

논문정보
Voting in Transfer Learning System for Ground-Based Cloud Classification
Voting in Transfer Learning System for Ground-Based Cloud Classification
Cloud classification is a great challenge in meteorological research. The different types of clouds, currently known and present in our skies, can produce radioactive effects that impact the variation of atmospheric conditions, with consequent strong domin
www.mdpi.com
논문정리
Abstract
구름 분류는 기상연구에서 힘든 과제이다.
일반적으로 우리가 알고 있고 하늘에서 볼 수 있는 여러 종류의 구름은 방사 효과를 생성하여 기상 조건 변화에 영향을 미치고, 그 결과 지구의 기후와 날씨를 결정하는 주요 요소가 된다.
따라서 구름의 주요 시각적 특징을 알아내는 것이 중요하다.
본 논문에선 사전학습된 심층 신경망 기반 구조를 채택하여 image description에 사용하고 그 후, 분류한다.
피라미드형 접근방식을 가진다.
아래부터 위로 진행하는데 이전의 지식에서 원래의 task와 관련된 부분을 추출하고 이를 새로운 task로 전환한다.
업데이트된 지식은 분류 예측을 제공하기 위해 투표 상황(voting context)으로 통합된다.
프레임워크는 불균형한 셋에 대해서 신경 모델을 학습하여 학습조건을 더 복잡하게 만들고 통계측정을 통해 예측을 제공한다.
각기 다른 구름 이미지 데이터셋에 대한 실험이 수행되고, 달성된 결과를 통해 SOTA와 관련해서 제안모델의 효과를 입증한다.
Introduction
구름은 하늘에서 끊음없이 존재한다.
생태계가 부여한 역할과 더불어 구름은 기상 조건을 결정하는 중요한 요소가 된다.
일사 시간과 온도 등
요즘에는 기후변화 탓에 대기환경이 역동적으로 바뀌기 때문에 구름의 행동에 주의를 기울이게 되었다.
기후 모델은 기후 변화를 예측하는데 정밀도가 부족하고, 여러 현상에 의해 결정된 조건의 변화에 기인한다.
따라서 구름 행동 예측이 기후 변화를 추정하는데 중요하다.
게다가, 구름 변화는 곧 지구 복사와 에너지 균형에 영향을 미친다.
다량의 데이터셋을 얻기 위한 많은 노력이 있었지만 적절한 처리 자원이 있는 장치 부족 탓에 성공하진 못했다.
최근 기술로 인해 과학적으로 구름의 속성과 운형을 탐지할 수 있는 수많은 연구와 분석이 이뤄졌다.
요즘 들어서야 지상 구름 이미지의 양으로 인해 이를 인식하는 연구가 광범위하게 이뤄졌다.
가장 기본적인 알고리즘은 밝기, 텍스쳐, 모양, 색 등의 수제 특징을 이용하는데 데이터의 복잡한 분포로 인해 이미지 내용은 표현하지만 모델 일반화를 얻어내진 못했다.
게다가 이미지에 포함된 시각적 정보는 외향의 큰 변화가 있기 때문에 구름을 정확히 묘사하기엔 불충분했다.
비시각적 특징, 즉 온도, 습도, 압력, 풍속과 같은 멀티모달 정보가 도움이 된다.
최근 연구에 따르면 딥러닝이 구름 인식 분야에서 이미지를 다루고 분석하고 표현하고 분류하는 데 효과가 있음을 보였다.
특히 이미지 분류 작업에서 심층 신경망의 성공은 소프트웨어 개발, 대용량 데이터셋 측면에 기인하였다.
구름 이미지 분석에서 심층 네트워크가 segmentation과 detection에서도 채택되었다.
하지만 이미지의 내용과 부족한 클래스간 데이터 불균형은 성능에 결정적인 영향을 미쳤고 모델 일반화의 불확실성을 초래하였다.
위의 문제를 해결하기 위해 본 연구진은 심층 전이에 기반한 프레임워크와 투표 학습(voting learning)을 제시한다.
이는 3단계로 구성된다.
