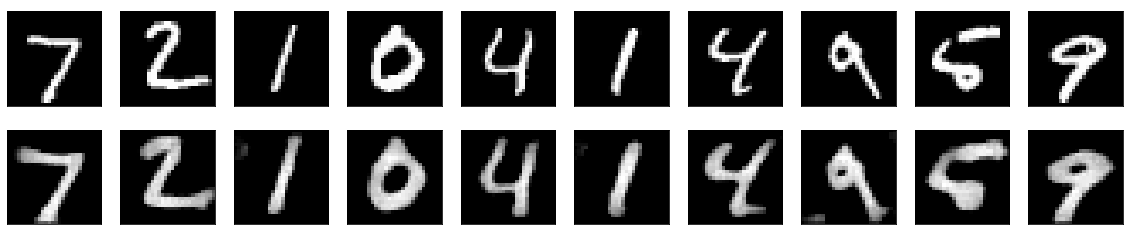import numpy as np
from tensorflow.keras.datasets import mnist
from tensorflow.keras.layers import Input, Dense, Flatten, Reshape, Conv2D, Conv2DTranspose
from tensorflow.keras.models import Model
from tensorflow.keras import backend as K
#MNIST 데이터 읽고 신경망 입력 준비
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train = x_train.astype('float32')/255.
y_train = y_train.astype('float32')/255.
x_train = np.reshape(x_train, (len(x_train),28,28,1))
x_test = np.reshape(x_test, (len(x_test),28,28,1))
zdim = 32 #잠복 공간의 차원
#오토인코더의 인코더 부분 설계
encoder_input = Input(shape=(28,28,1))
x= Conv2D(32,(3,3),activation='relu', padding='same', strides=(1,1))(encoder_input)
x= Conv2D(64,(3,3),activation='relu', padding='same', strides=(2,2))(x)
x= Conv2D(64,(3,3),activation='relu', padding='same', strides=(2,2))(x)
x= Conv2D(64,(3,3),activation='relu', padding='same', strides=(1,1))(x)
x= Flatten()(x)
encoder_output= Dense(zdim)(x)
model_encoder = Model(encoder_input, encoder_output)
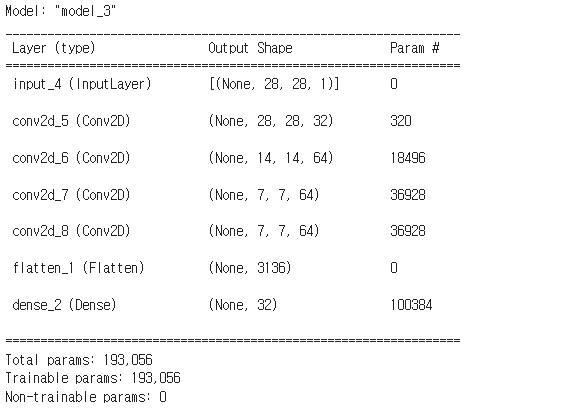
model_encoder.summary()
#오토인코더의 디코더 부분 설계
decoder_input = Input(shape=(zdim,))
x=Dense(3136)(decoder_input)
x=Reshape((7,7,64))(x)
x=Conv2DTranspose(64,(3,3),activation='relu', padding='same', strides=(1,1))(x)
x=Conv2DTranspose(64,(3,3),activation='relu', padding='same', strides=(2,2))(x)
x=Conv2DTranspose(32,(3,3),activation='relu', padding='same', strides=(2,2))(x)
x=Conv2DTranspose(1,(3,3),activation='relu', padding='same', strides=(1,1))(x)
decoder_output=x
model_decoder = Model(decoder_input, decoder_output)
model_decoder.summary()
#인코더와 디코더를 결합하여 오토인코더 모델 구축
model_input = encoder_input
model_output = model_decoder(encoder_output)
model= Model(model_input, model_output)
#오토인코더 학습
model.compile(optimizer='Adam', loss ='mse')
model.fit(x_train, x_train, epochs=5, batch_size = 128, shuffle=True, validation_data=(x_test, x_test))
#복원 실험 1: x_test를 복원하는 예측 실험
decoded_img = model.predict(x_test)
import matplotlib.pyplot as plt
n=10
plt.figure(figsize=(20,4))
for i in range(n):
plt.subplot(2,n,i+1)
plt.imshow(x_test[i].reshape(28,28),cmap='gray')
plt.xticks([]); plt.yticks([]);
plt.subplot(2, n, i+n+1)
plt.imshow(decoded_img[i].reshape(28,28),cmap='gray')
plt.xticks([]); plt.yticks([]);
plt.show()
실행결과
오토인코더가 샘플 10개를 모두 비슷하게 재현했음을 확인할 수 있다.
코드 해설
📌 오토인코더의 구조
오토인코더는 인코더와 디코더로 구성되는데, 인코더는 차원을 점점 줄이며 디코더는 차원을 점점 늘려 출력층에서 원래 차원을 회복한다.
📢 프로그램에 필요한 라이브러리
import numpy as np
from tensorflow.keras.datasets import mnist
from tensorflow.keras.layers import Input, Dense, Flatten, Reshape, Conv2D, Conv2DTranspose
from tensorflow.keras.models import Model
from tensorflow.keras import backend as K
이전까지는 층을 쌓을때 model.add(Conv2D(...))의 방식으로 코딩하였다. Sequential 방식
여기서는 x = Conv2D(...)(x) 방식으로 코딩한다. Functional API 방식
<Sequential 방식과 Functional API 방식>
아래 표는 C-C-FC 구조의 신경망을 설계하는 각각의 방식이다. Sequential 에서는 중간 결과를 따로 빼내어 사용할 방법이 없다. 따라서 출력이 하나이면 충분한 상황에서 사용한다
Functinal API 에서는 예제처럼 x1,x2,x3 이라는 서로 다른 객체에 중간 결과를 저장할 수 있음. 중간 결과에 접근하여 또 다른 데이터 흐름을 만들 수 있음. 즉, 이 방식에서는 데이터의 흐름을 여러 줄기로 나누어 신경망이 여러 개의 데이터를 출력하게 만들 수 있다.
오토인코더에서는 중간에 있는 잠복 공간에 접근해야만 생성 모델로 활용할 수 있기 때문에 Functianl API 방식을 사용함