

논문정보
Fine-grained Visual Classification with High-temperature Refinement and Background Suppression
Fine-grained Visual Classification with High-temperature Refinement and Background Suppression
Fine-grained visual classification is a challenging task due to the high similarity between categories and distinct differences among data within one single category. To address the challenges, previous strategies have focused on localizing subtle discrepa
arxiv.org
<code>
GitHub - chou141253/FGVC-HERBS: Pytorch implementation of "Fine-grained Visual Classification with High-temperature Refinement a
Pytorch implementation of "Fine-grained Visual Classification with High-temperature Refinement and Background Suppression" - GitHub - chou141253/FGVC-HERBS: Pytorch implementation of &quo...
github.com
궁금해서 논문 읽어보고 싶었는데 코드가 없어서 일단은 킵해둿었던 페이뻘rrr~
최근에 코드가 공개된 김에 잘댓다싶어서 읽어보려고 함!!
그런데 보니까 selector-combiner구조인거같은데 기본아이디어는 plug in module과 비슷한거 같아서
어떤게 달라진건지 확인해보고자 한다.
논문정리
Abstract
FGVC는 카테고리 간의 높은 유사성과, 같은 카테고리 내에서도 뚜렷한 차이가 있어 분류하기 어렵다.
이전에는 카테고리간 미묘한 차이들을 찾아내고 차별성있는 특징을 향상시키는 데 초점을 두었는데, 배경 정보 또한 모델이 어떤 특징이 불필요한지, 혹은 어떤 특징이 분류에 방해되는지 파악할 수 있는 중요한 정보가 된다.
또한, 모델이 너무 미묘한 특징들에 의존하게 되면 전역특징이나 contextual information을 간과할 수 있다.
본 논문에선 "High TemperaturE Refinement and Background Suppression" (HERBS)를 제안하였다.
high-temperature refinement module & background suppression module로 구성
각각 차별성있는 특징을 추출하고 배경 잡음을 억제한다.
High temperature refinement module은 feature map을 여러 scale로 정제하고 다양한 특징들을 학습하여 모델이 적절한 feature scale을 학습하도록 한다.
Bckgounrd supprssion module은 먼저 feature map을 classification confidnece score을 이용하여 foreground와 background로 분할하고, confidence가 낮은 영역의 특징 값들을 억제하며 차별성있는 특징들을 강화한다.
실험결과를 통해 제안된 HERBS가 효과적으로 다양한 scale의 특징들을 융합하고, 배경잡음을 억제하고, 적합한 scale의 feature들을 효과적으로 찾아냄을 보여준다.
CUB-200-2011, NABIRDS에 대해 SOTA를 달성하였다.
Introduction
Fine-grained 이미지 인식(FGVC)은 카테고리를 구체적이고 상세하게 분류해야하기 때문에 어려운 과제이다.
새, 개의 각기 다른 종들, 차량 모델, 의료 이미지 등

그림 1에서, 각기 다른 Sparrow가 있지만 생김새는 거의 비슷하지만 다른 특징을 가지고 있다. 또한, 같은 타입의 sparrow여도 다른 점이 있다.
coarse-grained 분류에서는 "동물", "차량" 같이 넓은 부류의 카테고리를 구별하지만, fine-grained 분류에서는 색감, 텍스쳐, 모양, 패턴 등 작은 영역에 존재하는 시각적 특징으로 부터 미묘한차이를 인식할 수 있어야 한다.
이런 영역을 discriminative region, foregound region이라 부른다.
Fine-grained 인식은 객체를 눈, 발 등과 같이 요소로 분할하고, 대응하는 영역들을 비교한다.
하지만, 이런 방법은 manual annotation을필요로 하기 때문에 비용이 많이 들고 때로는 전문가를 요한다.
이런 문제를 해결하기 위해, CAM을 통해 차별성있는 영역을 찾는 weakly supervised 방법을 제안하여 네트워크가 반응이 높은 영역들을 통해 라벨 없이 훈련할 수 있도록 한다.
(근데 swin transformer에서 cam을 어떻게 사용했지? gradcam을 썻나..)
게다가 어텐션 기반 방법들을 제안하여 feature map간 공통으로 높은 반응을 갖는 영역을 찾아 차별성있는 영역을 찾는다.
