스를 제안한다.
선택된 이미지 영역을 얻으면 미리 지정된 크기로 사이즈가 재조정되고, 백본 네트워크를 다시 통과하여 유익한 로컬 특징을 얻는다.
이 로컬특징을 분류에 사용하거나 rank loss를 사용하여 바운딩박스의 퀄리티와 최종 확률 output간의 일관성을 유지하는 것이 일반적인 방법이다.
하지만, 이 메커니즘은 선택된 영역간의 관계를 무시하고, RPN이 바운딩 박스를 크게크게 생성하도록 만들어버린다.
그러면 객체의 거의 모든 파트가 바운딩박스에 포함되고 정작 진짜 중요한 영역이 어디있는지는 알 수 없게 된다.
가끔씩은 바운딩박스가 배경영역의 상당부분을 포함하는 경우가 있고 이 경우 혼란에 빠진다.
게다가 백본 네트워크와 RPN 모듈의 최적화 목표가 다르면 모델이 훈련하기 더 어려워지고, 백본을 재사용하면 전체적인 파이프라인이 복잡해진다.
최근에는 ViT가 분류 작업에서 크게 성공하면서 순수한 트랜스포머의 어텐션 메커니즘을 바로 이미지 패치 시퀀스에 적용하면 이미지 내에서 중요한 영역을 포착할 수 있다는 것을 보여주었다.
이어서 객체감지 및 의미분할 같은 downstream task에 대한 연구를 통해 global 및 local 특징을 모두 포착ㅎ랄 수 있는 강력한 기능을 확인하였다.
트랜스포머의 이 기능들은 트랜스포머가 초기 "receptive field"를 통해 이전에 처리된 레이어에서 미묘한 차이와 공간관계를 찾아낼 수 있도록 할 수 있어 본질적으로 FGVC 작업에 적합하다.
대조적으로, CNN은 주로 이미지의 locality 특성을 추출하고 매우 높은 층에서 약한 장거리 관계를 포착한다.
게다가 fine-grained 클래스 간 미묘한 차이점은 특정 부분에서만 존재하기 때문에 이미지의 전체 공간에 대해 차이점을 찾아내는 필터로 컨볼루션하기는 부적절하다.
이런 의견을 토대로 본 논문에선 fine-grained 이미지 분류에서 vision transformer의 잠재력을 확인하는 연구를 진행한다.
FGVC에 ViT를 그대로 적용해도 이미 만족스러운 결과를 얻을 수 있지만, FGVC 특성에 맞게 적응시키면 성능을 더욱 높일 수 있다.
차별성 있는 영역을 찾고 중복된 정보를 제거하는 Part Selection Module 제안
모델의 구별 능력을 키우기 위해 대조손실(contrastive loss)를 도입하였다.
새롭지만 단순한 트랜스포머 기반의 프레임워크를 TransFG라 지칭하고, 5개의 유명한 fine-grained 이미지 분류 벤치마크에 대해 평가하였다.
CUB-200-2011, Standford Cars, Standford Dogs, NABirds, iNat2017

그림1에서 성능 비교 결과에 대한 개요를 확인할 수 있고, 이때 TransFG는 대부분의 데이터셋에서 CNN 기반의 SOTA를 뛰어넘었다.
1. 본 연구진이 아는 한, fine-grained 이미지 분류 작업에서 vision transformer의 능력을 검증한 것은 이번이 처음이며, RPN 모델 설계를 통해 그동안 지배적이었던 CNN backbone에 대한 대안을 제시
2. Fine-grained 이미지 분류를 위한 새로운 신경 구조 TransFG를 소개하였다. 이는 본질적으로 객체에서 가장 차별성 있는 영역에 집중하고 여러 벤치마크에 대해 SOTA 성능을 달성하였다.
3. 시각화 결과를 통해 차별성있는 이미지 영역을 포착하여 어떻게 올바른 예측을 하는지 이해할 수 있도록 하는 TransFG의 능력을 확인할 수 있다.
Related Work
<Fine-Grained Visual Classification>
Fine-grained 이미지 분류의 문제점을 해결하기 위한 많은 연구가 있었고 주로 2가지로 나눌 수 있다.
localization methods and feature-encoding methods
전자는 차별성 있는 곳의 영역을 찾아내는 탐지 네트워크를 훈련하고 이를 재사용하여 분류를 수행하는 것에 초점을 둔다.
후자는 high-order 정보를 계산하거나 대조되는 쌍 사이의 관계를 찾아내는 등 보다 유익한 기능을 학습하는 것을 목표로 한다.
Localization FGVC methods
몇몇 연구는 part annotation을 사용하여 localization process의 학습과정을 감독하였다.
