

논문정보
Distract your attention: Multi-head cross attention network for facial expression recognition
Distract Your Attention: Multi-head Cross Attention Network for Facial Expression Recognition
We present a novel facial expression recognition network, called Distract your Attention Network (DAN). Our method is based on two key observations. Firstly, multiple classes share inherently similar underlying facial appearance, and their differences coul
arxiv.org
<code>
GitHub - yaoing/DAN: Official implementation of DAN
Official implementation of DAN. Contribute to yaoing/DAN development by creating an account on GitHub.
github.com
경태오빠가 추천해준 논문...
하나의 attention map에서 top-k개를 출력하는 것보다 여러 개의 어텐션맵을 동시에 생성해 내는게 나을거라고 한다.
손실함수로 각기 다른 어텐션 맵이 다른 위치를 어텐션할 수 있도록 조정한다.
레츠기릿,,,! 😙
논문정리
Abstract
본 논문에선 새로운 표정인식 네트워크, Distract your Attention Network (DAN)을 제안함
이 방법은 생물학적 이미지 인식과정에서 관찰한 두 가지 포인트에 기반함
- 여러개의 얼굴 표정 클래스들이 본질적으로 유사한 외향을 지니며 그들간의 차이가 미묘함.
- 표정은 여러개의 얼굴 영역에서 동시에 나타는데, 인식에서는 지역 특징간의 high-order interaction을 인코딩하는 접근이 필요.
DAN은 세 가지의 구성요소로 이루어져있다.
- Feature Clustering Network(FCN)
- Multi-head Attention Network (MAN)
- Attention Fusion Network (AFN)
FCN은 클래스간 분리성을 최대화하기 위해 large margin learning objective를 채택하여 강건한 특징들을 추출한다.
클래스들 사이의 간격을 최대화하는 것을 목표로
MAN은 여러개의 어텐션 헤드를 생성하여 여러 얼굴 영역에서 동시에 주의를 기울이고, 각 영역에 대한 어텐션 맵 구축
AFN은 이 특징맵들을 하나로 통합하기 전에, 다양한 얼굴 영역으로 어텐션을 분산시킨다.
Introduction
FER(Facial expression recognition)은 자동으로 표정을 인식하기 위해 컴퓨터를 사용한 기술이다.
이 연구 분야가 커지면서 굉장히 많은 표정인식 데이터셋이 등장했다.
초기 연구에선 6개의 원시 표정들을 사용 (basic emotion이라 칭하기도 함)
AN(angry), DI(disgust), FE(fear), HA(happy), SA(sad), SU(surprise)
최근 FER 데이터셋은 NE(neutral), CO(contempt)를 표정 카테고리에 추가하여 7~8개로 분류

일반적인 이미지 분류와 다른 점은, 서로 다른 얼굴 표정 클래스 간 공통적으로 강하게 나타나는 특징이 있다는 것이다.
게다가, 여러 표현들은 본질적으로 비슷한 얼굴 외향을 공유하며, 그 차이가 덜 두드러진다.
이를 해결하기 위해 CV에선 center loss의 변형을 사용하는 것이 일반적인 전략이다.
본 연구에선, Feature Clustering Network를 제안하여 center loss를 단순하고 직관적으로 확장한다.
클래스 간, 클래스 내 분산을 효과적으로 최적화함
현존 방법에 비해, 본 제안방법은 cluster center의 변형 외에 추가되는 연산이 없고 몇개의 하이퍼 파라미터만 요구한다.
Center loss
Face Recognition은 단순히 class 별로 분리하는 hyper plane을 찾는것(classification)을 넘어서 추가 클래스를 데비해 같은 클래스끼리 가까이 하고 다른클래스는 멀리 위치 시키는 mapping을 수행해야한다.
각 클래스마다 class center를 정한 후, 클래스에 속하는 샘플들을 class center와 가깝게 위치하도록 loss로 잡아줌
1. mini-batch 내에서 center를 구함
2. 매 interation마다 클래스 내의 feature 들을 averaging 하는 것으로 center를 구함
최종 Loss는 inter class간 떨어뜨리기 위한 Classification Loss, intra class내에서 뭉쳐있게 하기 위한 Center loss를 더한값으로 사용하여 Inter는 separate 하면서 동시에 intra는 compact하게 만든다.
