

논문정보
Object-Part Attention Model for Fine-grained Image Classification
Object-Part Attention Model for Fine-grained Image Classification
Fine-grained image classification is to recognize hundreds of subcategories belonging to the same basic-level category, such as 200 subcategories belonging to the bird, which is highly challenging due to large variance in the same subcategory and small var
arxiv.org
<code>
GitHub - PKU-ICST-MIPL/OPAM_TIP2018: Source code of our TIP 2018 paper "Object-Part Attention Model for Fine-grained Image Class
Source code of our TIP 2018 paper "Object-Part Attention Model for Fine-grained Image Classification" - GitHub - PKU-ICST-MIPL/OPAM_TIP2018: Source code of our TIP 2018 paper "Object...
github.com
논문정리
Abstract
Fine grained 이미지 분류는 기본적으로 같은 카테고리에 속하는 수백개의 하위 카테고리들을 분류하는 작업이다.
같은 하위 카테고리내에서도 편차가 크고 다른 하위카테고리 간 유사도가 높기 때문에 어렵다.
기존의 방법들은 먼저 객체나 특정 part의 위치를 찾은 후 그 이미지가 어떤 하위 카테고리에 속하는지 찾아낸다.
하지만 (1)객체와 부분 (위치)에 대한 주석이 있어야 하고 이는 labor consuming (2)객체와 부분이나 부분들간의 공간 정보를 무시하게 된다는 한계점이 있다.
따라서, 본 논문은 weakly supervised fine grained image classification을 위해 OPAM(object part attention model)을 제안한다.
첫번째로, Object-part attention model은 두 단계의 어텐션을 통합 : object-level attention을 통해 객체의 위치를 찾아내고, part-level attention을 통해 객체에서 차별성있는 부분을 찾아낸다. 두 어텐션을 함께 사용하여 multi-view, multi-scale의 특징들을 학습하여 상호 보완함
두번째로, Object-part spatial constraint model은 두 개의 spatial constraint를 결합한다 : object spatial constraint는 선택된 부분의 표현력이 높음을 보장하고 part spatial constraint는 중복을 제거하고 선택된 부분의 차별성을 강화한다.
두 가지 모두 미묘하고 작은 차이들을 찾아내서 하위 카테고리를 구별하기 위해 사용된다.
중요한 건, 객체나 part의 주석(라벨링)이 전혀 사용되지 않는 다는 것, 따라서 라벨링을 위한 엄청난 노동력을 피할 수 있다. 4가지 주요 데이터셋에 대해 10개 이상의 SOTA 방법들과 비교해서 OPAM 접근법이 가장 좋은 성능을 달성했다.
Introduction
일반 이미지 분류는 새인지 차인지만 구별하면 되지만 fine-grained이미지 분류는 하위 카테고리를 더 세밀하게 분류해야 한다.

그림 1은 basic-level과 fine-grained 이미지 분류의 차이를 보여준다.

그림2는 같은 하위카테고리 내의 큰 분산과, 다른 하위카테고리 내 분산은 작다는 것을 보여주며, 따라서 사람이 수백개의 하위 카테고리를 분류하기는 힘들다.
객체의 외향 변화가 작기 때문에, 미묘하고 로컬한 차이가 fine-grained 이미지 분류하는데 주요 요소가 된다.
하지만 이 미묘하고 작은 차이가 객체와 그 일부 내 차별성있는 영역에 위치하기 때문에 대부분의 접근법은 먼저 객체와 요소(part)의 위치를 이미지 내에서 찾고, 그 후 어떤 하위 카테고리에 속하는지 찾아내는 방향으로 진행한다.
그러면 차별성있는 객체와 부분의 위치를 찾기 위해선, bottom-up 방법으로 objectness가 높은 이미지 패치를 생성하는 것이 먼저다. 즉, 생성된 패치가 차별성있는 객체와 요소를 포함해야 함.
Selective sesarch는 이런 이미지 패치들을 수천개 생성할 수 있는 비지도 방법이다. bottom-up 방식은 recall이 높고 precision이 낮기 때문에, top-down attention model을 사용하여 노이즈가 많은 이미지 패치를 제거하고 개체나 차별적인 요소를 포함할 수 있도록 해야 한다.
fine-grained 이미지 분류에선 객체를 찾는 것과 차별적인 요소를 찾는 것을 두 단계 어텐션 과정으로 볼 수 있다.
object-level과 part-level
직관적으로는 객체 주석 (e.g., 바운딩 박스)을 사용하여 object-level attention을, 요소 주석 (part의 위치)을 사용하여 part-level attention을 사용하는 것이다.
