

논문정보
HiFuse: Hierarchical Multi-Scale Feature Fusion Network for Medical Image Classification
HiFuse: Hierarchical Multi-Scale Feature Fusion Network for Medical Image Classification
Medical image classification has developed rapidly under the impetus of the convolutional neural network (CNN). Due to the fixed size of the receptive field of the convolution kernel, it is difficult to capture the global features of medical images. Althou
arxiv.org
<Code>
GitHub - huoxiangzuo/HiFuse: HiFuse: Hierarchical Multi-Scale Feature Fusion Network for Medical Image Classification
HiFuse: Hierarchical Multi-Scale Feature Fusion Network for Medical Image Classification - GitHub - huoxiangzuo/HiFuse: HiFuse: Hierarchical Multi-Scale Feature Fusion Network for Medical Image Cla...
github.com
이건 의료영상 쪽 딥러닝 모델인데 feature fusion 쪽 위주로 읽어보려고 고름
논문정리
Abstract
CNN 이후로 의료영상 분류도 빠르게 발전했다.
컨볼루션 커널의 수용장(receptive field) 크기가 고정되어있기 때문에, 의료 영상의 전역 특징을 포착하기 힘들다.
셀프 어텐션 기반의 트랜스포머가 장거리 의존성을 모델링 할 수 있긴 하지만 local inductive bias가 부족한 게 단점.
많은 연구들이 전역과 로컬 특징이 이미지 분류에 중요하다는 것을 증명했다.
하지만, 의료 영상에는 잡음이 많고, 특징이 흩어져있으며, 클래스 내 분산이 크고, 클래스 간 유사도가 높다.
본 논문은 three-branch hierarchical multi-scale feature fusion network structure (HiFuse)를 제안하여 새로운 방법으로 의료 영상을 분류한다.
이는 Transformer와 CNN의 multi-scale 구조의 장점을 융합하면서도 receptive modeling을 손상시키지 않아 다양한 의료 이미지의 분류 정확도를 향상시킬 수 있다.
로컬과 전역 특징 블록의 병렬적인 계층으로 인해 이미지 크기와 관련된 다양한 크기와 선형 계산 복잡도에서 유연하게 모델링하여 다양한 semantic scale에 대해 로컬 특징 및 전역 표현을 효과적으로 추출할 수 있다.
게다가 적응적으로 hierarchical feature fusion block (HFF block)을 설계하여 각기 다른 계층 레벨에서 얻은 특징들을 완전히 활용할 수 있다.
HFF 블럭은 공간 어텐션, 채널 어텐션, residual inverted MLP, 각 branch별로 다양한 스케일의 특징들간의 semantic 특징들을 적응적으로 융합할 수 있는 shortcut을 포함한다.
ISIC 2018 데이터셋에 대해 제안된 모델의 정확도는 베이스라인에 비해 7.6% 상승하였으며 Covid-19에 대해 21.5%, Kvasir에 대해선 10.4% 상승하였다.
다른 모델과 비교하였을 때, HiFuse 모델의 성능이 가장 좋았다.
Introduction
의료 영상 분류는 컴퓨터 보조 진단, 의료 영상 획득 및 마이닝에서 중요한 작업이다.
최근 몇년간 의료 영상 분류 분야에서 컨볼루션 신경망이 많은 훌륭한 성능을 내었다.
하지만 의료 영상은 imaging modality와 임상병리학에서 높은 유사성과 세부적인 다양성을 가지고 있기 때문에 클래스 내 분산이 크고 클래스 간 유사도가 높고 따라서 전역적인 semantic information을 모델링해아 하는데 이 때문에 의료영상 분류가 힘든 것이다.
트랜스포머는 원래 자연어 처리(NLP) 분야에서 sequence-to-sequence 예측을 하기 위해 모델링 되었다.
현재 트랜스포머는 컴퓨터 비전 커뮤니에서도 많은 관심을 받고 있는데 ViT는 각 이미지를 위치임베딩을 통해 패치화한다.
