

논문정보
Learning enhanced features and inferring twice for fine-grained image classification
X-MOL
www.x-mol.net
<code>
GitHub - boxyao/Forcing-Network
Contribute to boxyao/Forcing-Network development by creating an account on GitHub.
github.com
논문정리
Abstract
FGVC는 비슷한 같은 카테고리에 속하는 데이터들의 하위 카테고리를 구별하는 것을 목표로 한다.
현재 연구는 FGVC에서 차별성있는 특징이 중요하다는 것을 입증했지만, 그 외 특징들 또한 올바른 분류에 기여할 수 있다는 것을 간과하였으며, 추출된 특징들은 미묘한 영역보다는 명백한 영역의 정보를 더 많이 포함하고 있다.
본 논문에선 우선 forcking module을 제안하여 네트워크가 더 다양한 특징을 추출하여 CAM을 기반으로 한 suppression mask을 생성한 후 이를 통해 가장 구별 가능한 영역을 억제하여 네트워크가 차별성 있는 2차 특징을 추출하도록 한다.
Forcing module은 original branch, forcing branch로 구성되어 있다.
- original branch 차별성있는 1차(primary) 영역에 집중
- forcing branch 차별성있는 2차(secondary) 영역에 집중
여러 계층의 다운샘플링을 거치게 되면 작은 영역의 구별 가능한 특징 정보가 심각하게 손실되는 문제를 해결하기 위해, 첫번째 예측의 CAM을 기반으로 객체를 잘라내고 스케일링 하여 두번째 입력으로 한다.
예측 에러를 줄이기 위해 첫 번째와 두 번째 예측 확률을 융합하여 최종 예측으로 사용한다.
실험 결과는 제안된 방법이 베이스라인을 큰 차이로 압도할 뿐 아니라 FGVC-Aircraft 데이터셋에 대해 SOTA를 달성하였음을 보여준다.
Introduction
지난 몇년간, CNN이 훌륭한 특징 추출 능력으로 이미지 분야에서 매우 좋은 성과를 보였다.
하지만, 카테고리 별로 차이가 큰 기존 이미지 분류와는 달리 FGVC는 하위 단계 카테고리 즉, 같은 상위 카테고리에 속하는 것들을 구분해내야 한다.
FGVC는 클래스 내 분산이 분산이 클래스 내 분산이 클래스 간 분산보다 크기 때문에 훨씬 어려운 작업이다.
CNN 모델은 미묘하고 차별성있는 특징을 추출하지 못하면, 비슷하게 생긴 카테고리들을 제대로 구별해낼 수 없다.
최근 연구에 따르면, 여러개의 차별성있는 요소들에 집중하는 것이 FGVC에서 중요한 역할을 한다.
초기단계에서는 바운딩박스나 요소에 대한 주석을 통해 여러 객체 요소에서 차별성있는 특징들을 추출하였다.
최근에는 오로지 클래스 라벨만을 이용하여 자동으로 개체 요소를 찾아낼 수 있다.
참고문헌 [7], [23]은 외부 간섭 없이 CNN이 일반적으로 가장 차별적인 특징을 추출하는데에는 탁월하긴하지만 중요하고 보완적인 정보를 무시한다.
CNN의 translation invariance에 대한 연구는 입력 이미지를 조금 변형(translation)시키거나 크기를 조정했을 때, 예측 결과를 크기 바꿀 수 있음을 보여준다. 이는 따라서, 객체가 이동하거나 확장/축소 되면 네트워크가 다른 부분에 초점을 맞추고 특징을 추출함을 의미한다.
CNN에서 translation invariance란 input의 위치가 달라져도 output이 동일한 값을 갖는것을 말하는데,
CNN 네트워크 자체는 translation equivariance(varaince)하다.
but, MAX pooling, weight sharing, softmax ... 등의 역할로 invarinace하게 됨
참고 : https://ganghee-lee.tistory.com/43
본 논문에선, forcing network라는 새로운 프레임워크를 제안하여 F-net이라 칭하고 FGVC의 한계점을 해결한다.
F-net에서는 original branch와 forcing branch로 구성된 forcing module을 통해 더 다양하고 강화된 특징을 얻는다.
Original branch는 CAM(Class Activation Map)을 생성하여 가장 차별성 있는 영역을 찾는다.
Forcing branch는 suppessive mask를 통해 가장 차별성 있는 영역을 억제하고 네트워크는 그 다음으로 차별성있는 영역에 집중한다.
예측 에러를 줄이기 위해, CAM을 기반으로 미묘한 영역들이 확대되고, 객체가 두번째 입력으로서 다시 예측되기 위해 크롭되고 확대된다.
