

훈련집합은 꾸준히 성능이 개선되지만, 검증 집합에선 성능 개선이 없다?
= 과잉 적합 발생!
이런 상황에 조기멈춤(early stopping)이라는 규제기법을 적용하면 효과적이다.
조기멈춤이란 훈련 집합에 대해 덜 수렴했더라도,
검증 집합에 대한 성능 개선이 더 없거나 퇴화한다면 학습을 마치는 전략
전체 코드
조기 멈춤을 위해 텐서플로에서 EarlyStopping 클래스를 제공함
early= EarlyStopping(monitor='val_accuracy', patience=5, restore_best_weights=True)
조기멈춤으로 LSTM 학습 중단
from tensorflow.keras.datasets import imdb
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense,Flatten, Embedding
from tensorflow.keras import preprocessing
from tensorflow.keras.callbacks import EarlyStopping
dic_siz = 10000 #사전 크기
sample_siz=512 #샘플 크기
#간소한 버전의 IMDB 읽기
(x_train, y_train), (x_test, y_test) = imdb.load_data(num_words = dic_siz)
embeded_space_dim=16 #16차원 임베딩 공간
x_train = preprocessing.sequence.pad_sequences(x_train, maxlen=sample_siz)
x_test = preprocessing.sequence.pad_sequences(x_test,maxlen=sample_siz)
early= EarlyStopping(monitor='val_accuracy', patience=5, restore_best_weights=True)
#신경망 모델 설계와 학습
embeded = Sequential()
embeded.add(Embedding(input_dim=dic_siz, output_dim=embeded_space_dim, input_length=sample_siz))
embeded.add(LSTM(units=32))
embeded.add(Dense(1, activation = 'sigmoid'))
embeded.compile(loss= 'binary_crossentropy', optimizer = 'Adam', metrics=['accuracy'])
hist = embeded.fit(x_train, y_train, epochs=20, batch_size=64,validation_split=0.2, verbose=1, callbacks=[early])
#모델 평가
res = embeded.evaluate(x_test, y_test, verbose=0)
print("정확률은",res[1]*100)
import matplotlib.pyplot as plt
#학습 곡선
plt.plot(hist.history['accuracy'])
plt.plot(hist.history['val_accuracy'])
plt.title('Model accuracy')
plt.ylabel('Accuracy')
plt.xlabel('Epoch')
plt.legend(['Train', 'Validation'], loc='best')
plt.grid()
plt.show()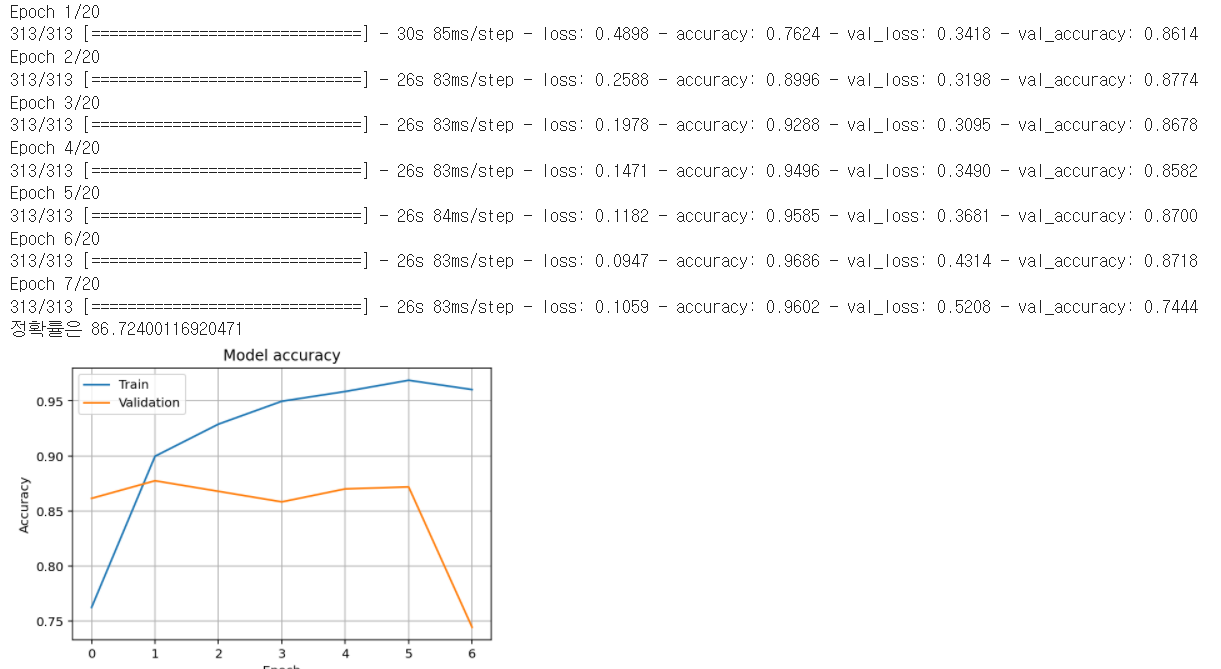
코드에서 설정된 epoch 수는 20이지만 7세대에서 학습이 멈춤
코드 해설
early= EarlyStopping(monitor='val_accuracy', patience=5, restore_best_weights=True)조기 멈춤 조건을 설정한다.
매개변수 patience=5는 다섯 세대 동안 성능 향상이 없을 때 멈추라는 지시
너무 작게 설정하면 이후에 좋은 성능이 나올 가능성을 놓치게 됨!
매개변수 restore_best_weights는 가장 높은 성능을 발휘했을 때의 가중치를 취하는 지시이다.
False로 설정하면 멈춤 순간의 가중치를 취함
hist = embeded.fit(x_train, y_train, epochs=20, batch_size=64,validation_split=0.2, verbose=1, callbacks=[early])callbacks은 조기멈춤을 적용하고, validation_split=0.2는 훈련 집합의 20%를 떼어 검증집합으로 사용하라는 지시
이때 shuffle은 생략 되었는데 기본 값이 True임 (랜덤하게 20%를 떼어냄)
참고교재 파이썬으로 만드는 인공지능 - 한빛미디어