[출처] https://mic97.tistory.com/17
FER의 독특한 점은 미묘한 로컬 로컬 변화를 포착하는 것과 통합된 종합적 표현을 획득하는 것간의 trade-off
로컬한 디테일에 집중하기 위해, 최근 논문은 어텐션 구조를 중점을 두어 좋은 결과를 얻었다.
하지만 그림1을 보면 모델이 단일 어텐션 헤드만으로 얼굴 내 여러 영역에 동시 집중하기는 어렵다.
저자는 얼굴 표정이 얼굴의 눈썹, 눈, 코, 입, 볼 등 여러 영역에서 동시에 나타난다고 보았다.
따라서 이런 생물학적 시각 인식을 기반으로 Multi-head Attention Network를 제안하였는데, 이는 여러 개의 어텐션 헤드를 생성하여 얼굴의 여러 영역에 집중한다.
이 어텐션 모듈은 공간 어텐션과 채널 어텐션을 모두 사용하여 로컬 특징간 higher-order 상호작용을 포착하는 동시에 연산 부담을 적당히 유지한다.
또한 이 논문은 종합적인 특징 벡터로 통합되기 전에 어텐션을 여러 위치로 이끄는 Attention Fusion Network (AFN)을 제안한다.
위의 아이디어를 통합하여, 표정 인식을 위한 새로운 네트워크인 Distract your Attention Network(DAN)을 제안한다.
본 방법은 여러개의 어텐션 헤드를 구현하여 겹치는 영역 없이 표정에서 유용한 부분들을 포착하도록 한다.
이 연구는 3개의 하위 네트워크 FCN, MAN, AFN으로 구성되어 있다.
구체적으론 먼저 FCN을 통해 백본 특징 임베딩을 추출하고 클러스터링함
여기서 affinity loss를 도입하여 클래스 내부 거리를 줄이고, 클래스 간 거리를 증가시키도록 한다.
그 이후, MAN을 통해 여러 개의 어텐션 헤드를 사용하여 얼굴의 여러 영역을 동시에 집중한다.
각 헤드별로 공간 어텐션 유닛과 채널 어텐션 유닛이 포함되어 있음
최종적으로 MAN에서 나온 출력 특징 벡터가 AFN에 입력되어 클래스 점수를 출력한다.
이 연구에서는 MAN에서 나온 어텐션 맵이 각각 다른 얼굴 영역에 집중할 수 있는 partition loss를 설계하였다.
그림 1에서 처럼 단일 어텐션 모듈은 하나의 이미지 영역에만 집중하여 다른 중요한 얼굴 영역을 놓친다.
반면, 제안된 DAN은 동시에 중요한 여러 얼굴 영역을 다룰 수 있다.
Main contribution
(1) 클래스간 분리성을 최대화하기 위해, 단순하지만 효과적인 feature clustering 전략을 제안하여 FCN으로 클래스 내 변화와 클래스 간 마진을 최적화한다.
(2) 단일 어텐션 모듈로는 여러 표현에 걸친 미묘하고 복잡한 외형 변화를 모두 포착할 수 없다는 것을 보여주고 이를 해결하기 위해 MAN과 AFN을 제안하여 여러개의 겹치지않는 로컬 어텐션을 포착하고 융합하여 이들 간의 higher-order interaction을 인코딩한다.
