

논문정보
임미영, 강신재. (2019). 도메인 정보가 강화된 워드 임베딩을 사용한 한국어 텍스트 생성.
한국지능시스템학회 논문지, 29(2), 142-147.
논문요약
최근 RNN이 언어 모델링에서 두각을 나타내고 있다. 정형화된 텍스트 뿐만 아닌 소설,수필과 같은 창의적인 텍스트 생성을 위한 시스템에도 쓰임. 다만 한국어 연구는 부족한데, 영어보다 어휘의 쓰임새나 형변환이 다양하기 때문.
따라서, 도메인 정보가 강화된 워드 임베딩을 이용하여 한국어 텍스트 생성 모델을 구축하였다.
기존연구
언어모델이란 말뭉치에 출현한 단어 열에 대한 확률 분포
n-1개의 단어가 주어졌을때 말뭉치에서 단어 열이 나타날 확률을 할당하여 가장 높은 확률을 가지는 단어를 생성
(데이터에 민감함 => 대화말뭉치, 학술분야 말뭉치에 따라서 생성된 문장이 다름)
<N-gram 언어 모델>
신경망 모델이 급부상하기 전에 많이 사용되던 모델.
베이즈 이론에 근거하여 해당 n-gram이 등장할 확률을 예측
장점 : 구현이 쉽고 n이 작을 때는 계산 양이 많지 않다.
단점 : n이 커질수록 자질 조합이 지수적으로 커지게 되고 요구데이터 양도 훨씬 많아짐.
OOV (out of vocabulary)에러의 경우 그 확률이 0이 되는 경우가 많다.
<초기 신경망 언어 모델과 임베딩>
N-gram 모델의 문제점을 극복하기 위해 분산형 모델로 신경망 모델이 연구되고 있음.
다음의 뉴럴 확률 언어 모델은 기본적인 신경망 언어모델로 단어 열로부터 다음 단어 예측
(but one hot vector이기 때문에 엄청난 계산양 발생)

Collobert와 Wetson은 위 모델에서 softmax층 제거 (계산양이 많기 때문)
하지만 tanh층을 계속 유지하여 여전히 많은 계산양을 피할 수 없음

Word2Vec모델에서는 계산양이 큰 은닉층을 모두 버리고 projection layer만 사용.
학습 시간이 빠르고 성능도 좋아서 가장 많이 사용되고 있음. 모델학습 방법은 두가지가 있다.
주변 단어가 주어졌을 때 목표 단어를 학습하는 방식 (CBOW)
목표 단어가 주어졌을 때 주변 단어를 학습하는 방식 (Skip-gram)
Skip-gram의 성능이 더 나은것으로 보고된다.

임베딩을 통해 벡터를 몇백차원으로 표현할 수 있어 기존 문제들을 효율적으로 해결할 수 있게 되어 언어 모델에서 단어 임베딩층은 필수가 됨.
<RNN과 Encoder - Decoder 모델>
순환신경망의 특징은 앞 단계에서 생성된 단어를 다시 뒤 단계의 입력으로 사용
자연어 생성은 앞에서 생성된 단어가 생성될 단어에 영향을 미치기 때문에 RNN 주로 사용
LSTM과 GRU를 많이 사용하는데 하나의 예제가 들어오면 학습 여부를 결정하고, 학습한다면 얼마나 학습할 것인지 문제를 결정한다.
Encoder-Decoder 모델은 주목할만한 성능에 힘입어 언어 생성분야에서도 응용하게 됨.

<주요 난점>
주로 어휘에서 온다. 우리 생활과 밀접한 관계가 있는 뉴스와 특정 시대에 저작된 소설 등은 사용하는 어휘가 서로 다름. OOC 문제가 잘 발생할 수 있다. 만약 전체 어휘를 설정하면 학습이 제대로 되지 않거나 시간이 많이 걸림.
이 문제를 완화하기 위해 <UNK>태그를 사용함.
▷빈도수가 낮다? = 중요도가 낮다! => <UNK>로 태깅하여 출력층 크기 감소
<창의적 텍스트 생성>
기존에선 뉴스와 성경 데이터로 실행하였음
뉴스 : 정형적 데이터라 학습에 용이 but 일정한 틀을 가지고 있어 창의적 텍스트와는 다름
성경 : 현대에는 잘 사용하지 않는 단어가 자주 등장.
따라서 뉴스나 성경 텍스트에 비하여 스타일이 자유롭고 이야기마다 스타일이 다른 창의적 텍스트를 제대로 학습할수 있을까?
본 논문에서는 동화 데이터 사용하여 언어 모델링, 문장이 문법에 맞게 생성되는지, 그 가능성을 알아본다.
언어모델이 데이터에 민감하다는 특성에 근거하여 두가지의 모델을 제안함
1. 동화 말뭉치만 학습시킨 단어 임베딩 사용
2. 대규모 일반 말뭉치를 사용한 기본 임베딩 => 동화 말뭉치를 사용하여 학습
(결과 성능은 모델1이 더 좋음)
실험
<제안 모델>
기본 모델 그림은 다음과 같다.

이 중에서 임베딩 층을 학습하는 방법은 다음과 같다.

모델1 : 도메인 말뭉치만을 이용
모델 2: 대용량의 일반 말뭉치로부터 초기 가중치를 먼저 학습하고 도메인 말뭉치를 이용하여 임베딩 층을 갱신 학습
LSTM 크기와 임베딩 층의 크기는 모두 100, 어휘의 최소 빈도수는 2<실험 환경>
21세기 세종 말뭉치에서 <아동/동화/교육자료>로 분류된 자료 22편 사용.
임베딩 층의 가중치 학습을 위해선 Gensim라이브러리 사용
모델 구현은 Keras 사용
GPU는 NVIDIA GTX 1080 사용
다음은 모델 별 말뭉치 개요이다.
모델 1 - 도메인 말뭉치 개요
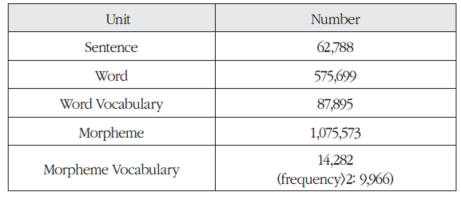
모델 2 - 대용량 일반 말뭉치 개요

<실험 결과>
생성물의 평가 척도로는 혼잡도(Perplexity) 사용


본 실험에서는 두번째 수식 사용. 수치가 낮을수록 좋은 모델임.
결과는 첫번째 모델의 혼잡도가 두 번째 모델보다 낮다.
(첫번째 모델이 도메인 말뭉치에서 비교적 보편적으로 등장하는 단어 시퀀스를 보다 잘 생성했음)
모델 2의 결과가 보다 추상적이고 비유적인 표현이 생성됨.
창의성 측면에서는 모델2가 낫지만 전체적인 통사적 틀에 맞춰 생성하는 부분은 모델1이 나음.
모델 1- 결과

모델 2 - 결과

결론
도메인 정보가 강화된 워드 임베딩을 적용하여 한국어 창의적 텍스트 생성 모델 구현.
단어 임베딩 층을 어떤 장르의 데이터를 주로 이용하여 학습하는가에 다라 생성되는 문장의 스타일이 달라짐.