하지만 이런 주석(annotation)은 비용이 많이 들고 대게는 사용할 수 없기 때문에 이미지 수준의 라벨만을 이용하여 약한 지도학습을 하는것이 요즘 많은 관심을 끌고 있다.
Feature-encoding methods
다른 방법은 특징 표현을 풍부하게 하여 좋은 분류 결과를 얻는것에 초점을 둔다.
Yu et al. (Yu at el. 2018) - 계층 구조를 제안하여 레이어 간 (cross-layer) binary pooling을 수행한다.
Zheng et al. (Zheng et al. 2019) - 그룹 컨볼루션의 개념을 채택하였는데 이는 첫째로 채널을 semantic meaning에 따라 각기 다른 그룹으로 분할한 후 각 그룹에 대해 차원을 변경하지 않고 bilinear pooling을 수행하여 바로 백본에 통합될 수 있도록 하였다.
하지만, 이런 방법들은 대게 해석할 수 없기 때문에, 모델이 어떤 미묘한 차이로 하위 카테고리를 구별하는지 이해할 수 없지만, 본 연구에서 제안한 모델은 fine-grained 인식을 위해 중요하지 않은 패치는 삭제하고 대부분의 정보가 포함된 패치는 유지한다.
Transformer
트랜스포머와 셀프어텐션 모델 이후로 자연어 처리 및 기계 번역에 대한 연구가 활발하게 이뤄졌다.
이제는 이어서 최근의 많은 연구들이 컴퓨터비전 분야에 트랜스포머를 적용하려고 시도하고 있다.
초기 트랜스포머는 동영상에 대해 CNN 백본에서 추출한 sequential feature을 다뤘는데 이후엔 객체탐지, 세그멘테이션, 객체추적 등 여러 인기있는 컴퓨터 비전 작업으로 확장하게 되었다.
가장 최근에는 순수 트랜스포머 모델이 더 많이 쓰이고 있다.
ViT는 이미지 분류 작업에서 순수 트랜스포머를 일련의 이미지 패치에 적용하였을 때 SOTA를 달성할 수 있음을 보여주는 첫 연구이다.
이를 기반으로 세그멘테이션에서 ViT를 인코더로 활용한 SETR이 제안되었다.
TransReID는 JPM과 함께 트랜스포머에 사이드 정보를 내장하고 있으며 이를 통해 객체 재식별 성능을 향상시킨다.
본 연구에선, ViT를 확장하여 fine-grianed 이미지 분류작업에 사용하고 그 효용성을 보여준다.
Method
첫째로 Vision Transformer의 프레임워크에 대해 간단하게 살펴본 후 fine-grained 인식으로 확장하기 위해 어떤 단계를 거쳤는지 확인한다. 그 뒤, TransFG의 전체적인 프레임워크를 설명한다.
<Vision transformer as feature extractor>
Image Sequentialization
ViT에 이어 먼저 입력 이미지를 flatten된 패치 xp의 시퀀스가 되도록 전처리한다.
그러나, 기존에 사용한 분할방법은 이미지를 겹치는 부분이 없는 패치로 자르는 것인데, 이렇게하면 특히 차별성있는 영역이 분할되는 경우에 local neighboring 구조를 잃게 된다.
이 문제는, sliding window를 사용하여 겹치는 부분이 있는 패치를 생성하는 방법으로 해결한다.
H∗W의 해상도를 갖는 입력 이미지에 대해, 이미지 패치의 사이즈는 P, slinding window의 step size는 S로 표기를 한다.
이때 입력 이미지는 N개의 패치로 분할된다.
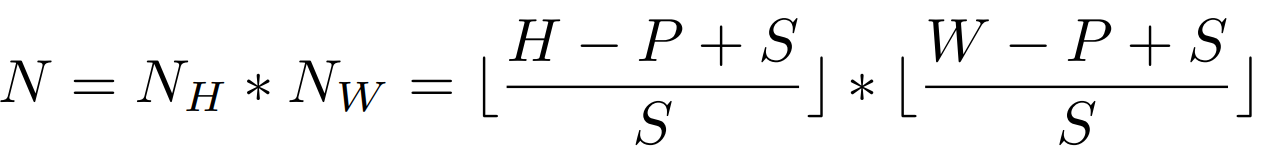
두개의 인접한 패치는 (P−S)∗P만큼의 겹치는 영역을 가지며, 더 좋은 로컬 영역 정보를 보존하게 된다.
일반적으로는, step S가 작을수록 성능이 좋아지지만 S를 감소하기 위해선 더 많은 연산비용이 들게 된다.
trade-off 관계
Patch Embedding
학습 가능한 선형 프로젝션을 통해 벡터화된 패치 xp와 D 차원의 잠재 임베딩 공간을 매핑한다.
