[논문 정리] MetaFormer : A Unified Meta Framework for Fine-Grained Recognition
논문정보
MetaFormer : A Unified Meta Framework for Fine-Grained Recognition
MetaFormer: A Unified Meta Framework for Fine-Grained Recognition
Fine-Grained Visual Classification(FGVC) is the task that requires recognizing the objects belonging to multiple subordinate categories of a super-category. Recent state-of-the-art methods usually design sophisticated learning pipelines to tackle this task
arxiv.org
<Code>
GitHub - dqshuai/MetaFormer: A PyTorch implementation of "MetaFormer: A Unified Meta Framework for Fine-Grained Recognition". A
A PyTorch implementation of "MetaFormer: A Unified Meta Framework for Fine-Grained Recognition". A reference PyTorch implementation of “CoAtNet: Marrying Convolution and Attention for All...
github.com
논문정리
Abstract
FGVC(Fine-Grained Visual Classification)은 상위 카테고리에 속하는 여러 하위 카테고리에 속하는 객체를 인식하는 것
최근 연구들은 이를 다루기 위해 정교한 파이프라인을 설계했는데 이미지 정보만으로는 정확하게 fine-grained 카테고리를 구별하기에 부족하다.
요즘엔 메타정보 (spatio-temporal prior, attribute, text description)가 이미지와 함께 등장한다
이에 따라, 다음의 질문을 제기한다.
fine-grained 인식을 위해 다양한 메타 정보를 활용하는 단순하고 통합된 프레임워크를 사용할 수 있을까?
이에 대한 답을 찾기 위해, fine-grained 분류를 위한 통합되고 강력한 메타-프레임워크 (MetaFormer)을 탐구한다.
실제로 MetaFormer는 이미지와 다양한 메타정보를 동시에 학습하기 위한 간단하지만 효율적인 접근방식을 제공한다
또한 다른 부가기능 없이 FGVC를 위한 강력한 베이스라인을 제공한다
다양한 실험을 통해 MetaFormer가 fine-grained 인식 성능을 높이기 위해 다양한 메타정보를 효율적으로 사용하고 있음을 보였다.
공정한 비교를 통해 MetaFormer가 이미지 정보만을 사용해서 기존의 SOTA 접근법을 능가하였다.
iNaturalist2017, iNatualist2018 데이터셋 사용
메타 정보를 추가하면, MetaFormer는 기존의 SOTA 접근법을 각각 5.9%, 5.3%정도 능가한다
게다가, CUB-200-2011, NABirds 데이터셋에선 각각 92.3%, 92.7%의 정확도를 달성하였다.
Introduction
일반적인 객체 분류와는 달리, fine-grained 이미지 분류는 같은 기본 범주(birds, cars, etc)에 속하는 객체를 하위 카테고리로 분류한다.
FGVC는 클래스 간 분산은 작고 클래스 내 분산은 크기 때문에 어려운 과제였다.
본 연구진이 아는 바로는, 기존의 우세한 접근방법들은 주로 네트워크가 가장 차별성있는 영역에 초점을 두는 것을 목표로 하였다.
e.g., part-based model, attention-based model
이런 접근법은 인간의 관찰 행동에서 비롯하여, 정교한 구조를 갖는 신경망에 localiztion의 inductive bias를 도입한다
Inductive bias란 모델이 처음보는 입력에 대한 출력을 예측하기 위해 사용하는 가정
특정 물체들이 시각적으로 구별되지않을 때, 인간은 시각적 정보 외의 것들을 활용한다.
fine-grained 인식을 위한 데이터는 정보 홍수 시대에 생긴 다양한 소스의 이질적인 정보 이기 때문에, 신경망이 시각적 정보만을 활용해서 fine-grained 인식을 완벽하게 수행하기에는 무리가 있다.
실제로, fine-grained 인식은 시각적으로 구별하기는 힘들기 때문에 course-grained에서보다 orthogonal signal의 도움을 더욱 필요로 한다.
이전의 연구는 spatio-temporal prior and text description과 같은 추가 정보들을 활용하여 fine-grained 분류를 보강했다.
하지만 이런 추가정보들을 위한 설계는 특정 정보만을 타겟으로 하기 때문에 보편적이라고 할 순 없다.
따라서 다양한 메타 정보들을 유연하게 활용하기 위해 통합된, 그리고 효율적인 방법들을 설계하였다.