게다가, ViT가 이미지분류에서 성공하면서 fine-grained 이미지 인식 작업에서도 사용할 수 있게 되었다.
selt attention 맵을 이용하여 foreground 영역에 대한 정보를 얻는다.
차별성있는 영역에서의 차별성을 강화하고 선택되지 않는 영역을 무시한다
하지만, 모델이 충분히 차별성있는 영역을 얻지 못한다면, 먼저 중요하지 않은 영역, 즉 배경을 제외하는 것이 도움이된다.
이 컨셉을 배경으로 Backgroud Suppression (BS) module을 제안하였다.
제안된 BS 모듈은 FGVC 과제에서 좋은 성능을 보였다.
BS 모듈의 첫 단계에서는, output confidence score을 활용하여 영역을 foreground와 background로 분류한다.
Foreground는 차별성있는 영역을 나타내며, background은 선택되지 않은 잡음 요소를 의미한다.
이후, Bs 모듈은 low confinde 영역의 특징 값들을 억제하고, 차별성있는 영역을 강화하여 타겟 객체의 디테일을 향상시키고 노이즈를 줄인다.
따라서, BS 모듈은 foreground와 background 영역을 구별하기 힘든 경우에 특히 유용하게 된다.
차별성있는 영역으로부터 특징을 추출하는 알고리즘은 FGVC에서 중요하다.
특징에서 단일 혹은 소수의 특정 카테고리의 정보를 많이 사용하다보면 contextural 정보를 잃을 수도 있다.
따라서, high temperature refinement module로 다양한 객체 카테고리로부터 텍스쳐, 모양, 외형 등 여러 특징을 학습할 수 있도록 한다.
이 모듈은 먼저 higher temperature을 이용하여 특징맵을 학습하고 이로써 전역적인, contextural 정보를 포착한다.
이후, 특징맵을 정제하여 lower temperature을 이용해 더 미묘한 detail들을 포착한다.
이로 인해 풍부한 특징들을 획득하고, 비슷한 객체들을 더 잘 분류하며, 정확도를 높인다.
high temperatuer refinement module이 지식 증류(knowledge distillation)의 형태로 간주될 수 있다.
High temperatuer refinement module은 또한 차별성 있는 영역의 적절한 사이즈를 유지하는데, 이것이 FGVC 작업에서 강점이 된다.
특징 사이즈가 너무 작으면, 알고리즘이 객체의 전체적인 특징을 포착하지 못하여 부정확하게 분류할 수 있다.
반면, 특징 사이즈가 너무 크면 잡음이 많고 중복정보로 인해 FGVC 작업의 정확도가 감소된다.
본 논문에선, High TemperaturE Refinement and Background Suppression(HERBS)를 제안하여 차별성있는 특징을 추출하고 배경 잡음을 억제한다.
본 논문의 main contributions
- 제안된 HERBS는 CNN 기반의 네트워크나 트랜스포머 기반의 네트워크과 같은 여러 백본들을 통합할 수 있다. end-to-end 훈련을 수행할 수 있음.
- 제안된 HERBS는 여러 분야에서 SOTA를 달성하였다. CUB200-2011, NABirds에서 각각 93.1%, 93.0%를 달성하였음
Related Works
개인적으로 읽고 skip 중요한 부분만 기록함
Attention Based Methods
- API Net, PCA-Net : use two images as input to calculate attention between feature maps to enhence discriminative rerpesentations
- SR-GNN : uses graph convolutional neural networks to describe the releationship between parts
Object Detecion
-WSOD2 : scores virtual candidate boxes through Top-Down and Bottom-Up approaches, with the virtual box with the highesst score serving as the target output for the next layer
Method

그림 2는 제안된 HERBS 네트워크이며, 백본 네트워크와 top-down 식의 특징 융합 모듈, bottom-up 방식의 특징 융합 모듈과 HERBS를 보여준다.
백본네트워크는 Transformer기반의 모델 (e.g., swin transformer)이거나 Convolution 기반의 모델(e.g., resnet)일 수 있다.