학습할 수 있는 위치 임베딩이 패치 임베딩에 추가되어 다음과 같은 잠재 정보를 유지한다.
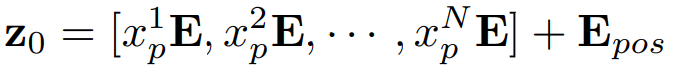
N은 이미지 패치 수이며 E∈R(P2˙C)∗D는 patch embeding projection,
Epos∈RN∗D는 position embedding
트랜스포머 인코더는 L개의 멀티 헤드 셀프 어텐션 (MSA)층과 멀티 레이어 퍼셉션 (MLP) 블록으로 구성되어있다.
따라서 l번째 층의 출력은 다음과 같이 표기한다.
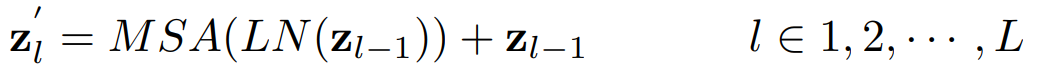
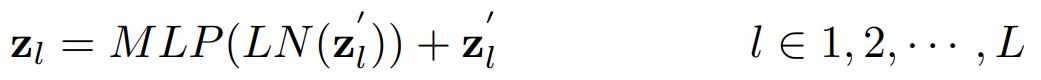
LN(˙)은 레이어 정규화 연산을 나타내고 zl은 인코딩된 이미지 표현이다.
VIT는 최종 인코더 레이어의 첫번째 토큰 z0+L을 전역 특징의 표현으로 활용하여 분류 헤드에 전달하여 최종 분류 결과를 얻는다.
나머지 토큰이 갖고 있는 잠재적인 정보는 무시
<TransFG Architecture>
본 실험에서 순수 비젼 트랜스포머를 fine-grained 이미지 인식 작업에 적용하여 좋은 결과를 얻었음을 보여주긴 하지만, FGVC가 필요로하는 로컬 정보를 잘 포착하지는 못한다.
이를 위해 Part Selection Module (PSM)을 제안하고 대조 특징 학습(constrastive feature learning)을 적용하여 혼동되는 하위 카테고리간의 표현 거리가 커지도록 한다.
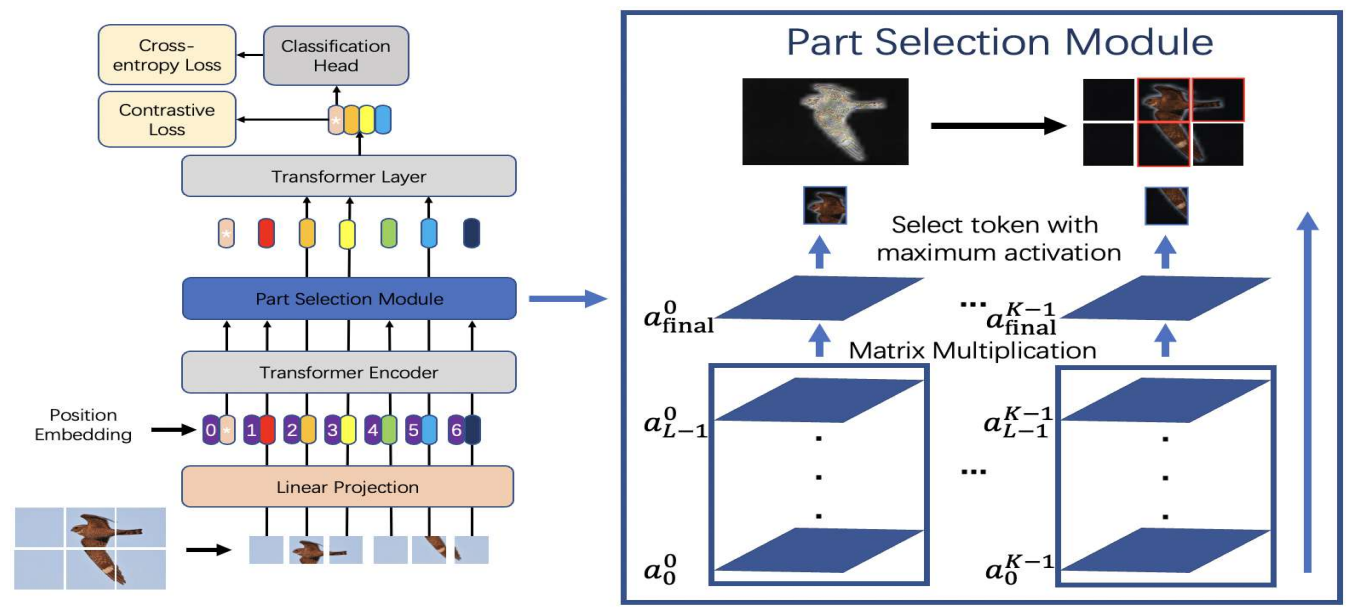
그림2는 제안된 TransFG의 프레임워크.