Vision Transformer(ViT)는 순수 트랜스포머를 이미지 패치 시퀀스에 직접적으로 적용하여서 이미지 분류 작업에서 좋은 성능을 낼 수 있음을 보였다.
FGVC에서 트랜스포머의 입력으로 이미지 토큰과 메타 토큰을 동시에 취하는 것이 가능하다
하지만 다른 양상의 정보들이 서로 간섭하게 될 때 모델의 성능이 떨어지게 될지는 불분명하다
따라서, MetaFormer를 제안하여 트랜스포머를 사용하여 이미지와 메타 정보를 융합한다.

그림 1에서 볼 수 있듯, MetaFormer는 메타 정보의 도움으로 FGVC에서의 정확도를 향상시킬 수 있다.
실제로 MetaFormer는 하이브리드 구조로 볼 수 있다.
- 컨볼루션은 이미지를 다운샘플링 하고 inductive bias를 유도함
- 트랜스포머는 이미지와 메타 정보를 융합함
이런 방식으로, MetaFormer가 다른 부가기능 없이 FGVC를 위한 강력한 베이스라인을 제공할 수 있다.
이미지 분류의 발전을 통해 대규모의 사전학습이 course-grained 분류와 fine-grained 분류의 정확성을 높일 수 있음을 보였다.
하지만, 현재 FGVC를 위한 방법은 대부분 ImageNet-1K를 사전학습에 사용하는데, 이는 fine-grained를 위해 추가적으로 탐구하는 데 방해가 된다.
MetaFormer의 단순성 덕에, 사전 학습된 모델의 영향을 자세하게 탐구해보고, 사전훈련 모델에 대한 참고자료를 제공할 수 있게 되었다.
그림 1에서 보다싶이, 대규모의 사전학습 모델이 fine-grained 인식의 정확도를 상당히 개선하였다.
MetaFormer는 fine-grained 작업을 위한 어떤 사전작업 없이도 대규모의 사전학습 모델을 이용항 다양한 데이터셋에서 SOTA 성능을 보였다.
Key Contribution
1. FGVC를 위한 통합되고 매우 효율적인 메타 프레임워크를 제안하여 시각적 정보와 다양한 메타 정보를 통합하였다.
2. 전역 특징만을 이용하여 FGVC를 위한 강력한 베이스라인을 제공한다. 더불어, fine-grained 분류를 위한 사전학습 모델의 영향에 대해서도 탐구하였다.
3. fine-grained 분류 작업을 위한 inductive bias 없이도, MetaFormer는 CUB-200-2011, NABirds에서 92.3%, 92.7%의 정확도를 달성 하였고 이는 SOTA 성능을 능가한다. 시각적 정보만을 사용하여 MetaFormer는 iNaturalist 2017, iNatuarlist 2018에 대해서 SOTA 성능을 보였다.
Related Work
Fine-grained 분류를 위한 기존 연구는 이미지만을 이용하는 것과 multi-modality로 나눌 수 있다.
전자는 이미지 정보만을 이용하여 fine-grained 분류를 수행하고, 후자는 multi-modality 정보를 통합하기 위한 공동 표현(joint representation)을 구축하기 위해 multi-modality 데이터를 취해 fine-grained 인식을 용이하게 한다.
<Fine-Grained Visual classification>
Vision Only
이미지 정보에만 의존하는 fine-grained 방법은 둘로 나눌 수 있다.
localization method, feature-encoding method
초기 연구는 부분 어노테이션을 정답(supervision)으로 사용하여 네트워트가 종간의 미묘한 차이점에 주의를 기울이도록 하는데, 어노테이션 작업에는 비용이 많이 든다.
Data annotation
데이터셋에 메타 데이터를 추가하는 작업
원본 데이터를 설명하기 위해 오브젝트(바운딩박스, 폴리라인, ...)나 이미지 카테고리와 같은 메타 데이터를 태그 형식으로 데이터셋에 추가
https://cordingdiary.tistory.com/86
RA-CNN은 미세한 영역을 확대하기 위해 제안되었는데, 차별성있는 영역 어텐션과 다양한 크기의 영역기반 특징표현을 mutually reinforced 방법으로 재귀적으로 학습한다.
MA-CNN은 다중 어텐션 모델을 설계하여 part generation과 특징 학습이 서로를 강화하도록 한다.