Our approach
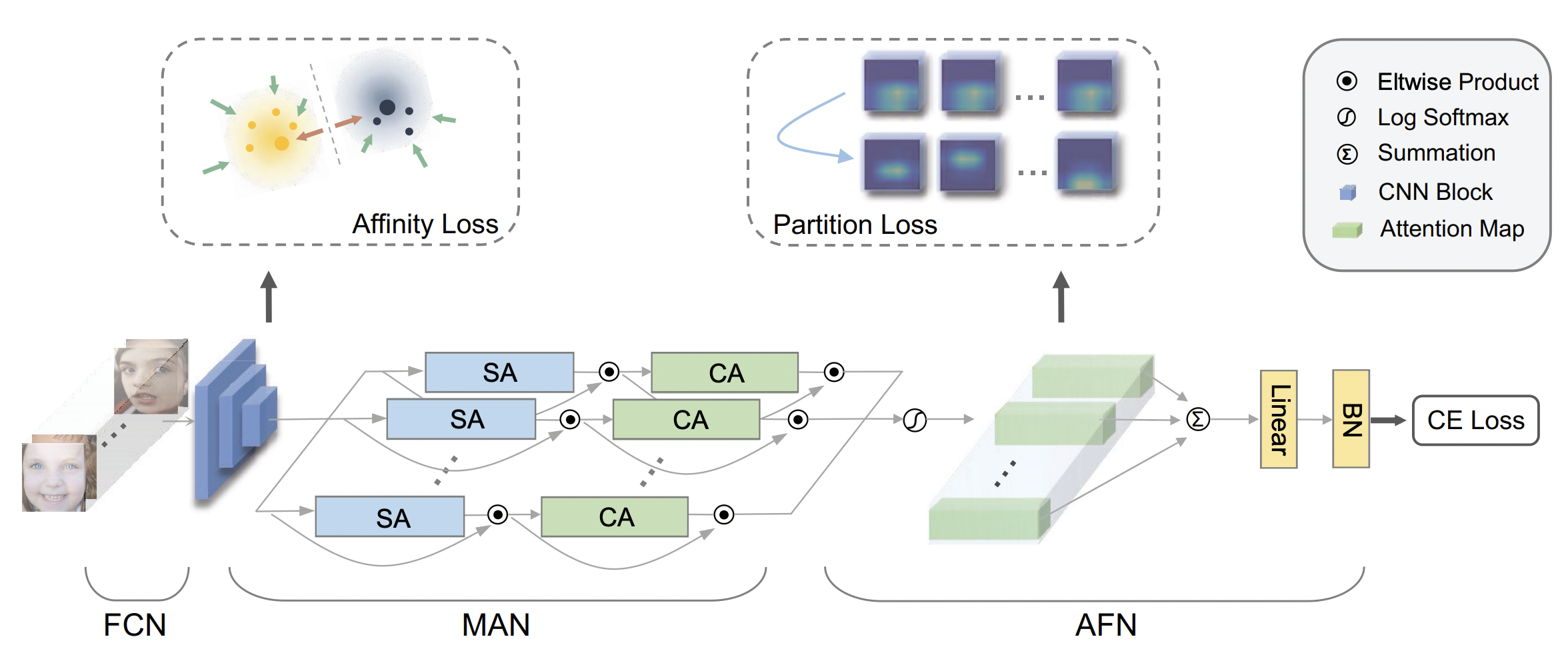
DAN은 3가지의 구성요소: FCN, MAN, AFN으로 이뤄져있다.
먼저, FCN에 얼굴 이미지 배치를 입력시키고 클래스를 구별하기 위한 기본적인 특징 임베딩을 출력한다.
MAN을 통해 얼굴 표현 영역의 여러 부분을 포착하는 다양한 어텐션 맵을 학습한다.
이 어텐션 맵들은 AFN에 의해 각기 다른 영역에 집중해서 훈련된다.
최종적으로 AFN이 전체 어텐션 헤드로부터 추출한 특징들을 융합하고 입력이미지에 대한 카테고리 예측 결과를 제공한다.
특히, 제안된 MAN은 가볍지만 효과적인 어텐션 헤드를 포함한다.
어텐션 헤드는 공간 어텐션 유닛과 채널 어텐션 유닛이 순차적으로 구성되어있다.
공간 어텐션 유닛은 여러 크기의 컨볼루션 커널을 포함한다.
채널 어텐션 유닛은 공간 어텐션 유닛의 끝에 이어져서 인코더-디코더 구조를 따라 어텐셔맵을 강화한다.
두 어텐션 유닛 모두 입력 특징과 합쳐진다.
전체적인 DAN의 과정은 그림 2에 나타나있다.
<Feature Clustering Network (FCN)>
백본 네트워크로 Residual network를 사용함
성능과 파라미터 수를 고려함
각기 다른 얼굴 표현은 본질적으로 비슷한 얼굴외향을 공유한다.
따라서, 이 논문에선 discriminative loss를 제안하여 (affinity loss라 칭함) 클래스간 마진을 최대화하려고 하였다.
각 훈련 스텝마다, 특징들이 그 특징이 속한 class center에 더 가까워질수 있도록한다.
동시에, 각기다른 클래스의 center들을 서로 멀리 떨어져있도록 하여 차별성을 증가시켰다.
입력 이미지 특징 xi∈X과 클래스 라벨 yi∈y이 있다고 하자.
이때, i∈1...M,M:훈련셋이미지수
백본의 출력 특징은 아래와 같이 표기한다.