토큰 시퀀스가 만들어지면 트랜스포머를 통해 복잡한 spatial transformation과 장거리 특징 의존성으로 전역 semantic 정보를 모델링하는 이미지 표현으로써의 parameterized vector를 추출한다.
로컬 공간 특징의 디테일이 부족하기 때문에 Li et al.,은 CNN 특징 맵을 입력 토큰으로 활용하여 이웃 정보의 특징을 포착하도록 제안하였다. 하지만 이렇게하면 이미지를 1차원의 토큰 시퀀스로 모델링하는 것이기 때문에 이미지의 local inductive bias를 무시하는 셈이 되고 따라서 수렴 속도나 성능에 영향을 주게 된다.
ViTAEXu, StoHisNetFu, Transfuse같은 최근 연구는 컨볼루션과 셀프 어텐션 구조에서 추출된 특징들을 융합하여 위의 문제를 어느정도 해결한다.
위의 방법들과는 달리, 의료 분야에서 CNN과 트랜스포머의 장점을 더 활용하기 위해, three-branch의 병렬적인 계층 융합 네트워크 구조를 제안하고 이를 HiFuse라 명명하였으며, 다양한 의료 영상에 대해 분류 정확도를 향상시킬 수 있는 방법을 제시하였다.
ConvNext를 베이스라인으로 삼고 ResNet, Swin Transformer을 참고하여 본 연구진은 로컬과 전역 특징 블럭을 설계하였다.
HFF 블럭은 다양한 semantic 크기에 대해 로컬과 전역 표현을 융합한다.
이 융합 과정은 의료 영상 분류 작어에서 병변 영역의 심층적인, 얕은, 전역적인, 로컬한 특징들을 모두 마이닝할 수 있다.
1, CNN과 트랜스포머의 장점들을 결합하여 로컬과 전역 특징 블럭의 병렬적인 프레임워크를 설계해 각기 다른 규모의 특징에 대한 local spatial context feature, global semantic information representation을 효율적으로 포착할 수 있다.
2. 적응적인 HFF(hierarchical feature fusion) 블럭을 설계하였고 이는 공간 어텐션, 채널 어텐션, residual inverted MLP, 각 branch별로 다양한 스케일의 특징들간의 semantic 특징들을 적응적으로 융합할 수 있는 shortcut을 포함한다.
3. HiFuse 모델은 ISIC2018, Covid-19, Kvasir 데이터셋에 대해 상대적으로 좋은 결과를 달성하였다.
Related Works
첫 두 문단은 기존의 의료 영상 분류와 최근의 의료 영상 분류을 언급해주고 (맨날 똑같은 패턴임 딥러닝을 통해 성능을 개선하고 특징을 직접 설계하지 않아도 된다는 내용)
다음 두문단은 CNN과 트랜스포머 관련 연구들을 쭉 나열하는 거라 여기까지 pass (중요한 건 마지막 문단 6째줄부터)
이전의 모델들은 ImageNet과 같은 자연 데이터셋이나 다른 다양한 다운스트림 작업에 대해서는 잘 수행하지만 이를 의료 영역 도메인에 적용하면 만족스러운 결과를 얻을 수 없다.
의료 영상의 데이터가 충분하지 않기 때문에, 병리학적인 특징들이 일반적인 이미지의 특징들보다 더 흩어져 있어 포착하기 어렵다.
따라서, 본 연구진은 deep-shallow, global-local 특징들과, 이를 융합하기 위한 더 넓은 융합 네트워크를 최대한 활용할 수 있도록 하였다.
제안된 HiFuse 모델은 three-branch parallel fusion structure을 정의하고 로컬 전역 특징들을 결합하여 hierarchical feature fusion block(HFF block)을 설계하여 이 특징들을 융합하고 로컬과 전역 브랜치들이 서로 간섭하지 않도록 한다.
HiFuse는 CNN과 트랜스포머의 장점뿐만 아니라 각기 다른 규모로 결합된 로컬 특징과 전역 표현들을 이어받는다.
Proposed Method
<Overview>
새로운 의료 영상 분류 방법으로써 HiFuse 모델은 의료 영상 이미지의 로컬한 공간 정보와 전역 semantic 표현을 각기 다른 규모로 효과적으로 얻을 수 있도록 제안되었다.
병렬적인 구조를 사용하여 전역과 로컬 특징 블럭으로부터 의료영상의 전역과 로컬 정보를 추출하고 HFF block을 통해 다른 계층의 특징을 융합하며, 다운샘플링 과정을 거치고, 최종적으로 분류 결과를 획득한다.
먼저 HiFuse 모델의 전체적인 구조를 소개하고, 전역 특징 블럭과 로컬 특징 블럭을 각각 소개한다.
<The Multi-stage Design for HiFuse>
의료 영상의 분류 정확도를 향상시키기 위해선 계층 단계에서의 로컬 특징과 전역 표현을 융합하는 것이 중요하다.

