논문정보
Delving into Multimodal Prompting for Fine-grained Visual Classification
Delving into Multimodal Prompting for Fine-grained Visual Classification
Fine-grained visual classification (FGVC) involves categorizing fine subdivisions within a broader category, which poses challenges due to subtle inter-class discrepancies and large intra-class variations. However, prevailing approaches primarily focus on
arxiv.org
Underline | Delving into Multimodal Prompting for Fine-Grained Visual Classification | VIDEO
Delving into Multimodal Prompting for Fine-Grained Visual Classification | VIDEO
On-demand video platform giving you access to lectures from conferences worldwide.
underline.io
논문정리
Abstract
FGVC는 같은 카테고리 내에서 미세한 하위 분류를 구별하는 작업으로, 클래스간 미세한 차이와 클래스 내 큰 변동성 때문에 어려움을 겪음
기존 방법들은 주로 uni-modal 시각 개념에 집중하고 있음
cross-modal의 설명 능력을 활용하여 FGVC 문제 해결
새로운 다중 모달 프롬프트 솔루션 MP-FGVC를 제안
제안 방법
Multimodal prompts scheme
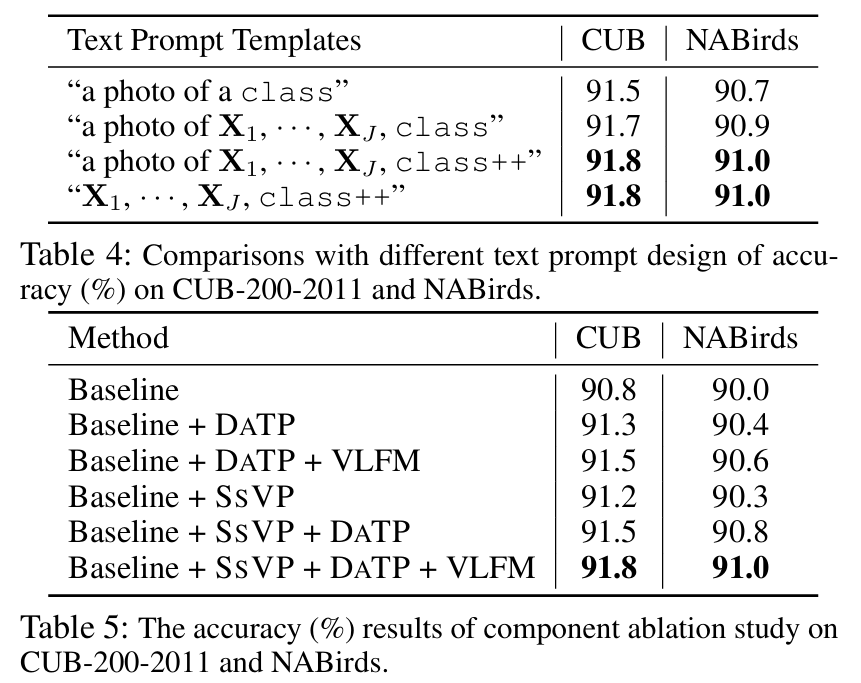
- SSVP(Subcategory-specific Vision Prompt) : 시각적 관점에서 하위 카테고리별 차이 강조
- DATP(Discrepancy-aware Text Prompt) : 언어적 관점에서 하위 카테고리별 차이 강조
Multimodal adaptation scheme
- 시각과 텍스트 요소를 의미적 공간에서 정렬하여 추론
- VLFM(Vision-Language Fusion Model)을 통해 시각-언어 융합 모듈로 FGVC 성능 향상
두 단계 최적화 전략을 통해 CLIP 모델 효과적 활용 + FGVC 적응
즉, FGVC 문제에 멀티모달 접근을 적용하고 기존 모델의 한계 극복
Introduction
FGVC는 주어진 상위 카테고리 내에서 서로 다른 하위 카테고리를 분류하는 것을 목표로 함
Inter-class variations과 intra-class variations에 의해 일반적인 분류 작업보다 더 도전적임
Inter class variations : 유사한 하위범주들 간의 미세한 차이로 인해 발생
Intra class variations : 위치, 크기, 변형 등의 요인으로 발생
새의 종을 구별하는 작업에서 인간은 눈 모양, 지느러미의 모양, 꼬리 부분의 색상과 같은 특징에 기반한 차이를 인식
딥러닝 방법은 크게 feauter encoding방법과 part localization 방법으로 나뉨
part localization 방법이 인간의 인식과 일치하는 특성때문에 관심을 많이 받음
미세한 차이가 주로 객체의 특정 부분에 존재하기 때문!