NTSNet은 자기지도(self-supervision) 구조를 설계하여 부분 주석 없이도 효과적으로 유익한 영역을 찾아낼 수 있다.
Feature encoding 방법은 특징표현을 풍부하게 해서 fine-grained 분류의 성능을 향상시키는 것을 목표로 한다.
Bilinear CNN은 고차(higher order)특징을 추출하기 위해 제안되었으며, 두개의 특징맵이 외적으로 곱해진다.
HBP는 계층 구조를 설계하여 층간 bilinear pooling을 진행한다.
DBTNet은 심층 bilinear transformation을 제안하여 semantic information의 장점을 취하고 bilinear 특징을 효과적으로 얻는다.
CAP는 context-aware attentional pooling을 설계하여 이미지 간의 미묘한 차이를 포착한다.
TransFG는 Part Selection Module을 제안하여 ViT를 적용해 차별성 있는 이미지 패치를 선택한다.
localization 방법과는 다르게 feature-encoding 방법은 두 종간의 차별성있는 영역을 명시적으로 보이기 어렵다.
Multi Modality
이미지 카테고리 간 구별하기 위해 추가 정보를 이용하는 것이 도움이 된다.
geolocation, attributes, text description
Geo-Aware은 fine-grained 분류에 geographic information prior를 도입하고,이 지리적 정보를 사용하여 후처리, 화이트리스팅(whitelisting), 특징 조정 (feature modulation)을 포함한 다양한 방법을 검증하였다.
Presence-Only는 네트워크에 spatio-temporal prior을 도입하고 최종 분류 성능을 높일 수 있음을 증명하였다.
KERL은 풍부한 추가정보와 심층 네트워크 구조를 결합하여 지식그래프 형태로 풍부한 시각적 개념(visual concept)을 구성하였다.
CVL은 two branch network를 제안하여 하나의 브랜치는 시각적 특징을 학습하고, 다른 하나는 텍스트 특징을 학습하도록 하였다ㅏ. 이후 이 두 부분을 합쳐서 최종적인 잠재 semantic 특징을 얻는다.
위에 언급된 방법은 모두 특정 사전 정보를 위해 개발되었으며 다른 추가 정보에는 유연하게 적용할 수 없다.
<Vision Transformer>
트랜스포머는 처음에 기계번역을 위해 제안되었으며 현재는 자연어처리 분야에서 일반적인 방법이 되었다.
트랜스포머 모델은 이후에 객체탐지, 분할, 객체추적, 비디오 의미분할 등의 인기있는 컴퓨터비전 작업으로 확장되었다.
최근에는 Vision Transformer(ViT)가 순수 트랜스포머를 직접적으로 활용하여 이미지 패치를 분류하는데 사용되었고, 엄청난 성능을 보였다.
CNN과 달리 ViT는 이미지에 특화된 inductive bias가 부족하기 때문에 성능이 잘 나오기 위해서는 대용량의 훈련 데이터와 강력한 데이터 증강과 정규화 방법들을 필요로 한다.
ViT 이후, 몇몇 연구들은 inducvie bias(i.e., convolutional inducvie biases)와 locality를 ViT에 도입하도록 시도하였다.