그림 1은 HiFuse의 전체적인 구조를 보여준다.
로컬 브랜치로 이미지의 로컬한 특징들을 추출하고 전역 브랜치로 이미지의 전역 seantic 표현을 추출한다.
두 브랜치는 각기 다른 규모로 특징을 추출하는 4단계로 구성된다.
로컬 브랜치의 stem block은 stride=4인 $4\times 4$ 컨볼루션을 수행하며, 이후 Layer Norm을 적용한다.
전역 브랜치의 stem module은 패치 분할 모듈을 통해 이미지를 나눈다. 패치는 $4/times 4$의 인접한 픽셀이며 이는 channel direction을 통해 flatten된다.
패치 병합은 선형 임베딩을 통해 출력을 입력 채널의 2배로 확장하고 전역 특징 블럭을 통해 feature transformation.

표 1은 파라미터 세부사항이다.
3개의 브랜치가 병렬적 구조를 가진다는 것은 로컬 특징과 전역 특징이 서로를 간섭하지 않고 최대한 보존됨을 의미한다.
각기 다른 계층 레벨에서의 특징맵은 4단계를 통해 구성된다.
HFF 블럭은 각 단계의 로컬 특징과 전역 표현을 융합하는데 사용하고 이전단계에서의 출력과 연결한다.
공간 어텐션을 통한 각 계층의 로컬 특징 출력은 채널 어텐션을 통한 각 계층의 전역 특징과 결합된다.
최종적으로 결합된 특징은 분류를 위해 GAP, LN의 선형 분류기로 들어간다.
여러 HiFuse 변형들을 만들었는데, 각 변형모델 마다 각기 다른 수의 전역/로컬 특징 블럭을 가지고 있으며 다양한 크기의 데이터셋에 적용하기 위해 깊이를 달리하여 모델하였다.
Hifuse-Tiny/Small/Base
각 모델의 하이퍼파라미터는 다음과 같다.
- HiFuse-Tiny : 블럭 수 = (2,2,2,2)
- HiFuse-Small : 블럭 수 = (2,2,6,2)
- HiFuse-Base : 블럭 수 = (2,2,18,2)
<Global Feature Block>
의료 영상의 영상화 방법과 임상 병리학은 클래스 내의 상당한 변화와 클래스 내의 높은 유사도을 가지며 다양하다.
전역적인 semantic 정보를 얻는 것이 중요하다.
따라서, 전역 특징 추출 브랜치에 Windows Multi-head Self-Attention(W-MSA)을 도입하였다.
W-MSA는 Swin-Transfomer에서 처음으로 소개되었으며, Transfomer 내의 Multi-head Self-Attention(MSA) 모듈과 비교하면 연산량을 효율적으로 줄이고 특징 맵을 $M\times M$ 크기로 분할한다.
하나씩 window를 적용한 다음 각 window에 대해 개별적으로 self-attention을 수행한다.
연산복잡도는 식 1과 같다.