- 신경망 훈련에 필수적인 크기 조정 등의 이미지 처리 연산 수행
- 다중 심층 신경망을 수정하고 재훈련하여 사전 지식 활용
- 심층 신경망이 제공하는 각기 다른 예측을 살펴보고 이들을 결합해 분류 단계에서 가장 최적의 결정을 제공
제안된 프레임워크의 주요 포인트는 다음과 같다
● 심층학습, 투표학습에 기반한 프레임워크는 구름 인식 작업에서 클래스 간 불균형을 해소
● 프레임워크는 심층 전이 학습에 기인한 다중 분류 모델로 설계
● 적절하게 결합된 다중 모델이 단일 모델에 비해 분류 결정을 향상시킬 수 있음을 보여줌
● 전문가가 분류한 데이터셋으로 기존 방법과 비교하여 실험을 진행
Related work
Skip
Material and Methods
이 섹션에선 심층 신경망과 투표 학습의 두 방법 측면에서 제안된 프레임워크를 설명한다.
목표는 여러 심층 신경망을 결합하여 구름 이미지를 분류하는 것
경쟁력 있는 모델 집합이 정렬되어 분류 과정에서 최종 선택에 유용한 결정을 제공함
프레임워크는 3 블럭으로 구성된다.
- 첫번째 블럭에서 이미지 크기 조정 측면에서 전처리 실행
- 두번째 블럭에서 해당 작업을 위해 변형된 각기 다른 심층 신경망 학습
- 세번째 블럭에서 투표를 통해 여러 예측값을 결합함
마지막으로, 지도학습으로 지정된 횟수만큼 훈련을 반복한다.
그림 1은 제안된 프레임워크에 대한 개요이다.

<Image Resize>
신경망의 단점 중 하나는 입력 레이어의 차원이 고정되었다는 것
표 1의 5번째 열에서 확인 가능
입력 층 차원에 대한 size normalization이 필수적이긴 하지만 네트워크 훈련과 분류 단계에서 다른 크기의 이미지나 대형 이미지를 처리할 수는 없다.
이 단계는 이미지 자체 정보의 내용을 변경하지는 않는다.
그래서 뭐 어쩌란거..? 그니까 백본 네트워크에 맞추기 위해 사이즈 재조정이 필수적이라 사용은 하였지만 다른 크기의 데이터를 활용할 수 없는 단점이 있다. 이 얘기를 하고싶은건가보다,,
<Network Design and Transfer Learning>
전이학습도 훈련 방법 중 하나이다.
기본적인 개념은 소스 도메인으로부터 추출된 지식을 타겟 도메인으로 전이시키는 것
본 실험에서는 구름 분류에 해당한다.
일반적으로 사전훈련된 네트워크는 새로운 작업을 학습하기 위해 선택됨
사전훈련된 심층 신경망의 표현 능력을 사용할 수 있는 가장 편리한 방법이다.
랜덤하게 초기화된 가중치를 가진 새로운 네트워크를 맨 처음부터 학습하는 것보다 전이 학습으로 네트워크를 조정하는 것이 훨씬 더 빠르고 쉽다.
이후, 클래스에 맞게 최종 레이어의 구조를 재설계하여 네트워크를 훈련시키는 것이 목표!
Alexnet은 5개의 컨볼루션 층과 3개의 FC 층으로 구성되어 있다. 훈련 단계에서는 non-saturating한 ReLU 활성함수 (Tanh, Sigmoid 보다 좋다고 함)를 사용하였다.
Saturaing 현상
가중치 업데이트가 멈추는 현상
backpropagation 시 dLdw=0이 된다.
뒤쪽 레이어에서 saturation되면 이 앞의 모든 레이어에서 saturation 되어 가중치 업데이트가 멈춘다.
Googlenet은 22개의 심층 레이어로 구성되어 있다. LeNet에서 기인하였지만 인셉션 모듈이라고 불리는 새로운 개념을 도입하였다. 이 모듈은 작은 컨볼루션 여러개를 기반으로 파라미터터 수를 굉장히 감소시켰다.