첫 번째와 두 번째 확률 분포를 융합하여 최종 결과로 사용한다.
훈련 단계에서는, 크롭된 이미지에서 가장 차별성있는 영역을 버려서 네트워크가 더 많은 영역에 집중하도록 한다.
Main Contribution
- forcing network 구조를 제안하여 네트워크가 다양한 영역에 집중할 수 있도록 forcing branch라는 보조적인 브랜치를 소개하였음. 가장 차별성있는 특징을 포함한 다양한 특징과 confusion 특징을 추출하여 FGVC에 사용.
- CAM을 기반으로 객체를 잘라내고 미묘한 영역을 확대하여 두번째 예측에 사용한다. 이 두 확률 분포를 합쳐 최종 예측에 사용한다.
Related Work
skip
....
Our method obtains diverse features that contain the primary discriminative features and confusion features by enhancing the secondary discriminative regions. Compared with random suppression, suppressing primary the discriminative regions in class activation maps that force the network to pay more attention to the confusing regions which are usually overlooked due to the network pays the most attention to the primary discriminative regions. Compare with multiple frameworks, the first and the second prediction in our method share the same framework, and we only increase an extra convolutional layer, based on backbone such as ResNet-50 [13]. Since the object is panned and magnified in the second input, the network will focus on the parts different from the first prediction. In the training phase, we use the average of the first and the second loss as the final loss, it reduces the loss of the oscillation from the first wrong prediction.
Methodology

두 모듈의 전반적 구조는 그림 각각 1과 그림 2에 잘 나타나있다.
F-Net은 feature extracing module, forcing module의 두 구조로 구성되어 있다.
그 중, feature extracting module은 컨볼루션 백본 네트워크인 Resnet-50이다.
CAM을 간편하게 얻기 위해 분류기 FC 레이어 대신 1*1 컨볼루션 층으로 대체하였다.
1*1 컨볼루션 층의 출력 채널 수는 클래스 개수와 똑같이 하여 CAM을 얻는다.
입력 이미지가 주어지면, feature extracing module(Resnet-50)을 통해 특징맵을 얻는다.
추출된 특징 맵을 F∈RN×W×H로 표기한다.
H : height
W : width
N : 채널 수
<Forcing module>
제안된 모듈은 DB에서 기인하였다.
[25] Fine-grained recognition, accounting for subtle differences between similar classes.
https://arxiv.org/abs/1912.06842
Forcing module은 네트워크가 분류를 위해 더 다양한 특징을 추출할 수 있도록 유도하며 original branch와 forcing branch로 구성되어있다.
Original branch와 forcing branch는 같은 특징 추출 모델을 사용하지만 두 branch의 입력은 각각 다르다.
이후 GAP(global average pooling)을 수행하여 predicted CAM M′p∈RW×H을 얻는다.
p : index of maximum in predicted vector V∈RC
C : number of classes

g(⋅) : global average pooling
M′p로 F에서 top-k개의 차별성있는 위치를 억제하기 위한 마스크를 생성한다.
top-k개의 위치가 억제되면 forcing branch는 또 다른 confused position에 집중할 수 있다.
이제 forcing branch의 입력을 생성하는 과정을 자세히 살펴보자.
먼저, M′p가 W×H의 크기로 변형된다.
이때, k번째 값 T를 얻어 임계값으로 사용한다.
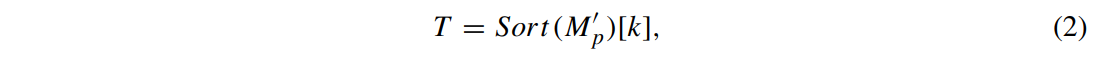
Sort(⋅) : 내림차순 정렬
[⋅] : 인덱싱하여 벡터로부터 값을 가져옴
k : suppressive position의 개수를 지정하는 하이퍼파라미터
이제 M′p로부터 억제마스크 B를 생성한다.
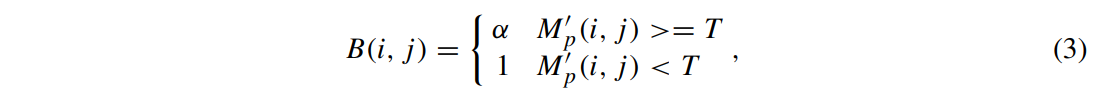
i,j : feature position의 행, 열
α : suppressing factor 하이퍼 파라미터
forcing branch의 출력 G∈RC×W×H은 아래와 같이 얻는다.