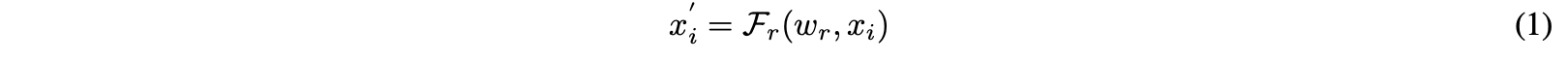
Fr : backbone network
wr : Fr의 네트워크 파라미터
Affinity loss
Affinity loss는 클래스 간 거리를 최대화하고 클래스 내 분산을 줄이기 위해 제안되었다
Affinity loss을 통해 백본 네트워크가 얼굴 표정의 다양한 특성을 각각의 클래스 센터로 정확하게 클러스터링 할 수 있음.
기존의 Center loss와 비교해서, affinity loss는 클래스 센터간 거리를 늘어날수록 클래스간 겹치는 것을 방지할 수 있기 때문에 이 부분은 그대로 가져온다.
수식적으로는 클래스 센터 행렬 c∈RD×|y|은 각 컬럼이 클래스 센터에 해당한다.
이때, affinity loss 함수는 아래와 같이 정의할 수 있다.
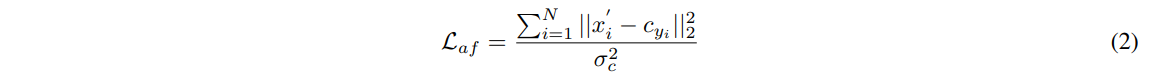
N: 훈련 배치 내 이미지 수
D: 클래스 센터 차원
cy: i번째 이미지의 gt에 해당하는 c의 열벡터
σc: 클래스 센터간의 표준편차
x_i^'는 feature vector가 아니라 더 높은 차원의 feature map이 될 수도 있다.
구현시에는 x_i^'에 global average pooling을 적용하고, 식2를 거치기 전에 sigleton dimension을 제거할 수 (한 차원 축소)있다.
또한,유사한 방법으로 feature map을 flatten할 수도 있음
단순하지만 이 affinity loss는 클래스간 더 넓은 마진을 갖게 해서 서로 밀어내는 결과를 보여주기 때문에 기존의 center loss보다 더 효과적이다.
이는 center loss에서 부족한 점을 채워주는 것으로 볼수 있는데, 기존의 center loss는 오로지 같은 클래스 내에서 근접할 수 있도록 하고 서로 다른 클래스간 공간을 확보해주지 않는다.
특히, σc는 이미 클래스 중심이 계산되어이기 때문에 훈련도중에 쉽게 얻을 수 있고, affinity loss를 위한 추가적인 하이퍼파라미터가 필요하지 않다.
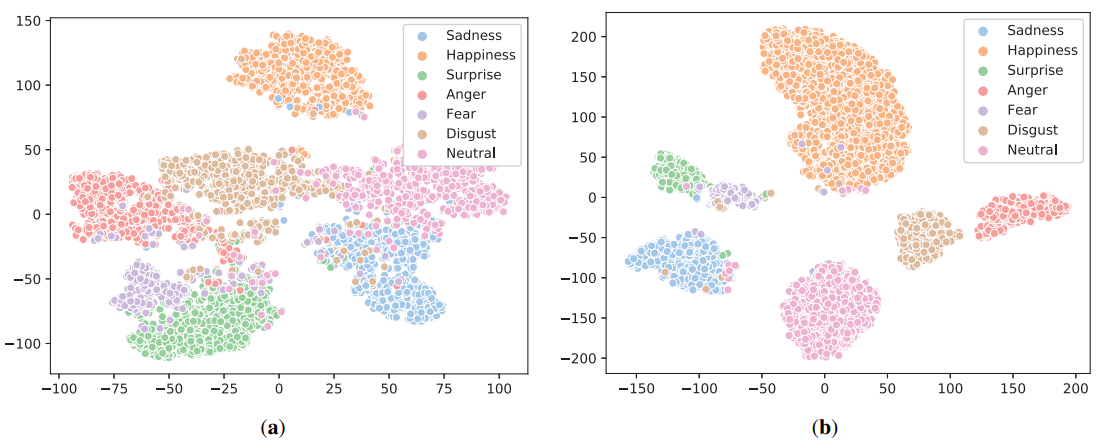
그림 3은 FCN에서 center loss와 affinity loss를 적용하였을 때 특징을 t-SNE로 시각화 한 것이다.
affinity loss를 적용한 경우가, 클래스간 마진이 명확하고 더 좋은 퀄리티를 보여준다.