CNN 모델은 weakly supervisd 방식으로 FGVC에서 좋은 성능을 달성하였지만 이미지 내에서 작고, 관련 없는 영역에만 집중하는 경향이 있어, 포착된 차이에 대한 robustness와 discriminability가 부족함
최근에 ViT와 같은 모델들이 이미지 분류에서 우수한 성과를 보여주며 FGVC에서도 사용됨
ViT는 패치를 로컬 파트로 처리하고, self attention을 통해 장거리 의존성을 모델링할 수 있어 FGVC에 유리함
하지만 데이터셋의 크기가 제한적이어서 최적화 과정에서 불안정성이 나타날 수 있고, 시각적 표현에 지나치게 의존
인간의 시각 인식은 top-down cognitive penetrability이라는 메커니즘을 통해 작동
우리의 언어적 지식(외향에 대한 설명)이 시각적 자극을 처리하는 방식에 영향을 미쳐, 물체를 더 정교하게 구별하는 데 도움을 줌
이를 바탕으로 large scale vision lanague(VL)모델이 개발되어, 시각적 표현을 고차원의 언어적 설명과 연결하는 기능이 가능해짐
CLIP 모델을 사용해 프롬프트 기법을 통해 FGVC에서의 가능성을 확인
기존의 프롬프트 기법들은 주로 상위 카테고리의 의미를 포착하는데 중점을 두어 하위 카테고리 간의 미세한 차이를 반영하지 못함
FGVC 데이터셋에는 주석(annotation)이 부족하여, VL모델을 FGVC 작업에서 사용하는데 한계가 있었음
CLIP 모델을 FGVC에 적용하려는 연구들이 있었지만, 이러한 방법들은 주로 open-set senario에서 시각적 개념을 텍스트 설명과 연결하는데 초점을 둠
Open-set 시나리오에서는 새로운 클래스나 카테고리가 예기치 않게 등장하는 상황에 대비하는 것을 목표로 하기 때문에,
모델이 주로 학습하지 않은 클래스에 대응할 수 있는 일반화된 성능을 발휘하도록 설계
FGVC 작업에서는 이미 정의된 (closed-set) 하위 카테고리 내에서의 미세한 차이를 정확하게 포착하는 게 핵심
open-set 시나리오에 집중하다 보면, 모델이 하위 카테고리 내의 미세한 차이에 충분히 집중하지 못하고, 새로운 클래스 인식에 대한 일반화된 능력에 더 치중할 수 있음
따라서, closed-set senrio에서 하위 카테고리 간 미세한 차이를 잘 반영할 수 있도록 어떻게 사전 학습된 CLIP 모델을 활용하는지에 대한 연구가 필요함
이 논문은 MG-FGVC라는 멀티모달 프롬프트 방법을 제안하여 CLIP 모델을 기반으로 FGVC 작업을 개선
MP-FGVC는 multimodal prompts scheme와 multimodal adaptation scheme를 도입
- multimodal prompts scheme: 하위 카테고리 간의 차이를 강조하는 시각적 및 언어적 프롬프트를 생성하여, 모델이 중요한 차이점에 집중할 수 있도록 함
- Subcategory-specific Vision Prompt(SsVP): 중요한 이미지 패치를 선택하여 하위 카테고리 간 중요한 시각적 차이 식별
- Discrepancy-aware Text Prompt(DaTP): 상위 카테고리 이름을 기반으로 하위 카테고리별 차이를 설명하는 텍스트 생성
- multimodal adaptation scheme: 시각적 프롬프트와 언어적 프롬프트를 의미적 공간에 정렬시켜, Vision-Language Fusion Model(VLFM)을 통해 cross-modal 협력 추론을 가능하게 함
하지만 FGVC 데이터셋에 대한 특정 주석이 없고 하위 카테고리의 레이블이나 인덱스만 사용할 수 있기 때문에 supervision이 제한적이라는 점에서 2단계 훈련 방법을 제안함
- 1단계 : 사전학습된 CLIP의 텍스트 인코더를 고정한 상태에서, multimodal prompt scheme을 통해 이미지 인코더를 최적화
- 2단계: 이미지 인코더, 텍스트 인코더, multimodal adaptation scheme을 고정하며, 이들은 하위 카테고리별 시각적 임베딩과 discrepancy-aware 텍스트 임베딩을 제공하여 멀티모달 프롬프트를 효과적으로 활용할 수 있도록 함
첫번째 단계에서 구성요소들이 이미 최적화되어있기 때문에, 두번째 단계에서는 더 이상 이 구성요소들을 학습(파라미터 업데이트)하지 않고, 이미 학습된 것을 바탕으로 최종적으로 모델의 출력을 조정하거나 다른 부분을 최적화
즉, 첫번째 단계에서 얻어진 최적의 파라미터를 유지하면서 모델의 성능을 더 향상시킴
Related Work
skip....