<Part Selection Module>
Fine-grained 이미지 인식에서 가장 중요시되는 문제는 비슷한 하위 카테고리간의 미묘한 차이를 설명하는 차별성있는 영역을 정확하게 찾아내는 것이다.
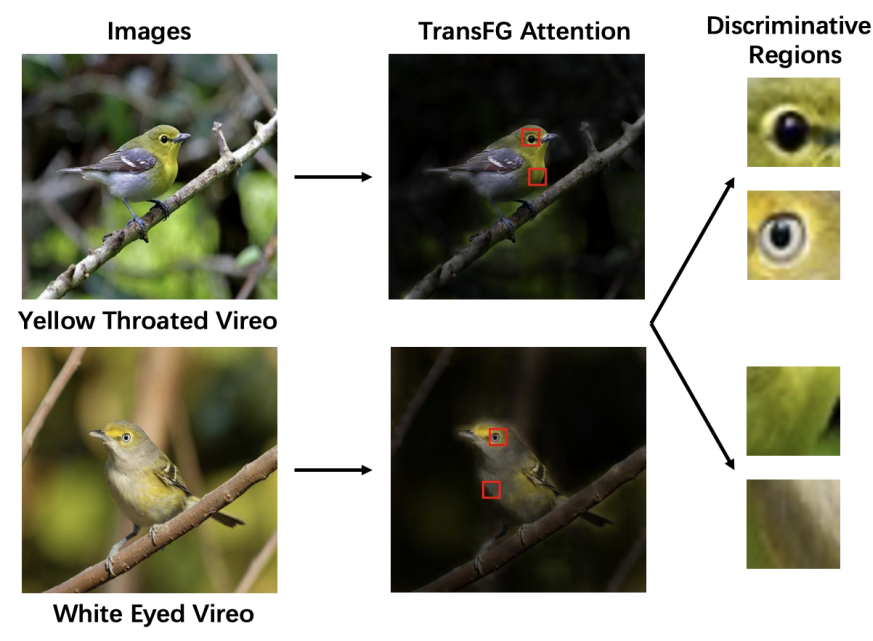
예시로, 그림 3은 CUB-200-2011 데이터셋에서 헷갈릴 수 있는 이미지 쌍을 보여준다.
모델은 매우 작은 변화를 포착할 수 있는 능력이 필요하다
새의 품종을 구별하기 위한 눈과 목의 색깔
기존의 CNN기반의 방법에선 영역 제안 네트워크와 약지도 세그멘테이션 전략이 널리 쓰인다.
Vision Transformer 모델은 멀티헤드 어텐션 메커니즘이 있어 이 문제에 완벽하게 적합하다.
어텐션 정보를 전부 활용하기 위해, 마지막 트랜스포머 층으로 들어가는 입력을 변경한다.
모델에 K개의 셀프 어텐션 헤드가 있고, 마지막 층에 들어가는 hidden feature input을 zL−1=[z0L−1;z1L−1,z2L−1,⋯,zNL−1이라 표기
이전 층의 어텐션 가중치는 다음과 같이 표기한다.

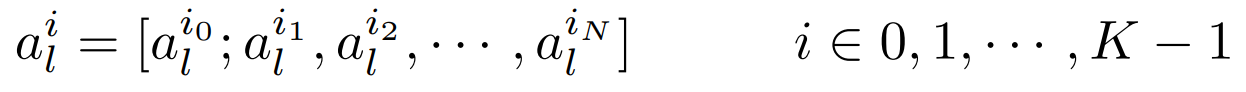
이전 연구에선, 원시 어텐션 가중치가 모델의 상위 층에 입력으로 들어가는 토큰의 상대적 중요성과 반드시 일치하지 않는다고 주장하였다.
임베딩 내에서 토큰 식별 가능성이 부족하기 때문
이런 이유로 본 연구진은 이전의 모든 레이어에 대한 어텐션 가중치를 통합하였다.
모든 레이어의 원시 어텐션 가중치에 행렬 곱셈을 반복적으로 적용
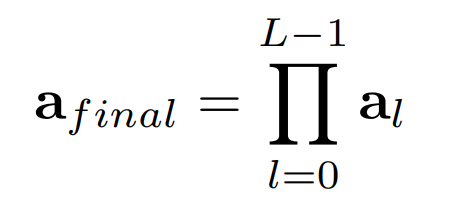
afinal은 정보가 입력층에서 상위 레이어의 임베딩으로 전파되는 방식을 포착하기 때문에, 단일 원시 어텐션 가중치 aL−1에 비해 차별성 있는 영역을 더 잘 고를 수 있다.