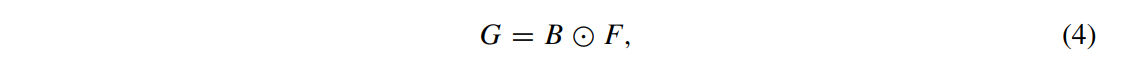
⊙ : element-wise multiplication
Classification convolution이 수행된 후, forcing branch의 출력 M″을 얻는다.
M을 forcing module의 출력이라고 하면 M은 식 5와 같이 계산한다.
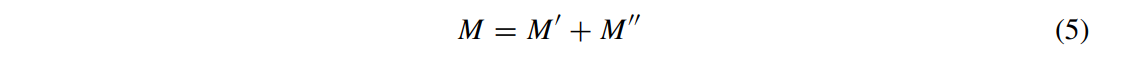
Confidence score은 M을 GAP에 통과시켜 얻는다.
<CAM-based cropping module>
CAM 기반 cropping module은 객체를 잘라내고 다시 추론하기 위해 제안되었다.
첫번째 예측은 가장 확실한 영역에 집중을 하면, 두 번째 예측은 좀더 미세한 영역에 집중을 하는데, 이는 CAM기반 cropping module 이후 확대된다.
raw prediction과 second prediciton을 합쳐서 final prediction으로 간주한다.
객체를 크롭하는 과정을 살펴보자.
forcing module에서는 CAM M\in R^{C\times H\times W}을 생성하였다.
대게는 top-1 맵이 객체의 한 부분에서 가장 큰 반응을 하고, 다른 맵에서 반응이 높은 영역은 객체의 다른 부분이기 때문에top-1맵을 사용하여 차별성있는 영역을 찾는 대신 top-8개의 맵을 사용하여 전체 객체를 찾아낸다.
M_p\in R^{W\times H}은 top-8개의 맵을 element-wise summation한 것이다.
M_p는 객체와 배경으로 구성되어 있다.
t는 객체와 배경을 구분하기 위해 세팅된 임계값으로 아래와 같이 얻는다.
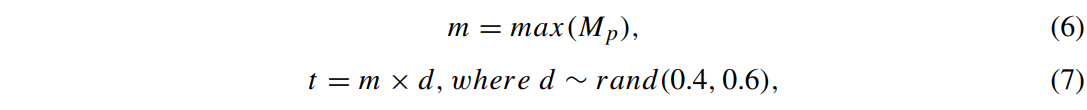
m : M_p의 최댓값
샘플이 다양하기 때문에 훈련단계에서 0.4~0.6 사이의 균일분포로부터 난수 d를 추출한다.
테스트 단계에서는 d의 최솟값을 0.4로 하여 전체 객체가 크롭되도록 한다.
이제 크롭 마스크 B_2는 아래와 같이 얻는다.
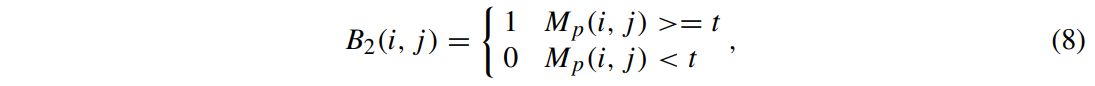
t보다 크거나 같은 반응을 갖는 값들이 객체에 속하고, t보다 작은 값이 있는 곳은 배경으로 간주된다.
B_2에서 1이 속한 위치를 모두 커버할 수 있는 바운딩박스를 생성하고, 원 이미지에서 이 부분을 크롭하여 두번째 입력으로 사용한다.
훈련단계에서는 차별성있는 영역은 드롭되어 두번째 입력에 사용된다.
테스트 단계에서는 드롭되지 않음!!
Drop mask는 아래와 같이 계산하여 얻는다.
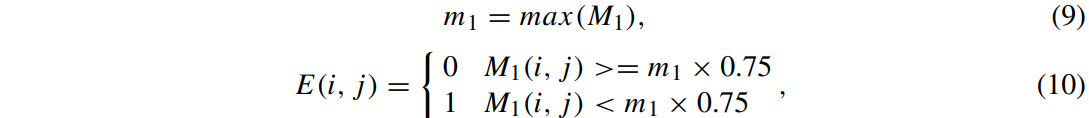
M_1은 M에서의 top-1 맵이며, m_1은 M_1의 최댓값이다.
훈련 과정에서 가장 높은 반응이 있는 영역의 크기는 항상 바뀌기 때문에, 임계값은 난수보다는 0.75의 고정 값을 사용한다.
E에서 0이 위치한 곳은 드롭되어 두번째 입력으로 사용된다.