Preliminary
<Review of Vision Transformer(ViT)>
skip
<Review of CLIP>
CLIP은 이미지와 텍스트를 모두 이해하고, 두 가지 정보를 공통의 특징 공간에서 표현할 수 있는 Vision-Language 모델
이미지 인코더
- Image Encoder
I(⋅) - Text Encoder
T(⋅)
프롬프트 학습은 모델이 특정 텍스트를 보다 효과적으로 이해하도록 돕는 방법
CLIP이 텍스트를 해석할 때, 입력된 이미지와 관련된 정보를 더 잘 파악하도록 유도함
이미지-텍스트 쌍에 대한 배치를
이미지 인코더
CLIP은 이미지와 텍스트 간의 constrative learning을 통해 이미지와 텍스트의 임베딩 공간을 정렬함
Image-to-text constrative lossLi2t
Text-to-image constrative lossLt2i
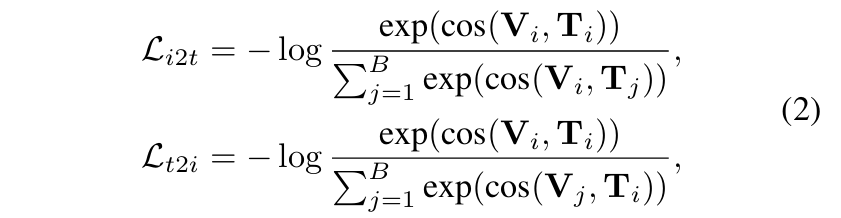
: 이미지 임베딩 Li2t 와 Vi 간의 유사성을 극대화하고, 다른 텍스트 임베딩 Ti 와의 유사성을 최소화하여 올바른 이미지-텍스트 매칭을 학습 Tj : 텍스트 임베딩 Lt2i 와 올바른 이미지 임베딩 Ti 간의 유사성을 극대화하고, 다른 이미지 임베딩 Vi 와의 유사성을 최소화함 Vj
cos: 코사인 유사도 함수 (⋅,⋅)
Methodology
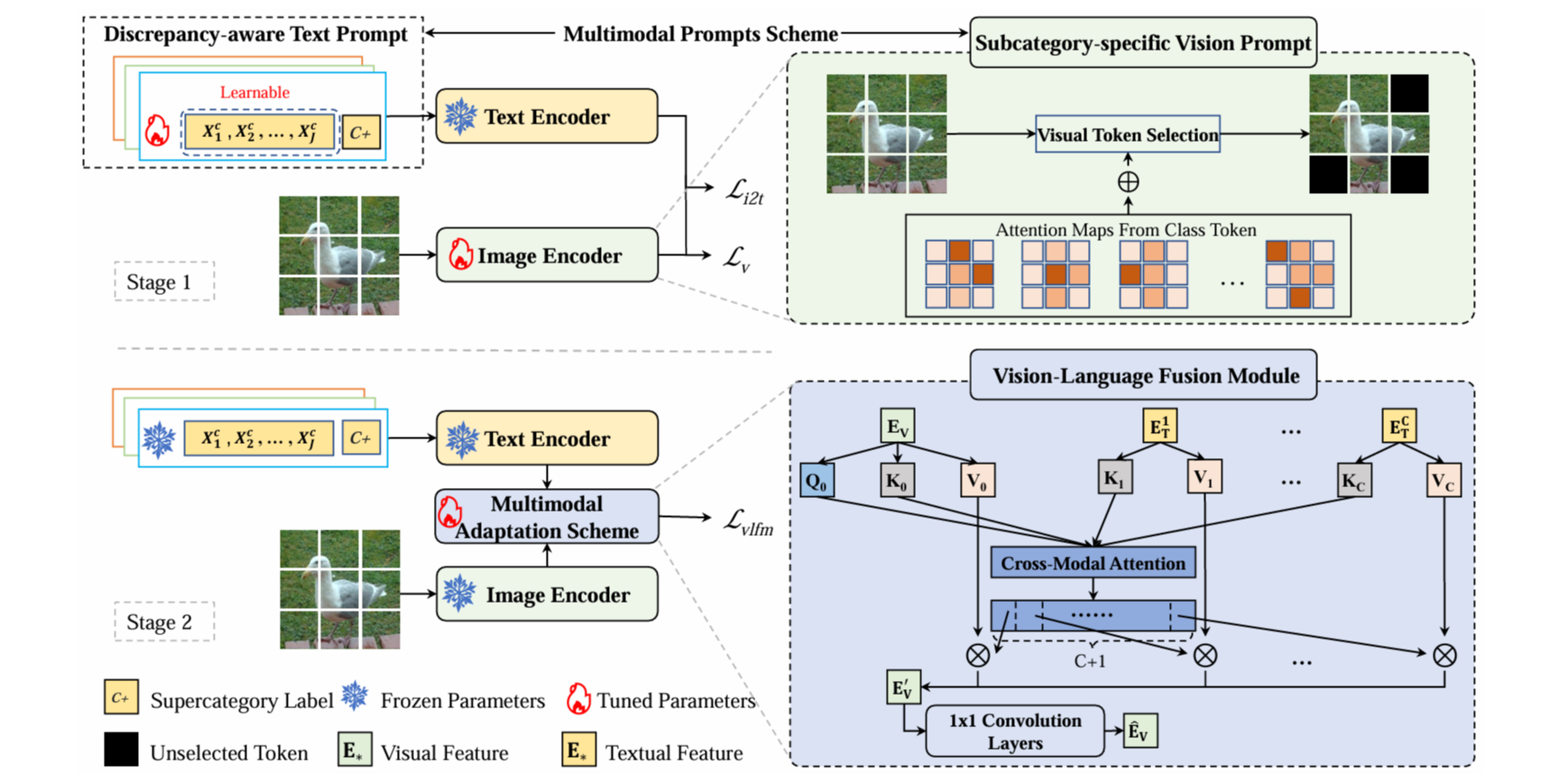
그림 1은 MP-FGVC 모델의 전체 파이프라인을 설명함
이 모델은 두 개의 주요 구성 요소로 이루어짐
multimodal prompts scheme, multimodal adaptation scheme
두 가지 모두 2단계 훈련 과정을 통해 사전훈련된 CLIP모델을 사용하여 구성
<Multimodal Prompts Scheme>
미묘하지만 중요한 차이점을 효과적으로 포착하는 것이 FGVC에 중요하다는 것으로 알려져있다.