다음으로는 afinal의 각기 다른 K개의 어텐션 헤드에 대해 최대값 A1,A2,⋯,AK의 인덱스를 찾는다.
이 위치(인덱스)들은 모델이 zfinal에서 일치하는 토큰을 추출할때 인덱스로 사용한다.
최종적으로 분류 토큰과 선택된 토큰을 연결하여 input sequence로 사용
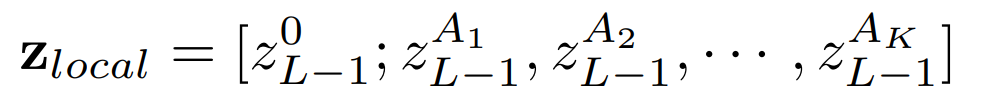
기존의 입력 시퀀스 전체를 정보가 담긴 영역에 해당하는 토큰으로 대체하고, 분류 토큰을 최종 트랜스포머 층에 연결하게 되면서, 전역 정보를 유지하는 것 뿐만 아니라 최종 트랜스포머 층이 배경이나, 공동된 특징이 있는 차별성이 적은 영역을 버리게 하여 다른 하위 카테고리간 미세한 차이에 집중할 수 있도록 한다.
<Contrastive feature learning>
아직 여전히 PSM모듈의 첫번째 토큰 zi를 사용한다.
클래스간 차이가 매우 작기 때문에 단순히 크로스 엔트로피 손실을 사용하는 것은 특징학습 완전히 지도하기에 충분하지 않다.
이를 위해, 대조손실(constrastive loss) Lcon을 도입하여 y라벨을 가지는 샘플들의 분류 토큰 유사성을 최소화한다.
손실값이 easy negative 의 영향을 많이 받지 않게 하기 위해서 α보다 큰 유사성을 가진 negative 쌍만이 손실 Lcon에 영향을 줄 수 있도록 constant margin α을 도입하였다.
Easy negative : different class samples with little similiarity
배치 크기 B에 대한 대조 손실은 다음과 같다.
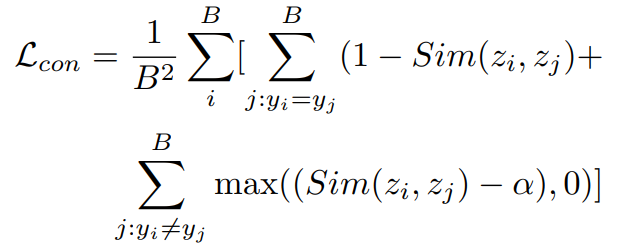
zi,zj는 l2 정규화를 거쳤으며 Sim(zi,zj)는 zi,zj의 내적을 의미함
요약하면, 모델은 크로스 엔트로피 손실 Lcross과 대조 손실 Lcon의 합으로 표현됨
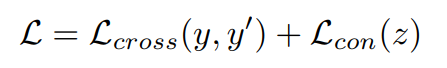
Experiments
데이터셋과 훈련에 사용된 하이퍼 파라미터 세팅들을 디테일하게 다루고, ablation study를 통해 정량 분석
<Experiments Setup>
Datasets
TransFG를 사용하여 널리 사용되는 fine-grained 벤치마크 데이터셋을 평가해본다.
CUB-200-2011, Stanford Cars, Stanford Dogs, NABidrs, iNat2017
Implementation Details
다른 언급이 없는 한, TransFG의 세팅은 다음과 같다.
- 입력 이미지는 448*448로 조정한다. 다만, iNat2017은 304*304로 조정함.
- 이미지는 16개의 패치로 나누고 slinding window의 크기는 12로 세팅
- 식 1의 H, W, P, S = 448,448,16,12
- 식 9의 α=0.4
- ImageNet21k로 사전훈련 한 official VIT-B_16 모델로부터 가중치를 가져옴
- 배치 크기 16
- 옵티마이저 SGD (momentum = 0.9)
- 초기 학습률 0.03 (다만, Stanford Dogs은 0.003, iNat2017은 0.01)
- 옵티마이저 스케쥴러 cosine annealing
- 실험 환경 : Nvidia Tesla V100 GPUs, PyTorch toolbox, APEX
Quantitavie Analysis
위에서 언급된 5개의 데이터셋에 대해 TransFG 모델과 SOTA를 달성한 연구들을 비교해본다.