대부분의 방법은 이런 객체나 요소의 주석에 의존해서 객체나 차별적인 요소를 찾는데, 이런 라벨링 작업은 노동력이 많이 소요된다. 이것이 첫번째 한계.
이 문제를 해결하기 위해, 객체나 요소의 주석 없이도 weakly supervised 환경에서 성능을 얻기 위한 방법들이 연구되고 있다. (훈련, 테스트 모두)
[14]는 part cluster에서 유용한 정보를 추출하여 차별성있는 요소를 찾을 수 있도록 제안하였다.
[7]은 자동으로 fine-grained 이미지 분류방법을 제안하여 part 선택과 descriptoin을 심층 컨볼루션 필터를 통해 통합한다.
하지만, 차별성있는 요소를 선택하면, 객체와 그 요소간의 공간정보, 혹은 요소들끼리의 공간정보가 무시되는데 이또한 매우 중요한 정보이다.
이 때문에 선택된 요소가 (1) 큰 영역의 배경 노이즈와 작은 영역의 객체로 이뤄지게 되고, (2) 서로간 크게 오버랩되어 중복된 정보가 생긴다.
이것이 두번째 한계.
이 두 한계점을 해결하기 위해, 본 논문에서는 object-part annotation model (OPAM)을 제안하여 weakly supervised fine-grained image clasification을 수행한다.
key point
Object-Part Attention Model
많은 연구들이 객체나 요소의 주석을 사용한다. 이는 노동력이 많이 소요되는 작업임.
이 문제를 해결하기 위해, object-part attention model을 제안하여 weakly supervised fine-grained 이미지 분류작업에서 객체와 요소의 주석을 피하고 실용적으로 활용될 수 있도록 한다.
두 가지의 어텐션을 통합한다.
(1) Object-level attention model은 CNN의 GAP을 통해 이미지 내에서 객체를 찾기 위한 saliency map을 추출한다.
(Saliency Map은 픽셀값의 변화가 급격한 부분을 모아서 매핑하는데, Gradient Descent를 사용하여서 변화가 큰 부분을 찾음)
(2) Part-level attention model은 먼저 차별성있는 요소를 찾아 신경망의 cluster pattern을 따라 정렬한다. 이를 통해 미묘하고 로컬한 특징을 학습할 수 있다.
객체수준 어텐션(object-level attention)모델은 대표적인 객체의 외향에 집중하고, 하위 카테고리간 요소들의 분별력있고 구체적인 차이점에 집중한다.
이 둘을 동시에 사용하여 multi-view, multi-scale 특징학습을 하고, 이후 fine-grained 이미지 분류에서 좋은 성능 달성
Object-Part Spatial Constraint Model
많은 weakly spervised 방법들은 객체와 요소, 혹은 요소간의 공간 정보를 무시하는데 이 또한 차별성 있는 요소를 선택하는 데 매우 중요한 부분이다. 이 문제를 해결하기 위해 spatial constraint model을 사용하여 요소를 선택한다. 두 가지 유형의 sptial constraint를 결합한다.
(1) Object spatial constraint은 객체 영역 내에서 요소가 선택되게 하고, 이가 높은 표현력을 가질 수 있도록 한다.
(2) Part spatial constraint은 요소 간 겹치는 영역을 제거하여 요소의 두드러진점을 강조한다. 이렇게하면 선택된 요소간 차별성을 강화하고 중복을 제거하게 된다.
이 두가지의 공간 제약조건을 결합하여 객체 선택의 차별성을 촉진시킬뿐만 아니라 fine-grained 이미지 분류에서 눈에 띄는 성능 향상을 가져온다.
본 연구진의 이전 논문에서는 두 가지 어텐션을 통합하였는데 객체수준 어텐션은 객체와 관련된 이미지 패치를 선택하고,
요소수준 어텐션은 차별성있는 요소를 선택한다.
이는 훈련과 검증 단계에서 모두 객체와 요소의 주석 없이 fine-grained 이미지를 분류한 첫번째 연구라고 한다.
이 논문에서는 OPAM 접근이 두 단계의 어텐션을 심층적으로 활용하여 차별성있는 요소 뿐만 아니라 객체까지도 찾아낼 수 있도록 한다. 그리고 object-part 공간 제약(spatial constraint)을 통해 중복을 제거하고 선택된 요소의 차별성을 도드라지게 한다.
4개의 주요 데이터셋에 대한 SOTA 방법 10개와 비교해봐도, OPAM 접근법이 좋은 성능을 보여주는 것을 확인할 수 있다.