Method
<Hybrid Framework>
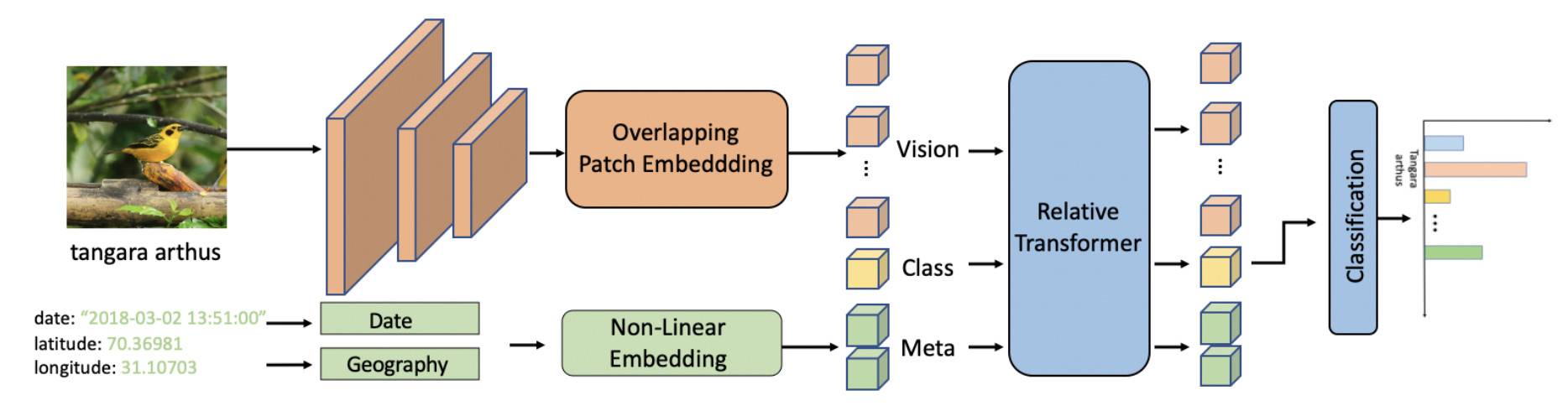
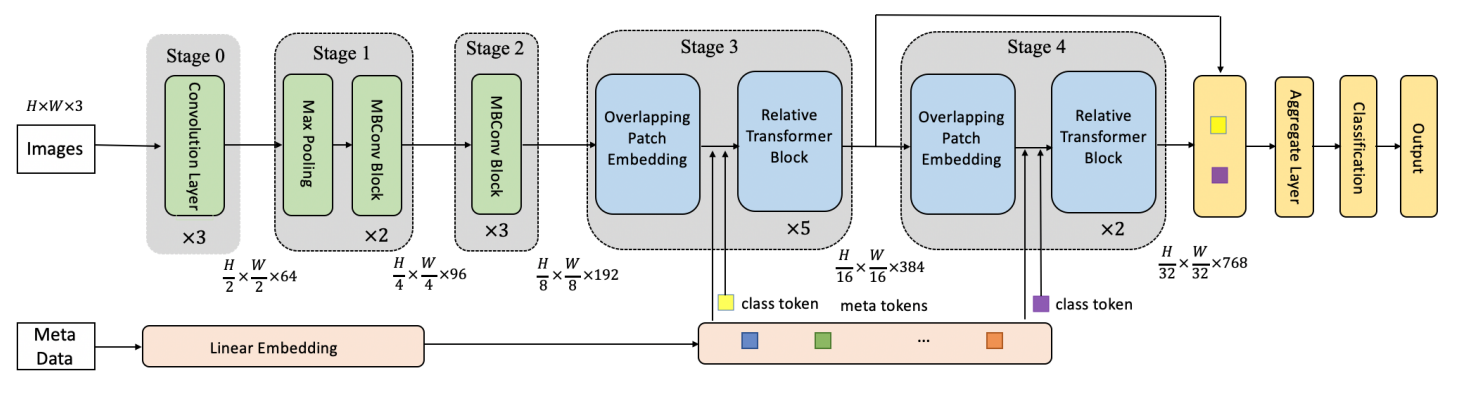
MetaFormer의 전반적 프레임워크는 그림 2에서 확인할 수 있다.
MetaFormer는 컨볼루션은 시각적 특징을 인코딩하고, 트랜스포머 층은 시각정보와 메타정보를 융합하는 하이브리드 프레임워크이다.
기존의 ConvNet을 따라 네트워크를 5단계로 구성하였다
S0, S1, S2, S3, S4
각 단계가 시작하기 전에, 다른 크기의 레이아웃을 실현하기 위해 입력 크기가 줄어든다.
첫번째 단계인 S0는 단순히 3계층의 컨볼루션이다.
S1, S2는 Squeeze-exitation이 있는 MBConv 블럭이다.
S3, S4에서는 relative position bias가 있는 트랜스포머 블럭을 사용하였다.
S0에서 시작해서 S4까지 입력 크기는 2배 줄어들고 채널 수는 증가시킨다.
s3와 s4의 다운샘플링은 Overlapping Patch Embedding이라고 알려진 stride가 2인 컨볼루션을 진행한다.