$h$ : 특징 맵의 height
$w$ : 특징 맵의 width
$C$ : 특징 맵의 depth
$M$ : 각 윈도우 크기
그림 1을 보면 각 단계에서 패치를 글로벌 특징 블럭에 통합하여, 특징 맵이 LayerNorm을 거쳐 W-MSA으로 들어가, GELU 활성화 함수를 가진 선형 레이어를 통과한다.
각 모듈 이후에 residual connection을 적용하는데, relative position bias(rel. pos.)을 사용하고, 다음 모듈에서 Shift W-MSA를 도입한다.
이 과정이 식 2에서 정리된다.

$G_i, g_i$는 각각 전역 특징 블럭의 Shift W-MSA, W-MSA 출력 특징
$f^{1\times 1}$ : $1\times 1$ 커널 크기의 컨볼루션 연산이며 이는 선형 연산과 같다.
$LN$ : LayerNorm 연산
최종적으로, 추출된 전역 특징이 HFF 블럭의 입력으로 들어간다.
<Local Feature Block>
의료영상에서 로컬한 공간 특징은 매우 중요하다
그림 1에서, 로컬 특징 블럭은 $3\times 3$ depthwise convolution을 사용하였다.
grouped convolution의 특수 케이스
그룹의 수 = 채널의 수
depthwise convolution을 사용하면 네트워크의 FLOPs 수를 효과적으로 줄일 수 있다.
이후, 선형 레이어를 통해 채널 간 정보를 주고 받게 되는데 (cross-channel information interaction), 트랜스포머의 LN과 GELU활성화를 사용하면서 여러 응용 시나리오에서 좋은 성능을 얻을 수 있었다.
최종적으로, 추출된 로컬 특징은 HFF 블럭의 입력으로 들어간다.
이 과정이 식 3에서 정리된다.

$L_i$ : 로컬 특징 블럭의 출력 특징
$f^{d3\times 3}$ : $3\times 3$ 커널 크기의 depthwise convolution 연산
전체적으로 봤을 때 로컬과 글로벌 브랜치는 유사하며, 동일한 채널 수와 계층 구조는 로컬과 전역 인코딩 특징을 각기 다른 스케일로 융합하는 기초가 된다.
각 브랜치의 각기 다른 스케일의 특징들을 어떻게 효과적으로 융합하는지는 새로운 문제이다.
이를 위해, HFF 블럭을 제안하였다.
<HFF Block>

그림 2를 보면 적응적인 계층적 특징 융합 블럭(adaptive hierarchical feature fusion block)은 입력 특징에 따라, 각 층에서의 로컬 특징, 전역 표현, 이전 계층에서 융합된 semantic information을 적응적으로 융합한다.
$G_i$ : 전역 특징 블럭의 특징 행렬 출력값
$L_i$ : 로컬 특징 블럭의 특징 행렬 출력값
$F_{i-1}$ : HFF의 이전 단계에서의 특징 행렬 출력값
$F_i$ : 현재 단계에서의 융합으로 생성된 특징 행렬값
전역 특징 블럭의 셀프 어텐션이 시공간적인 전역 정보를 어느정도 포착할 수 있기 때문에, HFF 블럭은 들어오는 전역 특징을 채널 어텐션(CA) 구조의 입력으로 제공한다.
채널 맵 간의 상호의존성을 이용하여 특정 의미의 특징 표현을 향상시킨다.
로컬 특징은 공간 어텐션(SA) 구조의 입력으로 들어가서 local detail을 강화하고 관련없는 영역을 억제한다.
최종적으로 각 어텐션과 fusion path를 통해 생성된 결과가 특징 융합이 되고 residual inverted MLP(IRMLP)가 연결된다.
기울기 소멸, 발산(explosion), network degradation 문제가 어느정도 예방되어 각 계층에서 로컬과 전역 특징정보를 효과적으로 포착할 수 있다.
Degradation
네트워크의 깊이가 깊어질수록 성능이 저하되는 (정확도가 떨어지는) 문제
학습이 진행되지 않는다.