Related Work
시간상 skip 너무 바쁨티비..
Our OPAM Approach
직관적인 아이디어로부터 시작한다
Fine-grained이미지 분류는 일반적으로 객체의 위치를 찾고 (object-level attention), 이 후 차별성있는 영역을 찾는다(part-level attention)
예를들어,이미지 내에서 들새를 인식하다고 하면, 첫 번째로 새를 찾고, 이후 다른 하위카테고리와 구분되는 차별성있는 요소를 찾는 과정으로 진행
object-part attentoin model를 제안하여 weakly supervised fine-grained 이미지 분류를 실행하는데,훈련과 검증 단계에서 모두 object와 part의 어떤 주석도 사용하지 않는다.
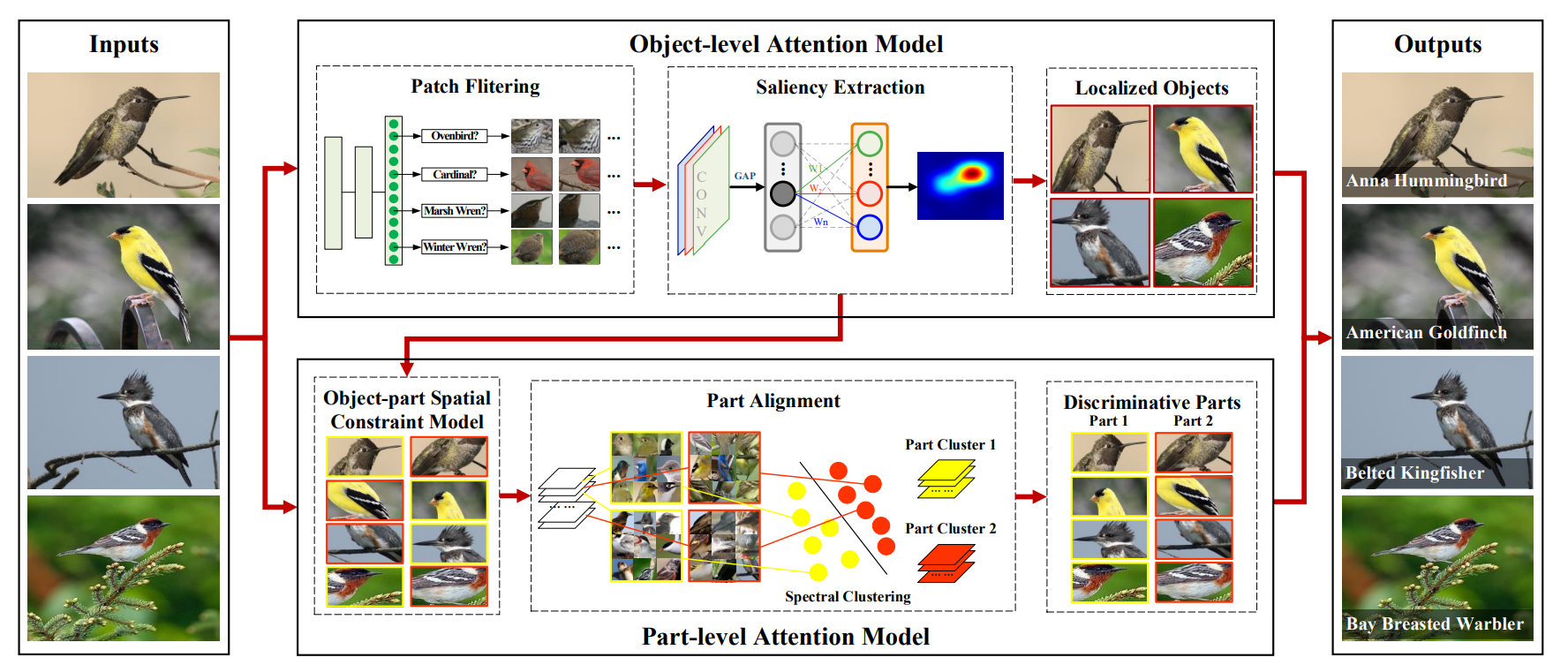
그림 3을 보면, OPAM은 첫번째로 이미지 내에서 객체의 위치를 찾고, 이후 part-level attention을 통해 차별성있는 요소를 선택해 미묘하고 지역적인 특징들을 학습한다.
<Object-level Attention Model>
많은 weakly supervised 연구들은 차별성있는 영역을 선택하는 것에 집중하여, 배경 잡음의 영향을 제거하고 의미있고 표현력 높은 객체 특징을 학습할 수 있는 object localizaton을 무시한다.