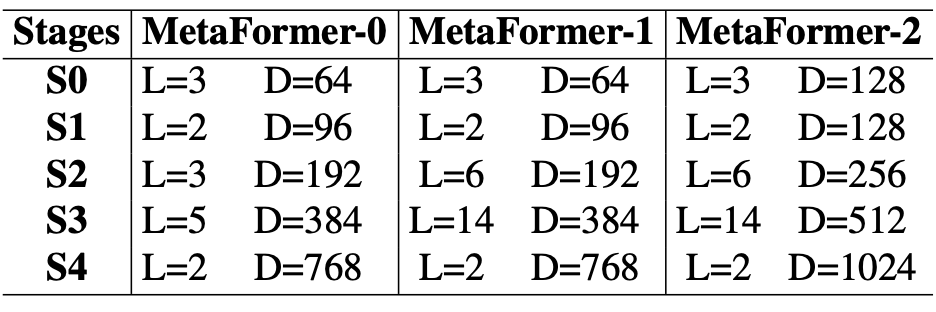
일련의 MetaFormer 정보는 표 1에서 확인할 수 있다.
Relative Transformer Layer
트랜스포머의 셀프 어텐션 연산은 permutation-invariant하기 때문에 입력 시퀀스의 토큰 순서에 대한 영향이 없다.
permutation-invariant
순서가 바뀌어도 output이 변하지 않는 특성
이 문제를 완화하기 위해, 각 위치에 상대적 위치 편향(relative position bias) $B \in \mathbb{R}^{(M^2+N)\times(M^2+N)}$을 도입하여 아래와 같이 유사도를 계산한다
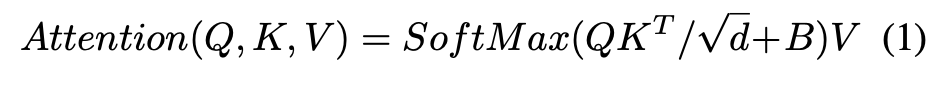
기존 어텐션 연산에서는 없었던 편향 B가 추가되었음
$Q,K,V\in \mathbb{R}^{(M^2+N)\times d}는 각각 query, key, value 행렬이다.
$M^2$ : 이미지 패치 수
$N$ : 클래스 토큰이나 메타 토큰 같은 추가적인 토큰의 수
$d$ : query, key 차원
이미지 블럭의 상대적 위치가 $-M-1$부터 $M+1$까지 있고, 추가 토큰과 이미지 토큰의 상대적 위치를 표시하기 위해 special relative position bias가 필요하기 때문에 행렬 $\hat{b} \in \mathbb{R}^{(2M-1)\times (2M-1)+1}$를 매개변수화 하였다.
각 추가 토큰과 다른 토큰간에는 공간 위치 관계가 존재하지 않기 때문에, 모든 추가 토큰은 같은 상대적 위치 편향을 가진다.
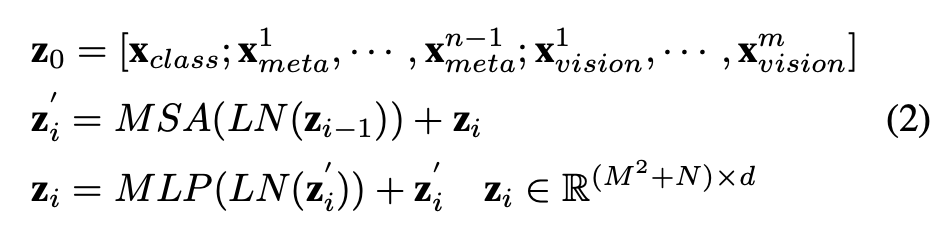
상대적 트랜스포머 블럭(식 2)은 상대적 위치 편향이 있는 멀티헤드 셀프 어텐션(MSA)과, 다층 퍼셉트론 (MLP), 레이어정규화(LN)를 포함한다
식 2의 $\mathbf{z}_0$은 토큰 시퀀스를 나타내는데, 분류 토큰($\mathbf{x}_{class}$), 메타 토큰($\mathbf{x}^i_{meta}$), 이미지 토큰($\mathbf{x}^i_{vision}$)을 포함한다.
Aggregate Layer
S3, S4은 최종적으로 두 개의 클래스 토큰 $\mathbf{z}^1_{class}, \mathbf{z}^2_{class}$을 각각 출력하고 이는 이미지 특징과 메타 정보의 융합을 표현한다.
$\mathbf{z}^1_{class}, \mathbf{z}^2_{class}$의 차원이 다르기 때문에 $\mathbf{z}^1_{class}$을 MLP를 통해 확장한다.