그림 3은 ResNet, Swin Transformer, ConvneXt, HFF 블럭의 구조를 비교한다.
HFF block에서 표기가 잘못된 게 있는 것 같음
입력으로 들어오는 로컬/전역 특징과, 이들이 공간어텐션/채널어텐션을 거친후의 출력이 element-wise multiply되는데 이 연산이 빠져있음
이 과정은 식4로 정리된다.
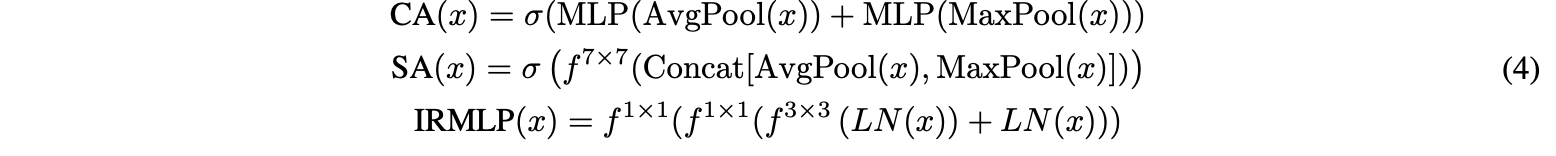
$\sigma$ : 시그모이드 함수
$f^{7\times 7}$ : $7\times 7$ 커널 크기의 컨볼루션 연산
특징 융합 연산은 식 5를 따라 진행된다.

$\otimes$ : element-wise multiply
$\hat{G_i}$ : 채널 어텐션 결합으로 생성된 결과
$\hat{L_i}$ : 공간 어텐션 결합으로 생성된 결과
$\tilde{F_i}$ : HFF 블럭의 이전 단계 결과를 다운샘플링 한 결과
$\hat{F_i}$ : 전역/로컬 특징과 이전 단계의 융합값의 결과
$F_i$ : $\hat{F_i}, \hat{G_i},\hat{L_i} $가 concatenate된 후 IRMLP를 거쳐 생성
Experiments
<Dataset>
ISIC2018, COVID-19, Kvasir
<Performance Metrics>

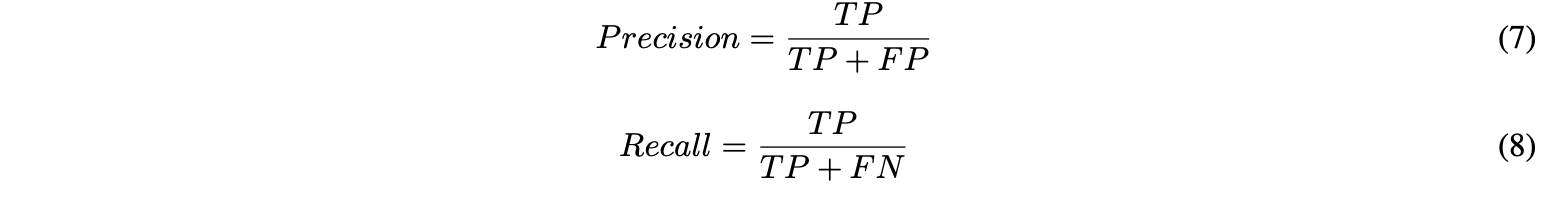

<Implementation Details>
앞은 skip
초기 학습률 : $1e-4$
배치 크기 : 32
훈련 에폭 : 100
코사인 어닐링 적용
실험의 공정성을 위해, 이미지 크기는 $224\times 224$로 조정, 동일한 operating environment와 하이퍼파라미터를 공유하며, 이전 논문에서 사용된 훈련/검증/테스트 셋을 사용한다.
mmcv 프레임워크 하에서 실험을 수행하였다.
출력레이어로 소프트맥스를 사용하고 손실값을 구하기 위해 categorical cross-entropy 손실함수를 사용