몇몇 연구들이 object localization과 part selection을 동시에 사용하긴 하지만, 이는 object와 part의 주석에 의존하는 방법이다. (즉 바운딩박스 같은..)
이 문제를 해결하기 위해 어떠한 주석 없이 하위카테고리 라벨만을 이용한 saliency extraction을 통해 object-level attention모델을 제안한다.
모델은 두 가지로 구성된다
patch filtering and saliency extraciton
patch filtering은 노이즈있는 이미지 패치를 걸러내고, 객체와 관련된 패치를 유지하여 ClassNet으로 불리는 CNN을 훈련시켜 mult-view, multi-scale한 특징을 학습하도록 한다.
saliency extraction은 이미지 내에서 객체의 위치를 찾아내기 위해 CNN의 GAP을 사용하여 saliency map을 얻는다.
Patch Filtering
CNN의 성능을 위해선 많은 양의 훈련 데이터가 필요하다. 따라서 어떻게 훈련 데이터를 확장할 수 있는지에 집중한다.
bottom-up process를 통해 객체와 관련된 영역 내의 픽셀을 그룹화하면서 이미지 패치 후보들을 수천개 생성할 수 있다.이이런 이미지 패치들은 객체와 관련된 부분이기 때문에 훈련데이터의 확장으로 사용될 수 있다.
따라서, selective search를 이용하여 주어진 이미지에 대해 여러 후보 이미지 패치들을 생성하는데 이는 bottom-up process에서 널리 쓰이는 비지도 방법이다.
이러헥 생성된 이미지패치 후보들은 기존 이미지에 대해 multiple view, scale을 제공하여 CNN이 fine-grained 이미지 분류에서 더 높은 정확도를 얻도록 돕는다.
하지만, 이런 패치들은 recall이 높고 precision이 낮기 때문에 직접적으로 사용될 순 없다
이 경우엔 노이즈가 존재할 수 있기 때문
Object-level attention 모델은 객체와 관련된 패치들을 선택하는데 유용하다.
우리는 FilterNet으로 불리는 CNN을 통해 잡음이 있는 패치들을 제거하고 관련있는 패치들을 선택한다.
ImageNet1k로 사전훈련 한 후, 훈련 데이터에 대해 파인튜닝하였음
소프트맥스 층에서의 뉴런 활성화를 selection confidence scroe로 간주하여, 이 후 임계값을 설정한 후 어떤 후보 이미지 패치가 선택되어야할지를 결정한다.
이렇게 객체와 관련된 multi view, multi scale의 이미지 패치들을 획득한다.
훈련 데이터의 확장은 ClassNet의 훈련 효과를 개선하며, OPAM 접근은 다음의 장점이 있다.
- ClassNet은 그 자체로 fine-grained 이미지 분류에 효과적이다
- 내부의 특징은 같은 semantic meaning을 가지는 요소들을 정렬하는 part cluster를 구축하는 데 효과적이다. (이후 섹션에서 소개)
중요한 것은 patch filtering은 훈련 단계에서만 수행되고, 이미지 수준의 하위 카테고리 라벨만을 이용한다는 것이다.
Saliency Extraction
이 단계에서는 CAM을 이용하여 saliency map $M_c$를 획득하여 객체의 위치를 찾는다.
하위 카테고리 c에 속하는 이미지

saliency map은 이미지의 하위카테고리를 구분하기 위해 CN을 사용해 표현력이 높은 영역을 나타낸다
(그림 4의 두번째 행 참고)
그러면 이미지 내 객체의 영역은 그림 4의 3번째 행에서 확인할 수 있는데, saliency map 상에서 binarization을 수행하고 connectivity area를 추출하여 얻을 수 있다.
binarzation
색상 또는 그레이스케일의 이미지의 각 픽셀 값을 0혹은 1로 서정하여 바이너리 이미지 생성
connectivy area extraction은
위에서 만들어진 binary image에서 서로 연결된 픽셀의 그룹을 찾아내는 과정
이를 통해 이미지 내에서 개별적인 물체 영역을 식별할 수 있음
이미지 $I$에 대해, 마지막 컨볼루션 층내에서 $(x,y)$에 위치한 뉴런 $u$의 활성화는 $f_u(x,y)$로 표현하고 $w_u^c$는 뉴런 $u$에 대해 하위 카테고리 $c$와 관련된 가중치를 나타낸다..