Top-down과 bottom-up 방식의 특징 융합 모듈은 PA(path aggregatio network)와 유사하며, bottom-up path가 추가된 FPN(feature pyramid network)로 볼 수 있다.
제안된 HERBS 네트워크는 다양하고 차별성있는 특징들을 학습하고, FGVC 작업에서의 정확도를 향상하는것을 목표로 한다.
두 개의 모듈로 구성되어 있다.
BS(Background suppresssion) module, High-teperature refimenet module
<Background suppression>
ith번째 백본 블록에서 생성된 특징맵을 hsi라 하자.
이때, hsi∈RCi×Hi×Wi
Ci : 채널 수
Hi : 특징맵의 높이
Wi : 특징맵의 너비
BS module의 첫번째 단계는 이 특징맵으로부터 classification map을 생서하는 것이다.
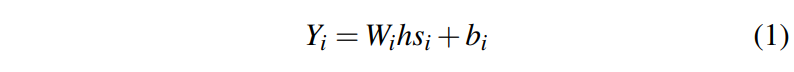
Wi : ith번째 layer classifier
bi : 그 때의 bias
Yi : classification map (차원은 Cgt×Hi×Wi)
* Cgt는 타겟 카테고리 수
Maximum score map은 classification map으로부터 식 2를 통해 얻는다.
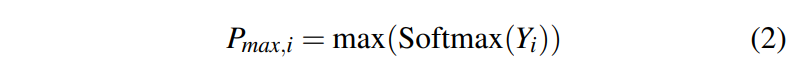
Pmax,i : i번째 층의 max score map
이후, 모든 예측들 중에서 top-Ki의 socre의 특징들만 선택된다.
이때 Ki의 값은 i<j일때, Ki>Kj의 원칙을 따른다.
본 논문에선 K1=256,K2=128,K3=64,K4=32로 설정하였다.
이 값은 초기의 레이어가 이후의 레이어의 성능을 제한할 수 있다는 원칙을 반영하였다.
이 원칙이 지켜질 경우, 파라미터 값이 바뀌어도 정확도가 상대적으로 덜 영향을 받는다는 것을 실험을 통해 증명함.
이후, 그래프 컨볼루션 모듈을 적용하여 선택된 특징들을 융합하고 이 융합된 특징들을 이용하여 예측을 진행한다.
이 단계에서는 BS 모듈이 선택되지 않은 classification map을 가지게 되는데, 이후 dropped maps로 지칭하며, Yd로 표기.
또한, 융합된 classification prediction은 Ym으로 표기한다.
이 과정은 selector와 combiner의 구성요소로 그림 2에 그려져있다.
merged classificaion prediction의 목적함수는 가장 기본적인 크로스엔트로피를 사용하여 예측 분포 Pm과 ground truth label인 y와의 유사도를 구한다.
merged loss는 아래과 같이 구한다.
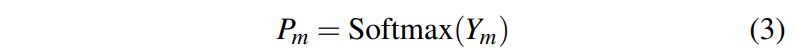
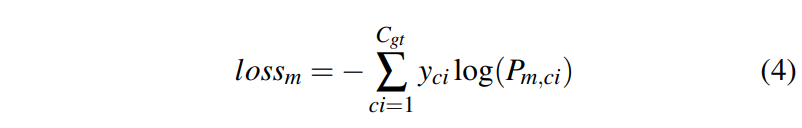
yci : i번째 클래스의 ground truth
Pm,ci : i번째 클래스의 예측 확률
타겟 카테고리 수 Cgt만큼 summation을 수행하낟.
이는, 선택된 영역의 차별성있는 특징들을 강화한다.
BS 모듈은 또한 dropped maps의 특징들을 억제하고, foreground와 background의 차이를 키우는 역할을 한다.
하이퍼볼릭 탄젠트 함수 tanh가 dropped maps Yd에 적용된다. (식 5)
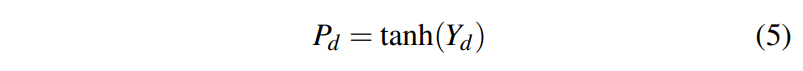
이후, dropped loss, lossd는 prediction과 pseudo target인 -1과의 mean squred error를 통해 얻는다.