기존의 CLIP모델에서 사용되는 ViT는 원래 상위 카테고리 수준의 시각적 개념을 인식하도록 설계되었기 때문에, 하위 카테고리 간의 미세한 차이를 잘 포착하지 못한다는 한계가 있음
이 문제를 해결하기 위해 subcategory-specific vision prompt, discrepancy-aware text prompt로 구성된 multimodal prompts scheme를 제안함
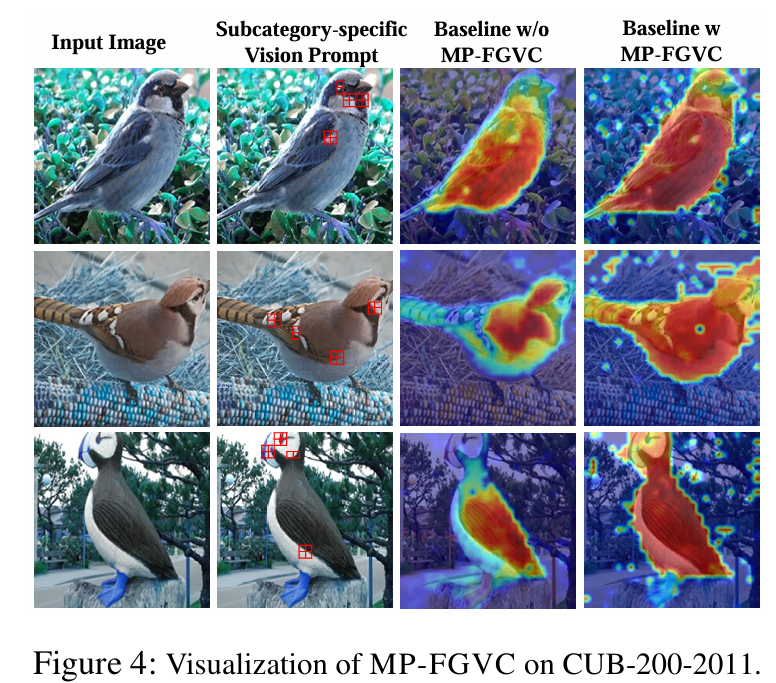
Subcategory-specific Vision Prompt
FGVC 작업은 매우 유사한 하위 카테고리 간의 구별되는 영역을 정확히 찾아내는 것이 중요
ViT는 모든 이미지 패치를 동일하게 취급하여, 불필요한 패치 정보가 포함되는 탓에 최종 분류에 부정적인 영향을 미칠 수 있음
▷ 이러한 한계때문에 사전훈련된 CLIP모델을 FGVC 작업에서 사용하기가 제한되었음
SsVP는 ViT의 penultimate layer에 적용되어 최종 레이어의 입력을 조정하는 매개변수 없는(parmeter-free) 연산
이 기법의 목적은 구별되는 영역을 정확하게 찾아내어, 최종 층에서 모델이 이러한 미세한 차이를 더 반영하도록 돕는 것
중요도 점수는 MHSA(Multi-Head Self-Attention) 메커니즘에서 생성되며, 이미지 패치 중 discrimative tokens을 선택함
MHSA는 여러(M) 개의 헤드를 사용하여, 이미지의 다양한 부분에 주의를 분산시킴. 이때 각 헤드는 서로 다른 패치에 주의를 집중하게 됨
그림 1에서 보듯, 모든 헤드의 중요도 점수를 합산한 후, 어텐션 점수가 높은 순서대로 상위
$\mathbf{id} = \mathtt{TopK}(\sum_{i=1}^{M} \mathbf{A}^i ) \in \mathbb{Z}^K$
모든 토큰을 동일하게 취급하기 보다는선택된 k개의 토큰과 클래스 토큰을 결합하여 ViT의 마지막 층에 입력으로 사용