특정 위치 $(x,y)$에서 saliency value는 식1로 계산한다
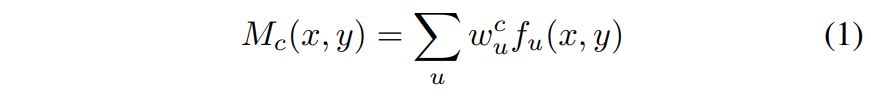
(해당 뉴런이 활성화가 된 경우에만 가중치 값을 가져오는 듯..)
$M_c(x,y)$는 특정 위치 $(x,y)$에서 하위카테고리 $c$로 이미지를 분류하기 위한 활성화의 중요도를 반영한다.
이미지 수준에서의 하위카테고리 라벨을 사용하는 것 대신, 각 이미지에 대한 saliency extraction에서 예측 결과를 하위 카테고리 c로 사용한다.
object-level attention 모델을 통해 이미지 내에서 객체의 위치를 찾고, object level attention을 얻기 위해 ObjectNet으로 불리는 CNN을 훈련한다.
아니 모델이 몇개야... 여기까지만 해도 3개네
<Part-level Attention Model>
차별성있는 요소 (머리나 몸,...)는 fine-grained 이미지 분류에서 중요하다.
이전의 연구들은 selective sarch와 같은 bottom-up 과정을 통해 생성된 이미지 패치 후보로부터 차별성있는 요소를 선택하였다.
하지만, 이런 방법은 part annotation에 의존하게 되어, 많은 노동력이 필요하다.
딱히 주석이 없이도 차별성있는 요소를 찾기 위한 연구들이 있었지만, 이들은 객체와 요소 혹은 요소 간의 공간 정보를 무시한다.
따라서, part-level attention으로부터 새로운 요소 선택 접근을 제안하여 어떠한 주석 없이도 하위카테고리를 구별하는 미묘하고 지역적인 차이를 찾아낸다.
두가지의 구성요소가 있다
object-part spatial constraint model, part alignment
object-part spatial constraint model은 차별성있는 요소를 선택하고 part alignment는 선택된 요소를 semantic meaning을 기반으로 cluster로 정렬한다.
Object-part Spatial Constraint Model
object-level attention model을 통해 이미지에서 객체에 해당하는 영역을 얻었다. 그러면 이제는 object-part spatial constraint model을 이용하여 bottom-up process로 생성된 이미지 패치 후보들롭터 차별성있는 요소를 선택한다.
두개의 공간제약들을 동시에 고려한다.
object spatial constraint 객체와 요소 사이의 공간 정보를 정의
part spatial constraint 요소 상이의 공간 정보를 정의
이미지 $I$에 대해 object-level attention model을 통해 saliency map $M$과 객체 영역 $b$을 얻는다.
이후, part selection은 object-part spatial constraint model에 의해 아래와 같이 수행된다.
먼저, $\mathbb{P}$는 모든 이미지 패치 후보들을 표현한다.
$P = {p_1, p_2, \cdots, p_n}$은 각 이미지에 대해 차별성있는 요소로 $\mathbb{P}$로부터 선택된 $n$개의 요소들을 나타낸다.
object-part spatial constraint model은 두 개의 spatial constraint 결합을 고려하여 아래 최적화 문제를 풀고자 한다.
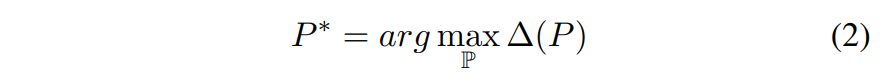
이때, $\Delta(P)$는 두 spatial constraint에 대한 scoring 함수 (식 3과 같다)
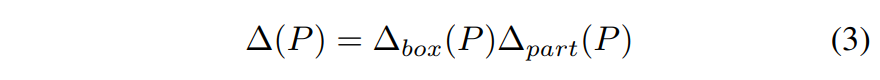
식 3이 제안된 object-part spatial constraint을 정의한다.
이는 선택된 영역의 차별성과 표현능력을 보장함
두 개의 구성요소로 되어있으며, 모든 선택된 요소에 대해 동시에 만족해야 한다.
$\Delta_{box}(P)$ : object spatial constraint
$\Delta_{part}(P)$ : part spatial constraint
이를 보장하기 위해 sum연산이 아닌 곱 연산을 사용하여, 두 개의 constraint을 최적화한다.
Obect spatial constraint
객체와 요소들 사이의 공간 정보를 무시하면 선택된 요소가 넓은 영역의 배경 잡음과 작은 영역의 분별력있는 영역을 가질 수 있다. 이렇게 되면 선택된 요소의 표현성이 떨어진다.
차별성있는 요소는 객체 영역 내부에 존재하기 때문에, 직관적인 spatial constriant함수는 아래와 같이 정의한다.