AlexNet의 6천만 개의 파라미터 수를 4백만 개로 줄임
이 외에도 배치 정규화, 이미지 왜곡(distortion) root mean square propagatiobn 알고리즘을 포함한다.
Densenet201은 201개의 심층 레이어로 이뤄진 컨볼루션 신경망이다. 기존의 컨볼루션 네트워크가 현재 레이어와 다음 레이어 간 1대1 연결을 갖는 L개의 층으로 구성된 것과 달리, 해당 신경망은 L(L+1)2개의 직접 연결 수를 가진다.
각 레이어는 이전의 모든 레이어에서 나온 특징맵과 해당 레이어 자체의 특징맵을 다음 레이어의 입력으로 사용함
Resnet18, Resnet50은 대뇌 피질 내의 추상세포에서 기인하였다. skip connection(shortcut)을 사용하여 몇개의 레이어를 건너뛴다. 각각 18개와 50개의 레이어로 이뤄져있으며 skip connection 덕에 잔여(residual) 네트워크가 시작되었다.
Nasnetlarge은 NASNet search space라고 불리는 search space를 설계하여 transferability를 가능하게 한다. 이 모델은 최상의 컨볼루션 층(or cell)을 찾고 해당 레이어를 파라미터와 함께 스택에 복제한다.
추가로 Scheduled-DropPath라 불리는 정규화를 적용하여 모델의 일반화 능력을 향상시킨다.
심층 신경망을 구름 분류 문제에 적용하였다.
1000개의 클래스로 나눠진 백만장의 이미지로 이뤄진 ImageNet데이터셋으로 훈련됨
일반적으로 네트워크는 이미지를 표현하고, 각 클래스에 속할 예측값을 제공한다.
먼저 입력이미지는 3개의 채널로 구성되어 있다.
이후 컨볼루션 레이어를 배치하여 이미지의 특징을 추출하도록 한다.
마지막으로 학습하는 최종 분류 레이어가 입력 이미지를 분류해낸다.
사전훈련된 네트워크를 새로운 이미지 분류에 적용시키기 위해, 최종 2개의 레이어를 새로운 레이어로 교체한다.
주로 마지막 레이어는 FC 레이어인데, 이를 제거하고 새로운 데이터의 클래스(운형)들과 완전연결 하도록 새로운 레이어를 추가한다.
전이 레이어와 연결된 새롭게 추가된 레이어의 학습은 learning rate를 증가시켜서 가속시킬 수 있다.
이전 층에서의 가중치 학습률을 0으로 세팅하여 가중치 값을 유지하기도 한다.
그래디언트를 계산할 필요가 없기 때문에 훈련 중 가중치를 업데이트하지 않아도 된다.
이는 저용량 데이터셋에 대해 과적합을 피하는데 큰 영향을 준다.
<Voting Based Learning>
투표 기반 학습 접근법이 분류 단계에서 사용된다.
여러 방법 중에서 stacking을 선택하였다.
단일 분류기를 이후의 분류기와 결합한다.
weak or strong learner를 사용하는 기존의 접근과는 달리, 여러개의 파워풀한 모델들을 결합하여 결과를 특정 확률로 예측한다.
마지막으로 모든 예측값을 join하여 분류 결과로 사용한다.
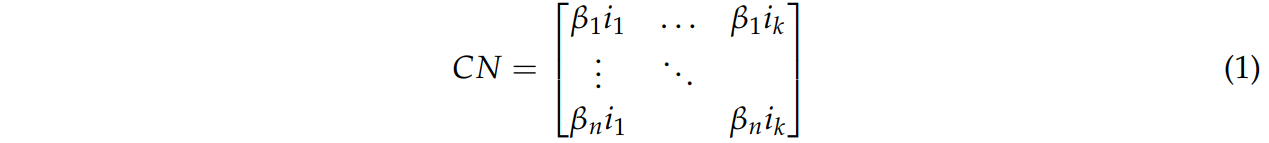
일반적인 모델을 식 1의 행렬로 표현할 수 있다.
ik : x 클래스 중 하나에 속하는 분류될 이미지를 표현, Imgs=i1,i2,⋯,ik에서추출(k$ : cardinality)
βn : 심층 네트워크를 표현, $C = {\beta_1, \beta_2, \cdots, \beta_n에서추출(n$ : cardinality)
또한, 이는 ik∈Imgs와 x 클래스에 관한 결정 d∈I∈1,⋯,x를 제공한다.