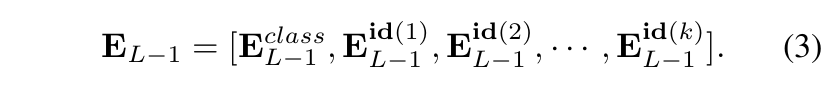
마지막 트랜스포머 레이어의 전체 입력 시퀀스를 객체의 식별 영역만을 포함하는 토큰으로 대체하여, 이미지 인코더가 배경이나 공통된 특징과 같은 덜 구별되는 영역을 무시하고, 미묘한 차이에 집중하도록 함
Discrepancy-aware Text Prompt
기존의 CLIP과 같은 VL모델들이 사용하는 프롬프트 전략은 주로 상위카테고리 수준의 의미를 포착하는데 중점을 둠
이는 미세한 시각적 차이를 구별하는 데 필요한 상세한 시각적 불일치를 제대로 반영하지 못함
이러한 접근 방식으로 인해, 텍스트 프롬프트에 구체적인 하위 카테고리 이름이 제공되더라도 FGVC 작업에서 하위 카테고리별 시각적 차이를 정확히 인식하는 데 제약이 생김
하위카테고리의 시각 프롬프트와 의미적 일관성을 유지하면서, 텍스트 정보의 부족을 보완하는 DaTP 기법을 제시
이를 통해, 자동으로 하위 카테고리 간 더 자세하게 시각적 차이(visual discrepancy)에 대한 적절한 텍스트 설명을 자동으로 생성
DaTP는 학습 가능한 텍스트 토큰셋을 사전학습하여 텍스트 정보를 보완함
이 텍스트 프롬프트 템플릿은 CLIP모델의 텍스트 인코더
템플릿은 $P_{class}^c=[X_1,X_2,⋯ ,X_j,⋯ ,X_J,class^{++}], c \in \{1,\cdots,C\} $로 설계됨
: 하위 카테고리 개수 c : j번째 학습가능한 토큰 Xj∈RD : 토큰 벡터의 차원 D : 하위카테고리 라벨(bird/dog/food/...)이 아닌 상위 카테고리(bird, dog)의 라벨에서 생성된 워드 임베딩 class++∈RD
각 텍스트 프롬프트
학습 가능한 프롬프트 벡터와 상위 카테고리 이름이 결합하여 텍스트 인코더가 이해할 수 있는 discrepancy-aware 텍스트 프롬프트를 구성함
<Multimodal Adaptation Scheme>