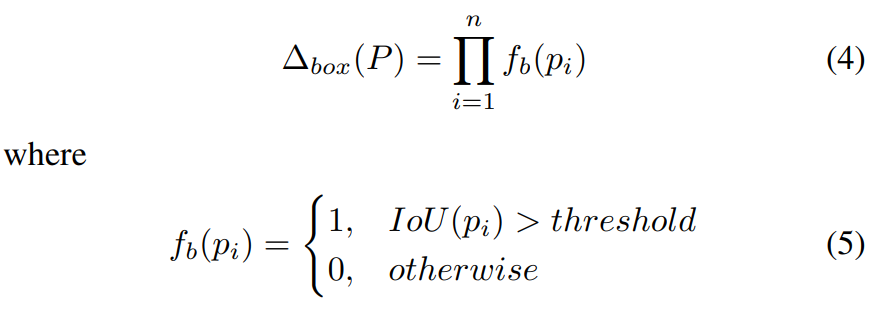
$IoU(p_i)$는 요소 영역과 객체 영역 간 Intersection-over-Union overlap 비율을 의미한다.
객체 영역은 object annotation에서 주어지는 것이 아니라 object-level attention model에서 얻는다는 것이 중요.
Object spatial constraint는 객체 영역 내부에 모든 선택된 요소들을 유지하도록 한다.
따라서 product 연산을 이용하여 이를 보장한다.
즉, 어떠한 요소라도 object spatial constraint를 만족하지 않으면 (즉, $IoU$값이 0이면) 이는 차별성있는 요소로 선택지 않을 것이다.
Part spatial constraint
요소들 간의 공간정보를 무시하면 선택된 요소들끼리 겹치는 범위가 커질 수 있고, 차별성있는 요소들이 무시될 수 있다.
saliency map은 이미지의 차별성을 표현하는데, 차별성있는 요소를 선택하는데 도움이 된다.
saliency와 요소간의 공간 관계를 아래와 같이 모델링한다.
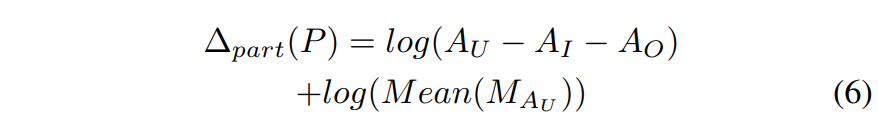
$A_U$ : $n$개의 요소에 대한 union area (요소들을 전체 합친 영역)
$A_I$ : $n$개의 요소들끼리의 intersection area (요소들끼리 겹치는 영역)
$A_O$ : 객체 영역 외부의 영역
$Mean(M_{A_U})$ : 아래와 식 7과 같이 정의
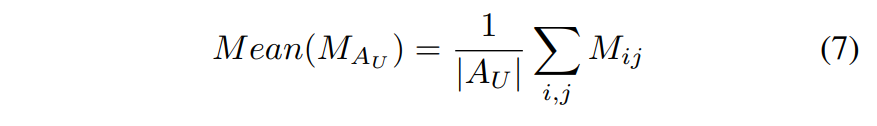
$(i,j)$ 픽셀 : 요소의 union area 내부를 특정
$M_{ij}$ : $(i,j)$픽셀의 saliency value
$|A_U|$ : union area를 나타내는 픽셀의 총 갯수
part spatial constraint는 두 개의 item으로 구성되는 가장 분별력있는 요소를 선택한다.
첫 번째 항은 선택된 요소간 겹치는 영역이 적도록 하며, $log(A_U-A_I-A_O)$로 표현된다.
이때, $-A_I$는 겹치는 영역이 최소가 되도록 하고, $-A_O$를 통해 선택된 요소들이 객체 영역 내부에 있도록 한다.
두 번째 항은 선택된 영역의 saliency를 최대화하며, $log(Mean(M_{A_U})$로 표현된다.
이는, 선택된 패치의 union area내의 모든 픽셀에 대한 saliency value의 평균이다.
식 6의 두 항이 최대값을 갖도록 하고 sum을 적용한다.
