

DQN으로 CartPole문제를 풀기 위한 신경망 학습 코드이다.
CartPole란?
좌우로 이동할 수 있는 수레 위에 막대가 꼿꼿히 선 상태에서 게임 시작
그냥 두면 쓰러지므로 수레를 왼쪽/오른쪽으로 재빨리 움직여 균형을 잡음
목표는 막대를 쓰러트리지 않고 오래 유지하는 것
이에 대한 자세한 내용은 아래 게시물 목차 5.2 확인
08) 강화 학습과 게임 지능 - 파이썬으로 배우는 인공지능
1 강화학습의 원리와 응용 1.1 다중 손잡이 밴딧 문제 여러 손잡이 중 하나를 선택해 1달러를 넣고 당기면 동전을 먹거나 2달러를 내놓는 기계 플레이어는 1달러를 잃거나 1달러를 따게 됨 손잡이
haystar.tistory.com
🎲 Q러닝 학습에 사용되는 행동가치함수 $q$를 개선하는 공식
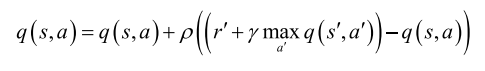
전체 코드
import numpy as np
import random
import gym
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.optimizers import Adam
from collections import deque
#하이퍼 매개변수
rho=0.9 # 학습률
lamda=0.99 # 할인율
eps=0.9 #엡실론
eps_decay=0.999 #엡실론 감소 비율
batch_siz=64 #리플레이 메모리에서 샘플링할 배치 크기
n_episode=100 #학습에 사용할 에피소드 개수
#신경망 설계 함수
def deep_network():
mlp=Sequential()
mlp.add(Dense(32,input_dim=env.observation_space.shape[0], activation='relu'))
mlp.add(Dense(32, activation='relu'))
mlp.add(Dense(env.action_space.n, activation='linear'))
mlp.compile(loss='mse', optimizer='Adam')
return mlp
#DQN 학습
def model_learning():
mini_batch=np.asarray(random.sample(D, batch_siz))
state= np.asarray([mini_batch[i,0] for i in range(batch_siz)])
action=mini_batch[:,1]
reward =mini_batch[:,2]
state1= np.asarray([mini_batch[i,3] for i in range(batch_siz)])
done=mini_batch[:,4]
target=model.predict(state)
target1=model.predict(state1)
for i in range(batch_siz):
if done[i]:
target[i][action[i]]=reward[i]
else:
target[i][action[i]]+=rho*((reward[i]+lamda*np.amax(target1[i]))-target[i][action[i]]) #식 19
model.fit(state,target,batch_size=batch_siz, epochs=1, verbose=0)
env=gym.make("CartPole-v0")
model=deep_network()
D=deque(maxlen=2000)
scores=[]
max_steps=env.spec.max_episode_steps
#신경망 학습
for i in range(n_episode):
s=env.reset()
long_reward=0
while True:
r=np.random.random()
eps=max(0.01, eps*eps_decay)
if(r<eps):
a=np.random.randint(0, env.action_space.n)
else:
q=model.predict(np.reshape(s,[1,4]))
a=np.argmax(q[0])
s1, r, done,_ =env.step(a)
if done and long_reward<max_steps-1:
r=-100
D.append((s,a,r,s1,done))
if len(D)>batch_siz*3:
model_learning()
s=s1
long_reward+=r
if done:
long_reward=long_reward if long_reward==max_steps else long_reward+100
print(i,"번째 에피소드의 점수:",long_reward)
scores.append(long_reward)
break
if i>10 and np.mean(scores[-5:])>(0.95*max_steps):
break
#신경망 저장
model.save("./cartpole_by_DQN.h5")
env.close()
import matplotlib.pyplot as plt
plt.plot(range(1,len(scores)+1), scores)
plt.title('DQN scores for CartPole-v0')
plt.ylabel('Score')
plt.xlabel('Episode')
plt.grid()
plt.show()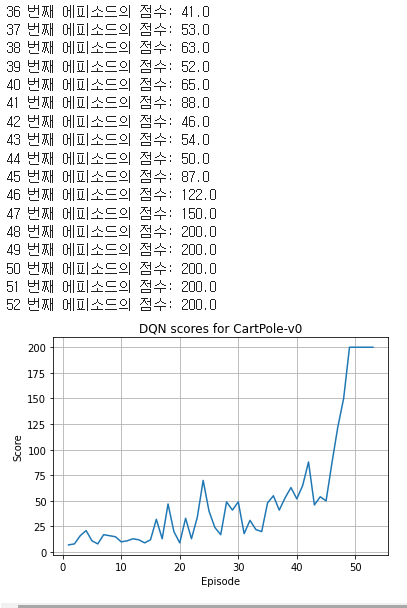
등락을 반복하다가 48번째 에피소드부터 안정적으로 200점 달성!