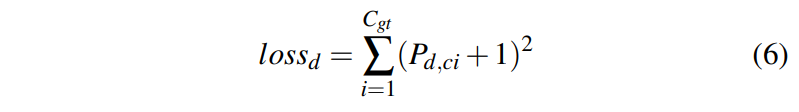
이때, 식 5에서 하이퍼볼릭 탄젠트 함수는 값들을 함수로 매핑하지 않는다. (즉, [0,1)의 값으로 제한되지 않는다)
이는 background에 객체의 외향이 조금 포함되어 있어도 foreground와 background 특징들을 분리하기 위함이다.
모든 block의 특징맵들이 동일한 위치에서 높은 response를 갖는 것을 막기 위해, 다음과 같이 통합하였다.
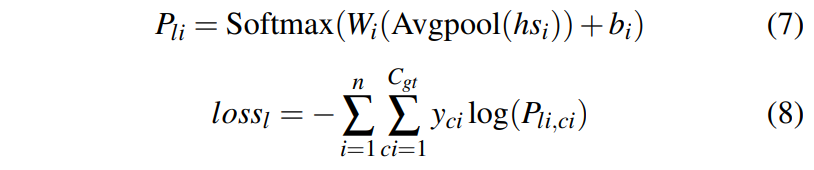
이때 Avgpool 함수는 각채널에서 모든 Hi,Wi을 aggregate하고, n은 백본의 총 블럭수를 나타낸다.
최종 BS objective는 merged loss (lossm), dropped loss (lossd), average layer loss (lossl)의 합으로 나타낸다.
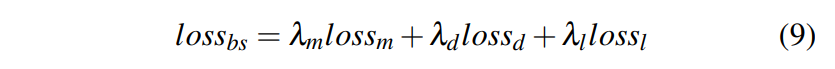
이때, λm,λd,λl은 merged loss, dropped loss, average layer loss의 가중치가 된다.
λm=1,λd=5,λl=0.3으로 세팅하였다.
이 값은 foreground와 background 손실의 균형을 잡기 위해 설정하였으며, 첫 세 에폭의 훈련 손실을 기준으로 결정하였다.
<High-temperature refinement>
그림 2 내의 분류기 k1와 분류기 k2는 k번째 블록 특징맵 이후에 배치된다.
분류기 k1은 top-down path내에, 분류기 k2는 bottom-up 쪽에 위치하였다.
분류기 k1가 분류기 k2의 출력 분포를 학습하는 것이 목적이다.
분류기 k1의 출력을 Yi1, 분류기 k2의 출력을 Yi2로 정하였다.
refinement의 목적함수는 모델이 다양하고 강력한 표현을 초기레이어에 학습하며 동시에 후속 레이어에서는 미묘한 디테일에 집중하도록 한다.
즉, high-temperature refinement module은 분류기 k1이 더 넓은 영역을, 분류기 k2가 더 fine-grained하고 차별성있는 특징을 발견하도록 한다.
Refinement loss는 다음의 수식을 통해 계산할 수 있다.
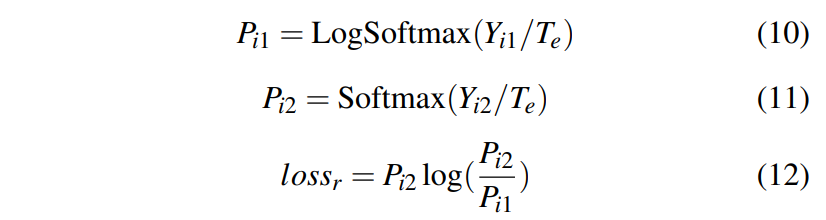
Te : 훈련 에폭 e에서의 temperature
Te의 값은 다음의 식을 통해, 훈련이 진행될수록 값이 작아진다.
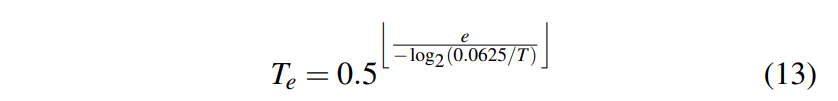
초기의 temperature T는 64, 128과 같은 높은 값으로 설정하였다.
knowledge disstillation approach [11] 에 비해
이는 모델이 초기 예측이 부정확할지라도 다양한 특징들을 탐험하게 하기 위함이다.