Part Alignment
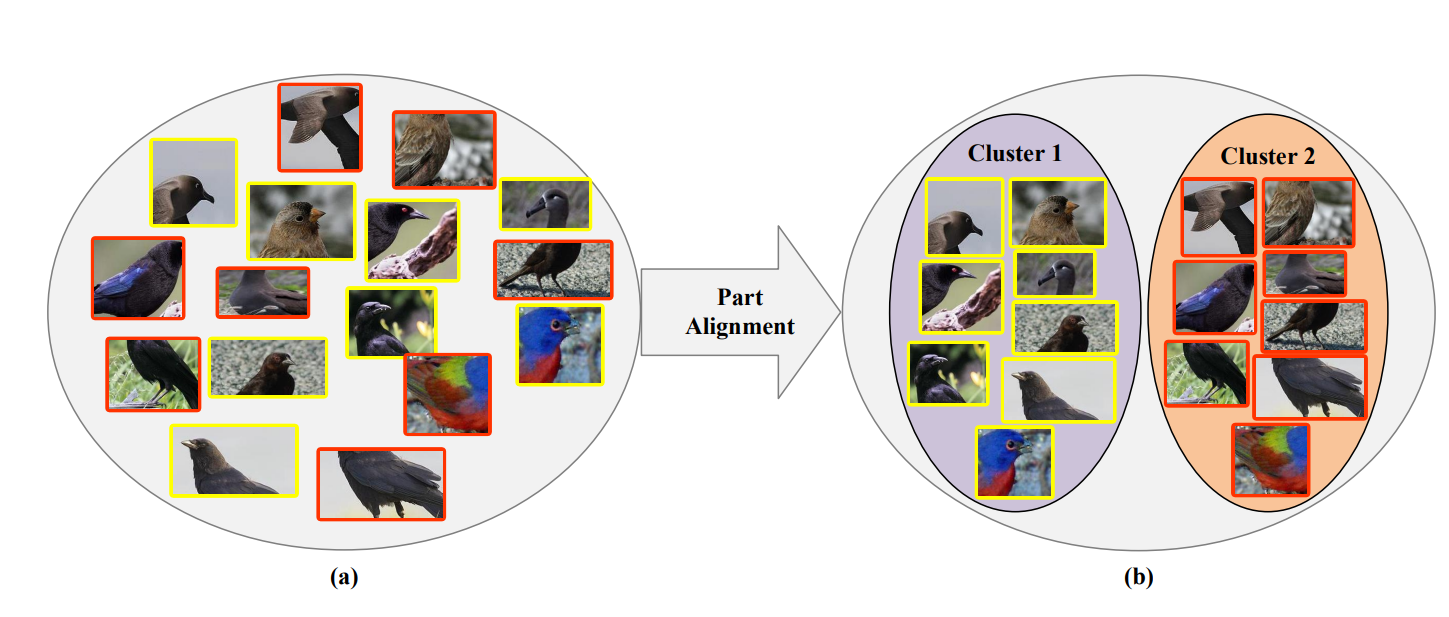
object-part spatial constraint model을 통해 얻은 선택된 요소들은 무질서하고, semantic meaning에 의해 정렬되어 있지 않다. (그림 5(a) 참고)
이렇게 다른 semantic 의미를 갖는 요소들은 최종 예측에 각각 다르게 기여한다. 따라서 요소들을 같은 seamntic의미를 가지는 것 끼리 정렬한다. (그림 5(b)가 되도록)
이는 ClassNet의 중간 레이어가 군집화 패턴을 보인다는 것에서 떠올린 것이다.
예를들면, 다른 포즈에 대응할 수 있음에도, 새의 머리에 유의미하게 반응하는 뉴런과, 새의 몸에 반응하는 뉴런 그룹이 있다.
따라서 ClassNet의 중간 레이어의 뉴런에 대해 클러스터링을 수행하여 선택된 요소들을 정렬하기 위한 part cluster를 구축한다.
먼저, 유사도 행렬 $S$를 계산하여 얻는다. 이때 $S(i,j)$는 두 개의 중간 레이어 뉴런 $u_i, u_j$ 사이의 가중치에 대한 코사인 유사도이다.