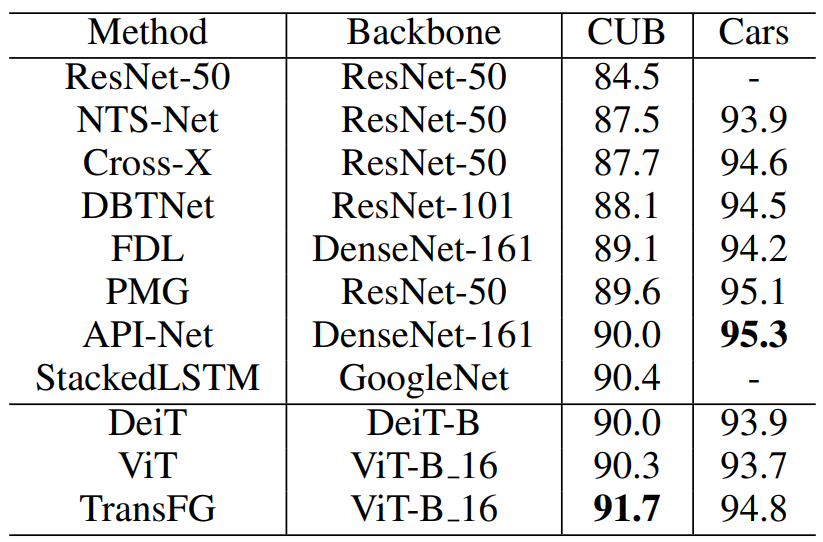
표1은 CUB-200-2011과 Stanford Cars에 대한 결과를 보여준다.
CUB 데이터셋에선 제안된 방법이 이전의 방법들을 모두 능가하였고, Stanford Cars에 대해선 경쟁력있는 결과를 보여주었다.
구체적으로 보면, CUB에서 기존의 가장 좋은 성능을 보였던 것은 StackedLSTM이지만, TransFG 로 실험했을 때는 Top-1 정확도 기준 1.3%만큼 더 향상하였다.
그 이유를 추적해보면, 여러 ResNet-50이 multiple branch처럼 사용되어 복잡성을 증가시켰다. 반면 TransFG는 단순성을 유지하기 때문에 STackedLSTM이 실제 사용환경에서 가용성을 해하는 지저분한 multi-stage 훈련모델인 것임.
Cars에서는 제안된 모델이 대부분의 방법에 비교해서는 성능을 능가하지만 PMG, API-NET 보다는 성능이 조금 떨어진다.
자동차들의 모양들이 규칙적이고 단순했기 때문이라고 추측한다.
그렇다해도 기존의 ViT모델에 비해서는 1.1% 향상하였다.
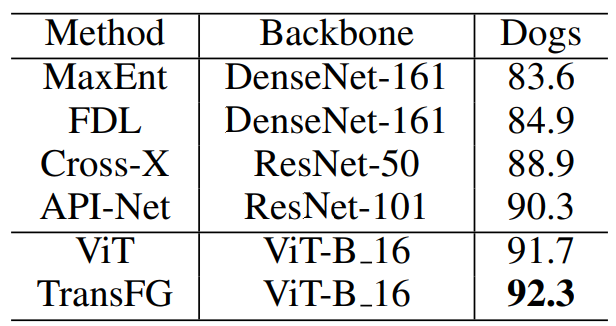
Stanford Dogs는 Stanford Cars에 비해 특정 종 간의 차이가 더 미세하고, 동일한 클래스에 대한 샘플의 분산이 크기 때문에 더 어렵다고 볼 수 있다.
이 데이터셋으로는 몇가지 연구들만 테스트 해보았으며 물론 TransFG가 모두 능가하였다.
ViT가 다른 방법들보다 훨씬 뛰어난 성능을 보이지만, TransFG는 SOTA보다 2.0% 높은 92.3%를 달성하였다.
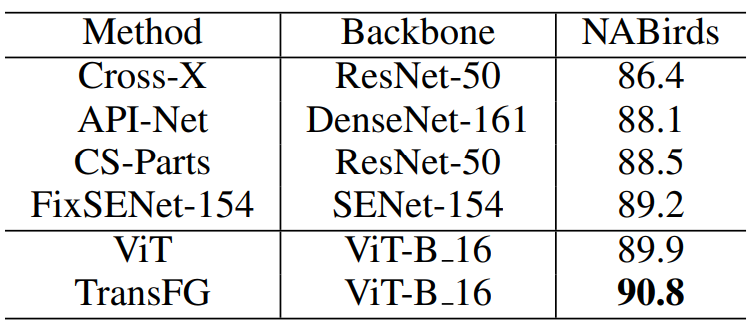
NABirds는 이미지 수뿐만 아니라 카테고리가 355개 이상 있기 때문에 fine-grained 이미지 인식 작업이 더 힘들다.
대부분의 연구에서는 여러 백본모델들을 서로 다른 브랜치에 사용하거나, 깊은 CNN구조를 채택하여 좋은 결과를 얻었다.