이때 수렴조건을 만족하여 루프를 탈출하고 프로그램 종료
코드 해설
먼저, 학습을 위해 설정된 하이퍼 파라미터는 다음과 같다.
rho=0.9 # 학습률
lamda=0.99 # 할인율
eps=0.9 #엡실론
eps_decay=0.999 #엡실론 감소 비율
batch_siz=64 #리플레이 메모리에서 샘플링할 배치 크기
n_episode=100 #학습에 사용할 에피소드 개수
이제 코드분석을 해보자!
은닉층이 2개인 다층 퍼셉트론을 만들어 반환하는 함수
def deep_network():
mlp=Sequential()
mlp.add(Dense(32,input_dim=env.observation_space.shape[0],activation='relu'))
mlp.add(Dense(32,activation='relu'))
mlp.add(Dense(env.action_space.n,activation='linear'))
mlp.compile(loss='mse',optimizer='Adam')
return mlp이때, 주의할 것은
mlp.add(Dense(32,input_dim=env.observation_space.shape[0],activation='relu'))여기서 input_dim 매개변수를 env.observation_space로 절정했다는 것!
이 문제를 위한 입력벡터는 요소가 4개인데 이 정보가 env.observation_space.shape[0]에 들어있음
CartPole의 상태 $s = $ (수레 위치, 수레 속도, 막대 각도, 막대 각속도)
마찬가지로,
mlp.add(Dense(env.action_space.n,activation='linear'))
여기서도 첫번째 매개변수는 출력 벡터의 크기인데, 이 정보도 env.action_space.n에 들어있음
또한, 활성함수를 linear로 설정한 이유는 누적 보상을 출력해야 하기 때문
softmax로 바꾸면 [0,1]사이의 확률값으로 변환하므로 누적 보상액을 제대로 추정하지 못한다.
DQN의 핵심 아이디어를 코딩한 함수
def model_learning():
mini_batch=np.asarray(random.sample(D,batch_siz))
state=np.asarray([mini_batch[i,0] for i in range(batch_siz)])
action=mini_batch[:,1]
reward=mini_batch[:,2]
state1=np.asarray([mini_batch[i,3] for i in range(batch_siz)])
done=mini_batch[:,4]
target=model.predict(state)
target1=model.predict(state1)
for i in range(batch_siz):
if done[i]:
target[i][action[i]]=reward[i]
else:
target[i][action[i]]+=rho*((reward[i]+lamda*np.amax(target1[i]))-target[i][action[i]]) # Q 러닝(식 (9.19))
model.fit(state,target,batch_size=batch_siz,epochs=1,verbose=0)
이 함수도 자세히 살펴보면
mini_batch=np.asarray(random.sample(D,batch_siz))
state=np.asarray([mini_batch[i,0] for i in range(batch_siz)])
action=mini_batch[:,1]
reward=mini_batch[:,2]
state1=np.asarray([mini_batch[i,3] for i in range(batch_siz)])
done=mini_batch[:,4]이 부분은 리플레이 메모리 D에서 미니배치를 랜덤하게 샘플링한 다음에 미니배치에 저장되어 있는
현재 상태(state), 행동(action), 보상(reward), 다음 상태(state1), 에피소드 끝 여부(done)를 추출한다.
target=model.predict(state)현재 상태 state를 신경망에 입력해 예측 수행
target1=model.predict(state1)다음 상태 state1을 신경망에 입력해 예측 수행
for i in range(batch_siz):
if done[i]:
target[i][action[i]]=reward[i]
else:
target[i][action[i]]+=rho*((reward[i]+lamda*np.amax(target1[i]))-target[i][action[i]]) # Q 러닝미니배치에 있는 샘플 각각에 대해 에피소드의 끝에 해당하면 reward를 target에 저장
그렇지않으면 Q러닝식을 적용한 결과를 target에 저장
model.fit(state,target,batch_size=batch_siz, epochs=1, verbose=0)state와 target을 훈련집합의 특징벡터와 레이블로 활용해 fit함수를 적용하여 학습
epochs는 1로 설정하여 세대는 단 한번만 반복
이제 함수정의는 끝났고 메인 프로그램의 시작이다.