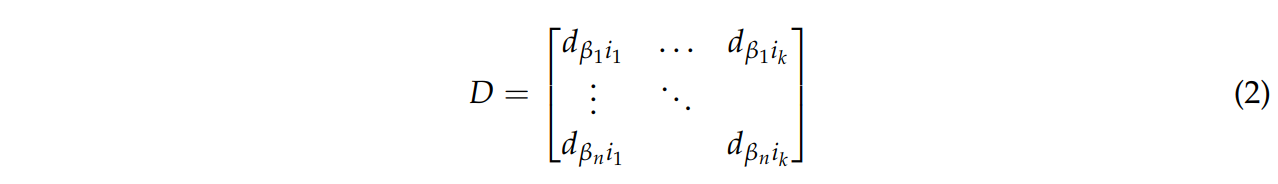
결정 집합은 식 2의 행렬 D로 재배열 될 수 있다.
심층 신경망 결합과 행렬CN의 이미지 결과를 위치 측면에서 설명한다.
βnik→dβnik
게다가, score값 s∈S0,⋯,1은각각의결정d와연관있으며이미지i가클래스x에속할사후확률P(i|x)$을 제공한다.
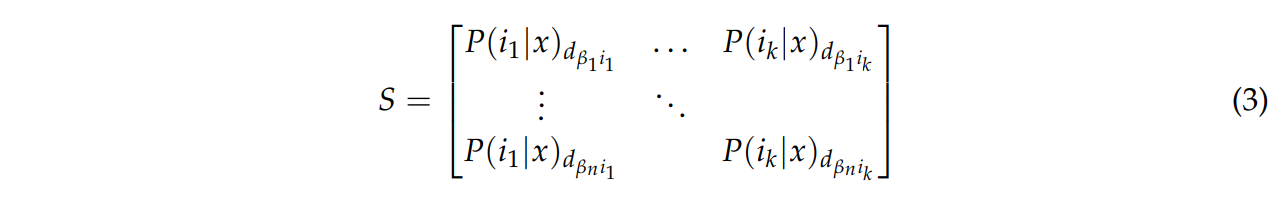
행렬 CN의 가능한 조합들의 결과와 관련된 score값들을 식 3의 행렬 S처럼 표기한다.
이때, 행렬 S의 각 사후확률 요소는CN 행렬의 요소를 참조한다.
βnik→dβnik→P(ik|x)dβnik
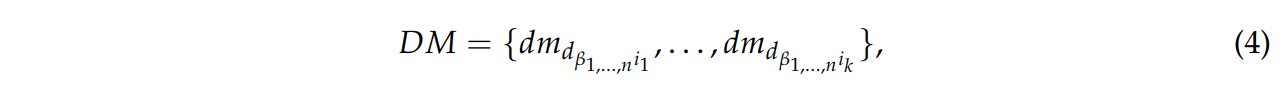
행렬 D의 각 열은 stastical 모드로 분석하여 식 4와 같이 벡터 DM에 기록한다.
dm은 이미지 i가 평균 확률 점수 ds에 속할 수 있는 클래스의 modal value가 된다.
여러 신경망들의 투표에 기반하여 이미지가 속한 클래스
이런 관점에서 statiscal mode의 개념은 식 5와 같다.