<Multi-Head Attention Network (MAN)>
단일 어텐션 헤드로는 FER에 충분하지 않아서 다양한 로컬 영역을 결합한 추론이 필요하다.
이런 관점에서 MAN은 서로 독립적인 병렬 헤드를 갖는다.
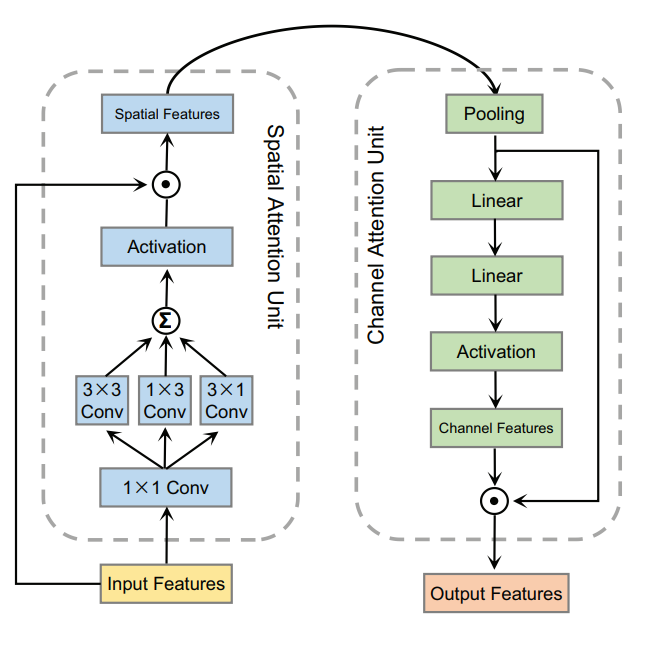
그림 4를 보면 어텐션 헤드가 공간 어텐션 유닛과 채널 어텐션 유닛으로 이뤄져있다ㅏ.
공간 어텐션 유닛은 FCN에서 입력 특징을 받아서 공간적인 특징을 추출한다.
이후, 채널 어텐션 유닛을 통해 공간 특징을 입력으로 받아 채널 특징을 추출한다.
이제 이 특징들을 attention vector와 결합한다.
특히, 병렬 헤드들은 크기가 똑같고 파라미터 값만 다르다.
그림 4의 왼쪽 섹션은 공간 어텐션 유닛을 보여주며, 4개의 컨볼루션 층과 활성화 함수로 이뤄져있다.
다양한 스케일에서 로컬 특징을 포착하기 위해 1x1, 1x3, 3x1, 3x3 컨볼루션 커널을 사용하였다.
채널 어텐션 유닛은 오른쪽섹션에 표현되어있는데 gap층과 두개의 선형층, 활성화함수로 이뤄져있다.
특히 채널 정보를 인코딩하기 위해 두개의 선형 레이어를 사용하였다.
H=H1,⋯,HK을 어텐션 헤드, S=s1,⋯,sK을 공간 어텐션 맵의 출력이라고 하자.
백본네트워크의 출력 특징 x^'이 주어지면 (I는 표기생략함) j번째 공간 어텐션 유닛의 출력은 아래와 같다.
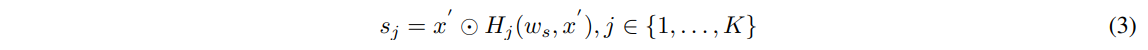
wc: H′j의 네트워크 파라미터
MAN을 사용하는 주요 이점은 두가지가 있다
먼저, 공간 어텐션과 채널 어텐션을 순차적으로 통합하여 특징 간의 high-order 상호작용을 효과적으로 포착할 수 있다.
또한, 여러개의 어텐션 헤드를 생성하여 모델이 동시에 서로 다른 얼굴 영역을 집중할 수 있게 한다.
<Attention Fusion Network (AFN)>
MAN이 우리가 원하는 대로 어텐션맵을 학습하게 하기 위해 AFN을 제안하여 MAN이 학습하는 특징을 강화한다.
먼저, AFN은 log-softmax를 적용하여 어텐션 특징 벡터를 어텐션 특징 벡터를 스케일링 하여, 가장 반응이 높은 영역을 강조한다.