이후, 훈련이 진행될수록 temperature은 점진적으로 감소하며, 모델이 타겟 클래스에 더욱 집중하여, 차별성있는 특징들을 학습하도록 한다.
이 감쇄 전략을 통해, 모델이 다양하고 좋은 표현들을 획득하고, 예측을 정확하게 한다.
최종 HERBS의 손실은 아래와 같다.
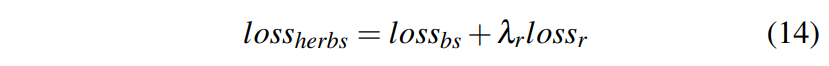
이때, λr은 refinement loss의 가중치이며 1로 설정하였다.
HERBS 네트워크의 최종 출력은 9개의 분류 결과의 합산값을 softmax를 거쳐 얻는다.
4개의 top-down approach, 4개의 bottom-up appraoch, 1개의 combiner
HERBS 네트워크에서, Wi,bi은 i가 k일때 분류기 k2에 속한다.
BS 모듈과 high temperature refinement module을 백본에 단독으로 적용할 수 있어 flexible하기 때문에 따로 기술하였다.이게 무슨말이고,,,
실험 결과를 통해 두 개의 모듈이 정확도를 향상시켰음을 보여준다.
물론 전체 HERBS 네트워크를 사용했을 때, 모델이 더 좋은 결과를 보여준다.
본 논문에선, HERBS 모듈을 제안하였다.
이는, Background Suppression, high-temperature refinment module로 이뤄져있으며 둘 모두 백본 모델의 FGVC 작업 정확도를 개선하였다.
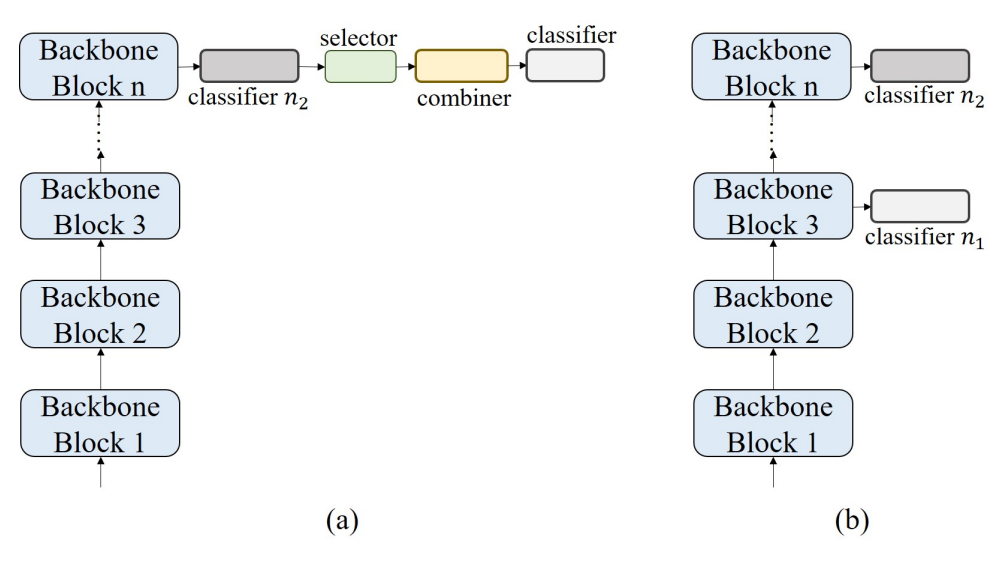
기본적인 BS, high-temperature refinement module은 그림 3의 (a), (b)로 보여준다.
가장 기본적인 기본 BS 모듈이 최종 블록의 출력에 추가되고, 식 1~9를 계산한다.
가장 기본적인 High-temperature refienment module이 마지막 2개의 블럭에 추가된다.
이때, 최종 분류가 분류기 n2로 간주되고, 그 전 분류기가 n1
식 12에서는 KL-divergence를 목적함수로 사용한다.
Introduction
<Matrix Factorization Method>
단어 유추
내용