순수 VIT는 89.9%의 성능을 얻었지만 제안된 TransFG는 90.8%을 달성하면서 SOTA에 비해 1.6% 향상되었다.
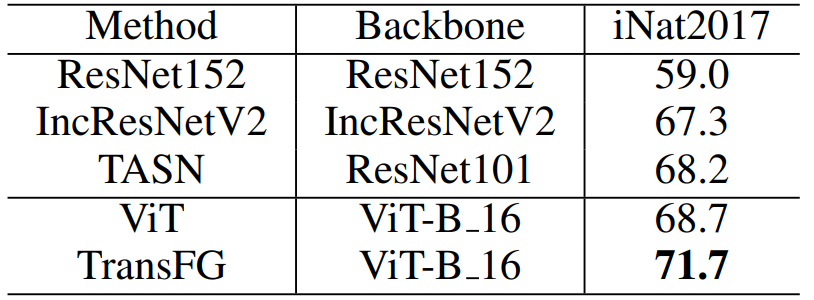
iNat2017은 fine-grained 인식을 위한 대규모 데이터셋.
이전의 대부분 연구에서는 multi-crop, multi-scale, multi-stage optimization의 계산 복잡도로 인해 이 데이터셋을 많이 다루지 않았음.
이 데이터셋은 의미있는 객체 위치를 찾아내기 어렵고 배경부분도 굉장히 복잡하다.
Vision Transformer 구조가 ResNet보다 훨씬 잘 먹혔음.
ViT가 ResNet152보다 거의 10% 높았고 iNat2018, iNat2019에 대해서도 비슷했다.
TransFG는 입력크기 304에 대해 70%이상의 정확도를 보이고 SOTA에 비해 3.5%보다 향상되었다.
iNat2021 대회에서 TransFG가 91.3%의 매우 높은 단일 모델 정확도 달성
최종 성능은 multi-modality processing과 함께 많은 모델들의 앙상블로 획득
그래도 top-5 팀 중 최소 2개 팀이 앙상블 모델 중 하나로 TransFG를 채택함
<Ablation Study>
모든 연구는 CUB-200-2011 데이터셋으로 수행하였다.
Influence of image patch split method
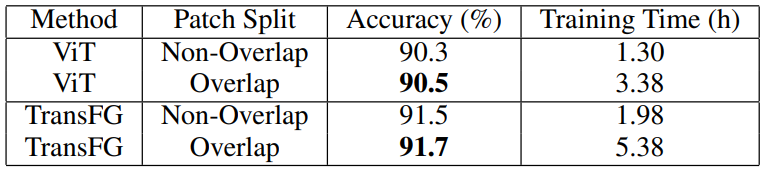
기존의 겹치는 부분 없이 패치를 분할하는 방법과 비교하여 패치를 겹치게 분할하는 방법의 영향을 확인한다.
표 5를 확인해보면 순수 ViT모델과 TransFG프레임워크 모두 패치를 겹치게 분할했을 때가 더 개선된 결과를 보여주었다.
Influence of Part Selection Module
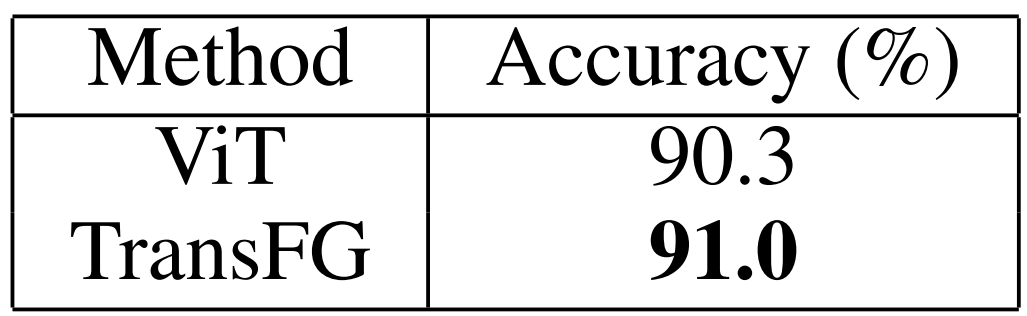
표 6에서는 PMS를 적용하여 차별성있는 영역 토큰을 선택해 최종 트랜스포머 층의 입력으로 넣었을 때 성능이 90.3%에서 91.0%으로 오른 것을 확인할 수 있다.
가장 차별성있는 토큰을 입력으로 사용하여 쓸모없는 토큰을 버리고, 네트워크가 중요한 부분을 학습하도록 하기 때문이다.