Multimodal Adaptation Scheme의 목적은 사전훈련된 CLIP모델이 하위 카테고리 간의 미세한 차이를 잘 인식할 수 있도록, 시각적 프롬프트와 텍스트 프롬프트에서 민감도를 높이기 위함임
이를 위해 추가적으로 Vsion-Language Fusion Module(VLFM)을 도입하여 시각적 프롬프트와 텍스트 프롬프트를 공통의 의미적 공간에서 정렬함
Vision-Language Fusion Module
VLFM은 먼저 시각적 프롬프트와 텍스트 프롬프트를 공유된 의미공간에서 정렬하고 결합하여, 두 모달리티간 협력적 추론을 가능하게 함
이 모듈은 cross-modal 어텐션 메커니즘을 사용하여 시각적 정보와 텍스트 정보를 효과적으로 통합함
ViT의 클래스 토큰을 하위 카테고리용 시각적 임베딩
학습된 텍스트 토큰을 통해 생성된 텍스트 특징은 하위 카테고리간 차이를 반영한 텍스트 임베딩
멀티모달 입력
query (), key( Q0 ), value( K0 ) V0
같은 방법으로 각 텍스트 임베딩
cross-modal 어텐션 벡터
: 임베딩 차원 D : Transpose 연산 T
cross-modal 어텐션 벡터
이는 누락된 시각적 차이를 복구하고, 차별성있고 일반적인 시각적 임베딩을 생성하는 것이 목표
VLFM에 더 완전한 차이를 통합하기 위해 2개의 1x1 컨볼루션 레이어로 구성된 translation layer (
이 레이어는
첫번째 컨볼루션 레이어는 expansion factor 4를 가지며, 확장 레이어로 작동함
두번째 컨볼루션 레이어는 특징 차원을 원래의 입력으로 다시 매핑함
Translation layer를 통해 얻어진 최종 시각적 임베딩
<Optimization>
이 논문에서는, CLIP모델을 FGVC 작업에서 멀티모달 프롬프트를 FGVC에 최대한 활용하는 것이 목임
하지만 FGVC 작업에서는 하위 카테고리 레이블이나 인덱스만 제공하여, 세부적인 시각적 차이를 이해하기 위한 구체적인 컨텍스트 설명이 부족함
따라서, 기존의 CLIP과 같은 VL모델을 FGVC 작업에 적용하기 힘들었음