<Multi-prediction model>
Multi-prediction 모델은 같은 이미지에 대해 두 번의 예측을 수행한다.
네트워크는 같지만, 입력은 서로 다르다.
Multi-prediction 모델의 훈련과 테스트에 사용되는 두 번째 입력은 서로 다르다.
그림 2는 multi-prediction 모델의 과정이며, 훈련 단계는 파란 색 화살표로 나타낸다.
훈련 단계에선, 원본 이미지 I가 네트워크에 처음으로 입력되어, 예측 결과 Prop_1를 얻는다.
첨으로 예측된 CAM에 따라 I target을 잘라내고 선형 보간(linear interpolation)을 통해 확장한다.
이때, clipping factor d는 0.4~0.6 사이의 난수로 결정하고 주요 특징 영역을 버린 후 두 번째 예측 이미지 I_2를 얻는다.
같은 네트워크를 다시 통과하여 두 번째 예측 결과 Prob_2를 얻는다.
Prob_1, Prob_2은 모두 소프트맥스를 거친 예측 확률 값이고 최종 예측 결과 P는 아래와 같이 구한다.
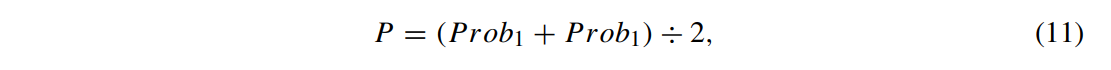
분류할 때 손실함수로는 cross-entropy 함수를 사용한다.
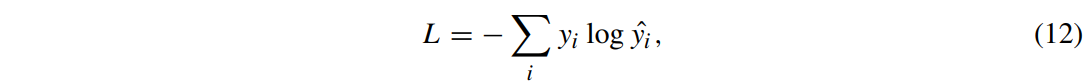
y_i : 예측 결과
\hat{y_i} : 참값
i : category subscript $(0~c-1)
multi-prediction 모델 훈련에선, 최종 예측 결과 P로 손실값을 계산하지 않고 첫번째 예측 결과 Prob_1와 두 번째 예측 결과 Prob_2를 이용하여 손실값을 계산한다.
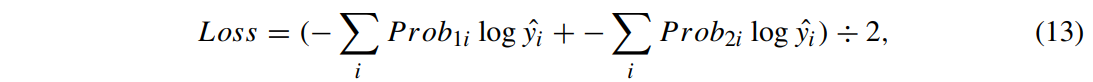
최종 손실은 첫 번째 예측의 크로스 엔트로피, 두 번째 예측의 크로스 엔트로피 결과를 평균낸 것이다.
테스트 단계는 초록색 화살표로 나타내었다.
테스트 단계에서 먼저 원본 이미지 I를 네트워크에 입력으로 넣어 첫 번째 예측 결과 Prob_1을 얻는다.
첫번째 예측의 CAM에 따라 I target만이 잘라지고 선형 보간(linear interpolation)을 통해 확장된다.
이때, clipping factor d는 0.4
주요 특징을 드랍하는 모듈은 수행되지 않고, 두 번째 예측을 위한 입력 이미지 I_2를 얻는다.
최종 예측 결과 P는 훈련 단계와 같은 방식으로 구한다.
Experiments
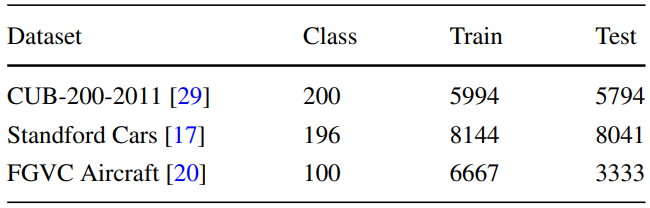
<Datasets>
- CUB-200-2011
- Stanford Cars
- FGVC Aircraft
<Implementation details>
- backbone은 Pytorch로 구현된 ResNet-50
- fc layer 대신 1x1 컨볼루션으로 대체 (출력 채널은 클래스 개수)
- feature extracting convolutiona layer는 ImageNet으로 사전훈련된 가중치 사용
- 컨볼루션 레이어는 Xavier initialization을 이용하여 초기화
- 이미지는 512*512로 조정 후, 448*448로 random crop + random horizontal flipping
- cropped threshold d는 0.4~0.6사이에서 랜덤하게 선택
- dropped threshld는 0.7로 고정
- SGD에서 모멘텀 0.9, epoch 100, weight decay 0.0001로 훈련
- 미니 배치 크기 6을 GTX-2080ti(11G) GPU 환경에서 훈련
- 소스코드는 https://github.com/boxyao/Forcing-Network에 공개