Influence of contrastive loss

ViT, TransFG에 대해 대조손실의 사용여부에 따른 비교는 표 7에서 확인할 수 있다.
대조손실을 사용했을 경우, 모델이 큰 성능 향상을 얻는다.
ViT의 경우 90.3%에서 90.7%, TransFG는 91.0%에서 91.5%
대조손실이 비슷한 카테고리간의 표현 거리를 확장시키고, 같은 카테고리간 표현 거리는 줄여주기 때문이라고 본다.
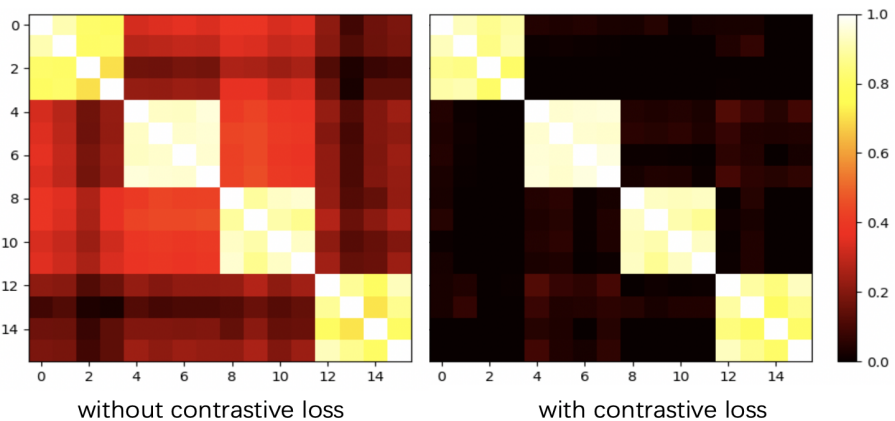
그림 4에서 혼돈행렬을 통해 비교할 수 있다.
Influence of marign α
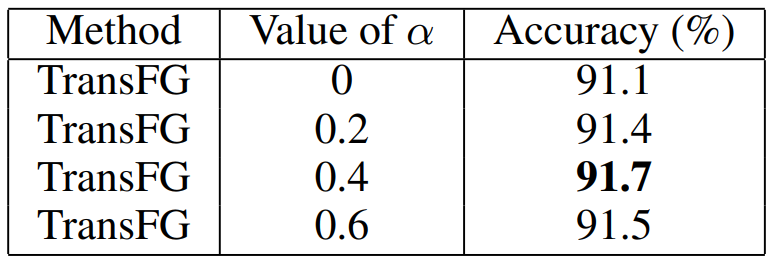
식 9의 margin α에 대해서 각기 다른 세팅에 대한 결과를 표 8에서 확인할 수 있다.
α의 값이 작으면 easy negative의 영향을 많이 받는 시그널을 유도해서 성능을 감소시키는 반면, 값이 크면 모델이 hard negative의 거리를 증가시키기 위한 정보학습을 방해한다는 것을 찾아냄
실험적으로 0.4일때가 가장 결과가 좋았다.
Qualitative Analysis

제안된 TransFG 모델에 대한 시각화 결과를 그림 5에서 확인할 수 있다.
CUB-200-2011, Stanford Dogs, Stanford Cars, NABirds
각 데이터셋에서 샘플 3개를 랜덤으로 선택하였다.
그림 5에서 1,3번째 행은 선택된 토큰의 위치를 보여줌
Top-4의 패치만 시각화하였고, 패치의 위치는 그대로인 채 사각형만 2개 키워서 시각화함
2,4번째 행은 전체 이미지의 attention map을 보여줌.
위에서 언급된 어텐션 통합방법을 사용하여 모든 레이어의 어텐션 가중치를 통합한 후, 각 헤드의 가중치들을 평균내어 단일 어텐션 맵을 만든다.
영역이 밝을수록 중요한 부분임을 의미한다.
사진을 보면 TransFG가 가장 중요한 영역들을 객체에서 잘 포착했음을 확인할 수 있다.
동시에, 전체적인 어텐션 맵이 복잡한 배경속에서도 객체를 잘 찾아내었고, 간단한 경우 세그멘테이션으로도 사용할 수 있겠다.
Conclusion
본 연구에서는 fine-grained 인식 프레임워크인 TransFG를 제안하고 4개의 벤치마크 데이터셋에 대해 SOTA를 달성하였다.
셀프 어텐션 구조를 사용하여 차별성 있는 영역을 찾아내었다.
다른 연구에서 사용된 바운딩박스와 비교하여, 본 연구에서의 이미지 패치들은 훨씬 더 작기 때문에 어떤 영역이 실제로 분류에 기여하는지 보여줄 수 있다.
대조 손실을 도입하여 분류 토큰의 식별 능력을 향상하였다.