$N$ : 총 샘플 수
$K$ : 카테고리(클래스) 수
$y^t_i$ : 타겟 라벨
$y^p_i$ : 모델에서 출력된 예측값

표 2에서 자세한 파라미터 세팅을 확인할 수 있다.
<Ablation Study>
skip
<Visual Inspection of HiFuse>
HiFuse-T와의 비교를 위해 ConNeX-T, Swin Transformer-T 선택
선형 레이어를 제외한 최종 레이어를 시각화하기 위해 Grad-CAM 적용하여 히트맵 형식으로 모델의 관심 영역을 표현

그림 4의 (a)와 (b)는 dermoscopy(소엽 모세혈관 모세혈관종), upper gastrointestinal endoscopy(상부 위장관 내시경)의 시각화 결과를 보여준다.
<Results on ISIC2018 Dataset>
<Results on Covid19 Dataset>
<Results on Kvasir Dataset>
skip
<Discussion>
자연영상에 비해, 의료 영상은 특성이 다양하고, 데이터가 적으며, 다른 의료 장비를 사용하기 때문에 훈련 데이터가 제한적이고 모델이 분류 특징에 집중할 수 없다.
자연 영상 분류 작업에서 잘 수행된 모델을 의료 영상 분야에 적용하면 만족스러운 결과를 얻을 수 없다.
따라서, 의료 영상에 효율적이고 강인한 백본 네트워크를 찾는 것은 힘든 과제였다.
컨볼루션 연산과 달리, 트랜스포머의 셀프 어텐션은 전역 수용장을 가지고 있어 픽셀간의 장기 의존성을 마이닝할 수 있으며 좋은 일반화 능력을 가진다.
많은 실험을 통해 로컬한 공간 특징 또한 의료 영상 처리에서 중요함을 보였다.
이를 기반으로, three branch 구조의 계층적 특징 융합 모델인 HiFuse를 제안하여 HFF 블럭을 통해 각기 다른 규모에서의 전역/로컬 특징 표현을 융합한다.
ISIC2018, Covid-19, Kvasir 의료영상 데이터셋을 사용하여 비교 실험을 진행하였고 HiFuse가 가장 좋은 결과를 보임을 증명하였다.
게다가, HiFuse는 풍부한 확장성, 선형 연산 복잡도, 더 광범위한 응용을 가진 계층적 구조의 이점이 있다.
모델이 의료 영상 분류에 초점을 두었지만, 본 논문에서 제기된 아이디어는 전역 특징과 로컬 특징을 융합하는 새로운 방법을 제공한다.
본 아키텍쳐에서 계층적 융합 방법은 더 쉽게 확장될 수 있고 개선될 수 있다.
본 모델은 후속 연구에서 다음과 같이 개선
- 작업의 구체적인 상황에 따라, 네트워크의 깊이와 폭을 branch마다 다르게 할당하여 로컬 특징과 전역 표현이 더 직접적이도록 한다.
- HiFuse의 성능을 더 개선하기 위해 다양한 데이터셋에 대한 dynamic hierarchical feature selection 설계
- HiFuse를 의료 영상 분할과 멀티모달에 적용할 수 있도록 연구
Conclusion
본 논문에선 three-branch 구조의 계층적 융합 분류 모델을 HiFuse을 제안하였고, 모듈형 설계를 통해 풍부한 확장성과 선형 연산 복잡도를 가진다.
HiFuse에서 로컬 특징 블럭은 로컬한 특징을 추출하고, 전역 특징 블럭은 전역 표현을 포착하며, 계층적 특징 융합(HFF) 블럭은 로컬 특징과 전역 표현을 각기 다른 규모에서 융합하여, 의료 영상의 병변 영역의 deep-shallow, global-local 특징을 완전히 마이닝한다.
실험을 통해 제안된 방법이 3개의 의료영상 데이터셋에 대해 좋은 결과를 보임을 밝혔다.