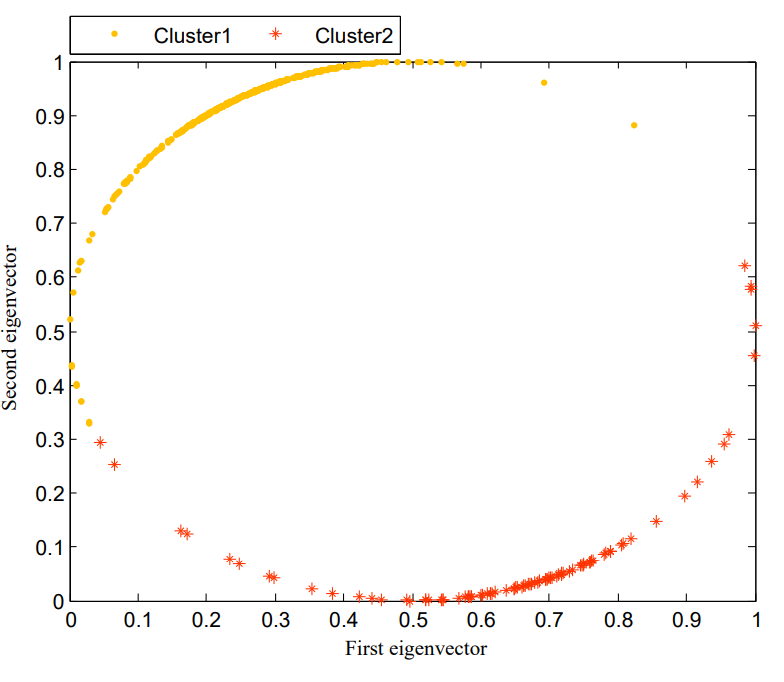
실험에서, 뉴런들은 그림 6에서처럼 m이 2로 설정된 penultimate convolutional layer에서 선택되며, 여기서 좌표 값은 모든 뉴런 중 두 개의 가장 큰 유사도 행렬의 고유벡터를 나타낸다.
penultimate convolutional layer
CNN에서 마지막에서 두번째 컨볼루션 층
이 후, part cluster를 사용하여 선택된 요소들을 아래와 같이 정렬한다.
- 선택된 요소의 이미지를 penultimate convolutional layer의 뉴런 입력 영상에서의 receptive field 크기로 조절한다.
- 각 뉴런에 대한 활성화 점수를 얻기 위해 선택된 요소를 penultimate convolutional layer에 feed forward한다.
- 클러스터 점수를 얻기 위해 하나의 클러스터 내의 뉴런 점수들을 모두 합산한다
- 선택된 요소들을 클러스터 점수가 가장 높은 클러스터에 정렬한다. 이를 위해서는 먼저 이미지가 주어지면 $n$개의 차별성있는 요소 $P={p_1, p_2, \cdots, p_n}$를 object-part spatial constraint model을 통해 얻는다. 이후 알고리즘 1을 따라 이 요소들에 대해 $m$개의 클러스터 L={l_1, l_2, \cdots, l_m}$를 이용하여 part alignment를 수행한다.

어떤 중간 레이어를 선택하는지가 part alignment와 분류 성능에 영향을 준다.
일반적인 관행을 따라, grid search를 위해 훈련데이터의 10%를 검증셋으로 남기고 어떤 레이어를 선택할지 결정한다.
최종적으로는 penultimate convolutional layer가 다른 것들보다 가장 낫다는 것을 발견했다.
part-level attention mode을 통해, 이미지에서 차별성있는 요소들을 선택하여 PartNet이라 불리는 CNN모델을 훈련하고 part-level attention의 예측결과를 얻는다.
<Final prediction>
더 나은 분류 성능을 위해, ClassNet을 localizaed object로 파인튜닝하여 ObjectNet을 얻고, discriminative parts로 파인튜닝하여 PartNet을 얻어 두 개의 분류기를 준비한다.
그럼 총 3개의 분류기를 얻음
ClassNet 기존 이미지
ObjectNet object
PartNet 선택된 차별성있는 패치

object-level attention model은 FilterNet을 이용하여 객체와 관련된 이미지 패치를 multi-view& scale로 선택 (그림 7(a) 참고)
이 이미지 패치를 ClasNet을 통해 표현력있는 특징을 학습하고, saliency extraction을 통해 객체의 영역을 찾음
Part-level attention model로 미묘한 로컬 특징이 있는 분별력있는 요소를 선택 (그림 7(b)참고)
각각의 level (original image, object, parts)은 각기 다른 표현을 가지고 있으며 상호보완적이라 예측을 개선시킨다.
최종적으로 3 단계의 다른 level에서의 예측 결과를 병합한다.
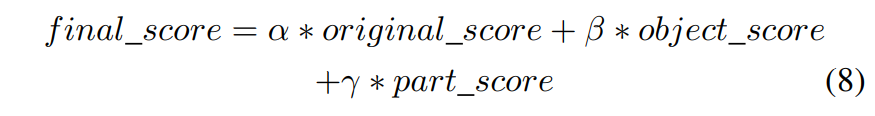
이때 $original_score, object_score, part_score$은 각각 ClassNet, ObjectNet PartsNet에 대한 소프트맥스 값
그리고 $\alpha, \beta, \gamma$는 $k-$fold cross validation 방법에 의해 결정
가장 높은 $final_score$을 가진 하위 카테고리가 최종 예측 결과로 선택된다.