env=gym.make("CartPole-v0")CartPole-v0에 해당하는 env객체를 생성
model=deep_network()
D=deque(maxlen=2000)다층 퍼셉트론 모델을 생성하여 model객체에 저장한 후
리플레이 메모리로 쓸 객체 D를 생성한다.
deque ▶ 꽉찬 상태에서 새로운 요소 삽입 시 먼저 들어온 원소를 삭제함
scores=[]scores는 에피소드의 누적 보상액을 저장할 리스트
max_steps=env.spec.max_episode_stepsCartPole-v0문제가 허용하는 최대 에피소드 길이를 알아냄 (200)
신경망 학습
for i in range(n_episode):
s=env.reset()
long_reward=0
while True:
r=np.random.random()
eps=max(0.01, eps*eps_decay)
if(r<eps):
a=np.random.randint(0, env.action_space.n)
else:
q=model.predict(np.reshape(s,[1,4]))
a=np.argmax(q[0])
s1, r, done,_ =env.step(a)
if done and long_reward<max_steps-1:
r=-100
D.append((s,a,r,s1,done))
if len(D)>batch_siz*3:
model_learning()
s=s1
long_reward+=r
if done:
long_reward=long_reward if long_reward==max_steps else long_reward+100
print(i,"번째 에피소드의 점수:",long_reward)
scores.append(long_reward)
break
if i>10 and np.mean(scores[-5:])>(0.95*max_steps):
break허용된 에피소드 개수만큼 반복함 (종료조건)
이 코드도 자세히 살펴보자🤔
s=env.reset()
long_reward=0env를 reset하고 누적보상액 초기화 (새로운 에피소드 시작)
이 이후에 나온 while문 내의 구문이 에피소드 하나를 처리하는 부분임
r=np.random.random()
eps=max(0.01, eps*eps_decay)
if(r<eps):
a=np.random.randint(0, env.action_space.n)
else:
q=model.predict(np.reshape(s,[1,4]))
a=np.argmax(q[0])그 중 이부분은 현재 상태 s에서 행동 a를 결정하는데 $\epsilon$탐욕을 적용하는 부분이다.
$\epsilon$값은 eps변수에 저장해놓았고 eps 비율만큼 랜덤하게 1-eps만큼은 현재 상태 s를 신경망에 입력하여 예측한 결과를 보고 최적 행동 a를 결정
즉 이 부분은 행동 a를 어떻게 결정할지에 대한 것
s1, r, done,_ =env.step(a)위에서 행동 a를 결정하면 step함수로 실행하여 다음 상태 s1, 보상 r, 에피소드의 끝 여부 done을 얻는다
if done and long_reward<max_steps-1:
r=-100에피소드가 max_steps에 도달하지 못한 채 중간에 끝나면 실패했다고 간주 (보상을 -100으로)
D.append((s,a,r,s1,done))새로 만든 샘플을 리플레이 메모리(D)에 추가함
if len(D)>batch_siz*3:
model_learning()model_learning함수를 호출하여 신경망을 학습하는데
이때 조건은, 리플레이 메모리가 일정 크기가 되기 전에는 적용X
∵ 훈련 집합이 충분히 수집되지 않았다고 판단
s=s1
long_reward+=r다음 상태를 현재 상태로 대치하고 누적 보상액 갱신
if done:
long_reward=long_reward if long_reward==max_steps else long_reward+100
print(i,"번째 에피소드의 점수:",long_reward)
scores.append(long_reward)
break에피소드가 끝난 경우를 처리함
에피소드가 중간에 실패로 끝냈다면 위에서 100만큼 삭감했기 때문에, 몇 스텝인지 출력하기 위해 100을 다시 더해서 출력함
if i>10 and np.mean(scores[-5:])>(0.95*max_steps):
break멈춤조건에 도달하지 못하더라도 수렴했다면 루프를 탈출한다.
수렴? 최근 에피소드 5개의 누적 보상액 평균이 최대 보상액의 95% 초과
model.save("./cartpole_by_DQN.h5")나중에 사용할 목적으로 신경망 정보를 h5파일 형식으로 저장
참고교재 파이썬으로 만드는 인공지능 - 한빛미디어