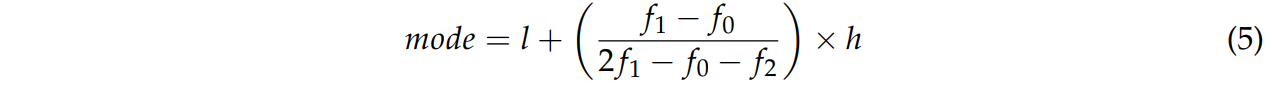
l : lower limit of the modal class
h : size of the clss interval
f1 : frequency of the modal class
f0 : frequency of the class which precedes the modal class
f2 : frequency of the class which successes the modal class
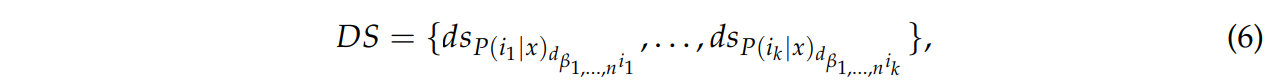
식 6에선 행렬 D의 열을 이용하여 가장 frequency가 높은 결정 값을 계산한다.
DN 내의 여러 심층 신경망으로부터 가장 많이 투표받은 클래스를 얻기 위해 수행된다.
모드를 적용하는 것은 두가지로 나뉜다.
- frequency가 가장 높은값을 추출하기 위함
- 인덱스 들의 발생정도를 추출하기 위함
가장 frequency가 높은 modal value에 대해 행렬 S로 부터 해당 점수를 얻어낸다.
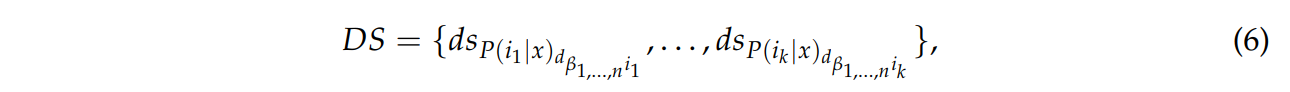
식 6은 벡터 DS를 계산한다.
ds : 행렬 D의 열을 참조하여 mode를 통해 추출한 높은 frequency를 가진 평균 결정 점수
Experimental Results
skip
Conclusion
지상 기반 구름 인식 작업의 복잡성에는 운형이나 그 안에 포함된 시각적 패턴 등 여러 요소가 있다.
컨볼루션 신경망은 이미지를 이해하여 분류 하는 데 큰 도움이 되었다.
따라서 컨볼루션 신경망을 결합한 프레임워크를 제안하였고 전이 학습 접근 방식으로 투표를 활용하여 구름 인식 작업에 활용하였다.
여러 심층 신경망에 기반한 다중 모델은 단일 모델에 비해 강력하다.
다량의 실험을 통해 제안된 접근법이 경쟁력 있으며 보다 발전된 방법들 보다 더 낫기도 했다.
비록 사전훈련된 모델을 사용하였지만 학습단계에서의 계산복잡도가 주 단점이다. 오랜 시간이 걸리며 데이터 양에 민감함.
이후 연구에서는 이러한 유형의 문제에 대한 아직 확인되지 않은 측면에서 컨볼루션 신경망을 연구하고, 구름 과제를 더 발전시키기 위해 다른 데이터셋에 제안된 프레임 워크를 적용해본다.
정리를 해보면 사전 훈련을 거친 여러개의 모델이 있고, 이것들을 구름 데이터에 대해 전이 학습시켰다.
그 이후, 각 모델에서 most frequency value들을 뽑고 사후 확률을 평균화한다.
이후 vote layer를 통해 구름 클래스를 최종적으로 분류하는 것.
voting based learning 이전 까지는 그럭저럭 잘 이해했는데 학습을 위한 식에서 사용한 행렬들과 각 요소가 의미하는 바를 정확히 파악하지 못했다. 한번 더 찬찬히 훑어봐야 할 듯,,
그리고 의문인 것은,, 사전훈련된 백본 네트워크를 각각 전이학습 시키고
각 네트워크의 출력값을 투표한 거 뿐인데 이게 성능이 다른것보다 월등히 좋아지는게 의문이다.
실험을 제대로 한게 맞겠지..?
보통 MGCD 데이터셋에 대해 다른 연구들은 80프로대 후반 ~ 90프로대 초반이었는데
갑자기 99.98%로 훌쩍 뛰어서 의외였다.
내가 아직 투표 시스템을 잘 이해하지 못해서..? 사실은 이것이 엄청난 핵심일런지,,