이를 위해, 논문에서는 2단계 학습 전략을 제안함
이 전략은 FGVC의 하위 카테고리별 차이에 대한 민감도를 높이고, FGVC 작업에 효과적으로 적응할 수있도록 도움
The first training stage
텍스트 인코더
CLIP과 유사하게, 이미지 인코더와 텍스트 인코더를 사용하여 시각적 임베딩
그러나, 원래 텍스트 입력 대신
이때,

: one hot label y
이 손실을 최소화하여, 하위 카테고리 간 미세한 차이가 강조되는 새로운 의미적 공간으로 시각적 특징을 투영함
DaTP에서 학습가능한 텍스트 토큰을 최적화하기 위해 image-to-text constrastive loss
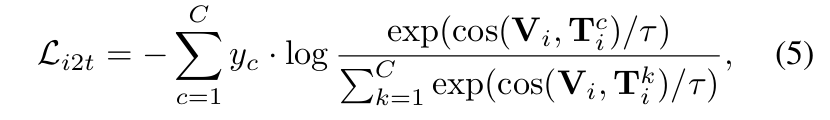
: temperature parmater, 0.07로 고정 τ
이 손실을 최소화하여, DaTP에서 생성된 텍스트 프롬프트가 시각적 차이를 반영한 설명을 제공하도록 학습
첫번째 단계의 전체 손실함수는 시각적 손실과 이미지 텍스트 대조 손실의 합으로 정의

The second training stage
두 번째 단계는 VL모델을 최적화하는데 중점을 둠
이 단계에서는 이미지 인코더와 텍스트 인코더의 파라미터를 고정시키고, VLFM만을 최적화
이전 단계에서 학습된 시각적/텍스트 임베딩을 유지하면서, 새로운 학습을 진행하지 않음
VLFM의 출력으로 얻어진
전체 손실함수는 아래와 같음
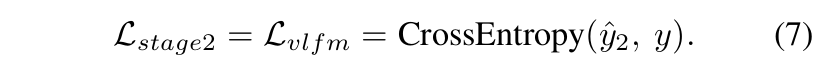
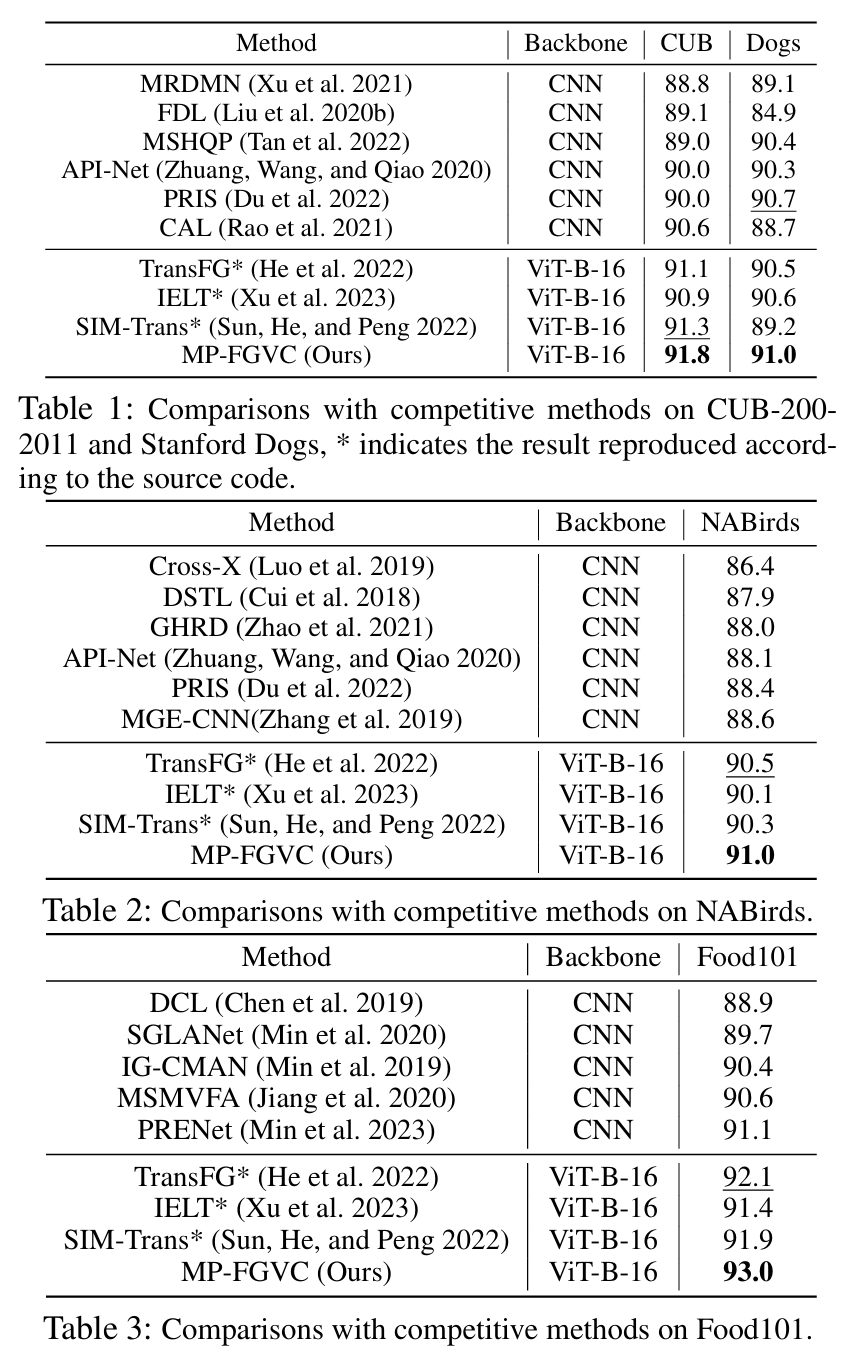
Experiments
<Dataset>
- CUB200-2011
- Stanford Dogs
- NABirds
- Food101
<Implementation details>
Imagenet21K로 사전훈련된 ViT-B-16을 활용하여 이미지 인코더로 사용
CLIP에서 사전훈련된 트랜스포머 모델을 텍스트 인코더로 사용
<성능>