이후, partion loss를 제안하는데 이는 어텐션헤드들이 서로 다른 중요한 영역을 겹치는 어텐션 없이 집중할 수 있도록 한다.
이를 통해 어텐션 헤드를 여러개 쓰는 효과를 입증하고 서로 겹치지 않는 로컬 영역에 집중하도록 한다.
정규화된 어텐션 특징 벡터를 하나로 합 쳐서 선형 레이어를 통해 class confidence를 계산할 수 있다.
Feature scaling
최종 어텐션 특징 벡터 A는 먼저 log-softmax함수를 통해 어텐션헤드에 해당하는 차원을 따라 scale되어 서로 다른 헤드로부터 특징의 common metric을 얻는다.
MAN은 A=a1,⋯,aK을 출력으로 하는데, 우리는 이 벡터들이 모두 (j번째 벡터 aj) L차원(실험에서 L=512)이라고 가정하였다.
그렇게 되면, aj에 대한 feature scaling 결과 vj는 아래와 같이 계산한다.
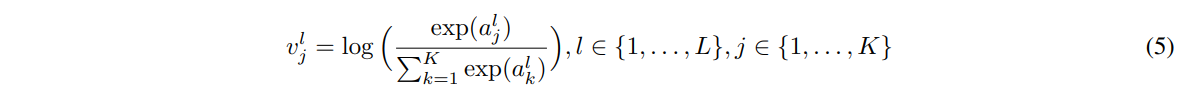
alj: aj의 l번째 원소
vlj: vj의 l번째 원소
scaling을 거치면 서로 다른 헤드의 특징들이 final classification을 위해 더해진다 (그림 2 참고)
Partition loss
본 논문은 partition loss를 제안하여 어텐션헤드들이 서로 다른 얼굴 특징 영역에 집중하도록 하여 싱글 어텐션으로 나타나지 않도록 한다.
그림 1의 오른쪽 부분에 나와있듯이 partition loss는 MAN의 헤드들을 성공적으로 조정하여 추가적인 간섭 없이도 서로 다른 얼굴 영역을 따르도록 한다.
구체적으로는, 어텐션 벡터간 variance를 최대화하여 구현한다.
K를 어텐션 헤드의 개수라고 하고 이는 loss value의 감소 속도에 따라 적응적으로 조절하는 파라미터이다.
어텐션 헤드의 수가 많은 MAN은 더 많은 미세한 영역들을 생성해낼 것이다.
전체적으로는 아래와 같이 partition loss를 정의한다.
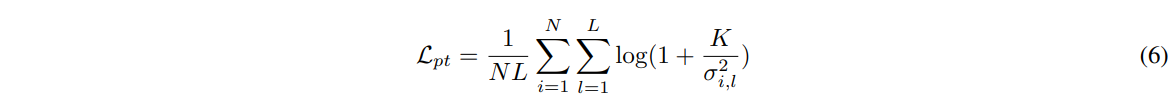
N: 현재 배치내의 이미지 수
L: 각 헤드의 어텐션 특징 벡터의 차원
σ2i,l: i번째 이미지와 l-th차원이 주어지고 j∈1,⋯,K일때 vlj의 variance
<Model Learning>
위에서 보인 대로, DAN모델은 3가지 구성요소로 되어있다
FCN, MAN, AFN
이 모델을 훈련하기 위하여 모든 구성요소의 손실함수를 하나의 통합된 프레임워크 내로 고려해야 한다
FCN에는 affinity loss, AFN에는 partition loss, 이미지 분류에는 크로스 엔트로피
딥러닝 standard practice를 따라, 최종 손실 함수를 위의 모든 손실 함수들을 결합한 형태로 구성하였다.
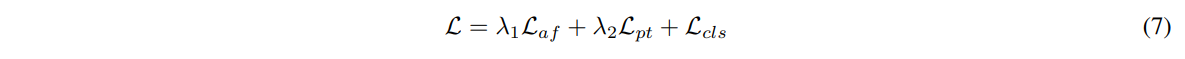
λ1,λ2: Laf,Lpt를 위한 가중치 하이퍼 파라미터
Lcls: 이미지 분류를 위한 크로스 엔트로피 손실
실험에서는 λ1,λ2를 모두 1.0으로 세팅하였고 실험을 통한 성능 향상은 이 값들에 특별히 민감하지 않았다.