이후, $\mathbf{z}^1_{class}, \mathbf{z}^2_{class}$는 아래의 Aggregate Layer를 통해 합쳐진다
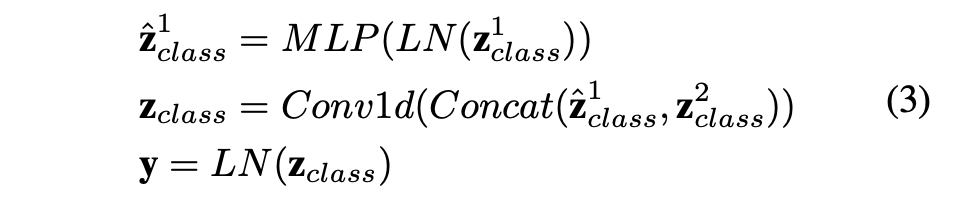
$\mathbf{y}$ : 다양한 크기의 이미지와 메타 정보를 포함하는 출력값
Overlapping Patch Embedding
overlapping patch embedding을 사용하여 특징맵을 토큰화하고 연산량을 줄이기위해 다운샘플링한다.
제로 패딩 컨볼루션을 사용하여 overlapping patch embedding을 구현한다.
<Meta Information>
fine-grained 종을 정확히 구별하기 위해 외적 정보만을 사용하는 것은 충분하지 않다.
이미지가 주어지면 인간은 최종 결정에 도움이 되는 추가 정보를 모두 활용한다
최근 ViT의 발전은 컴퓨터 비전에서 이미지를 시퀀스로 인코딩하는 것이 가능해졌음을 보여준다
이는 트랜스포머 층을 사용하여 메타 정보를 추가하는 단순하고 효율적인 방법을 제공한다
종의 분포가 지리적으로 군집화되는 추세를 보여주고, 각기 다른 종들의 생활 습관이 다르기 대문에 시공간 정보가 fine-grained 종을 분류하는 데에 도움이 될 수 있다.
얘는 뭔가 새, 개 품종 같은 생물학적 종을 분류하는 얘기인 듯
위도와 경도를 조건으로, 전지구를 표현할 수 있는 지리적 좌표를 원한다
이를 위해 지리적 좌표계를 직사각형의 좌표계로 변환한다
$[lat, lon] \rightarrow [x,y,z]$
비슷한 방법으로, 12월과 1월의 거리는 10월과의 거리보다 가깝다
23:00은 00:00과 비슷한 임베딩 결과를 보일 것이다 (가까워서?)
$[month, hour] \rightarrow [sin(\frac{2\pi month}{12}) , cos(\frac{2\pi month}{12}), sin(\frac{2\pi hour}{24}) , cos(\frac{2\pi hour}{24})]$
메타 정보를 속성으로 사용하여 이 속성을 벡터로 초기화한다.
예시로, CUB-200-2011 데이터셋에는 312개의 속성이 있는데, 이를 위해 312차원의 벡터를 생성
텍스트 형태의 메타 정보는 BERT를 사용하여 각 단어의 임베딩을 얻는다.
각 이미지가 여러 문장으로 구성된 메타 정보를 가진다면, 각 훈련에서마다 하나의 문장을 임의로 선택하고, 각 문장의 최대 길이를 32로 설정
그림 2에서 볼 수 있듯, 비선형 임베딩$(f : R^n \rightarrow R^d)$은 여러 층의 FC 신경망이며 이는 메타 정보를 임베딩 벡터로 매핑한다
이미지 정보와 메타 정보는 semantic level이 다르기 때문에 추가적인 정보보다 시각적인 정보를 학습하기가 더 어렵다
네트워크에 대용량의 추가 정보가 초기단계에 주어지면 네트워크의 시각적 능력이 손상될 것.
따라서, 훈련이 진행되는 동안 선형적으로 비율을 줄이면서 메타 정보를 마스킹한다.
Experiments
Datasets
ImageNet 데이터셋에 대해 이미지 분류 실험을 수행하고 fine-grained 분류를 위한 사전훈련 모델 제공.
iNaturalist 2017, iNaturalist 2018, iNaturalist 2021의 메타 정보를 추가함으로써 본 논문에서 제시된 프레임워크의 효율성을 입증하였다.
또한 fine-grained 벤치마크로써 자주 쓰이는 Standford Cars, Aircraft, NABirds에 대해서도 제안된 프레임워크를 평가하였다.
바운딩박스나 부분주석 (part annotation)을 일체 사용하지 않았다.
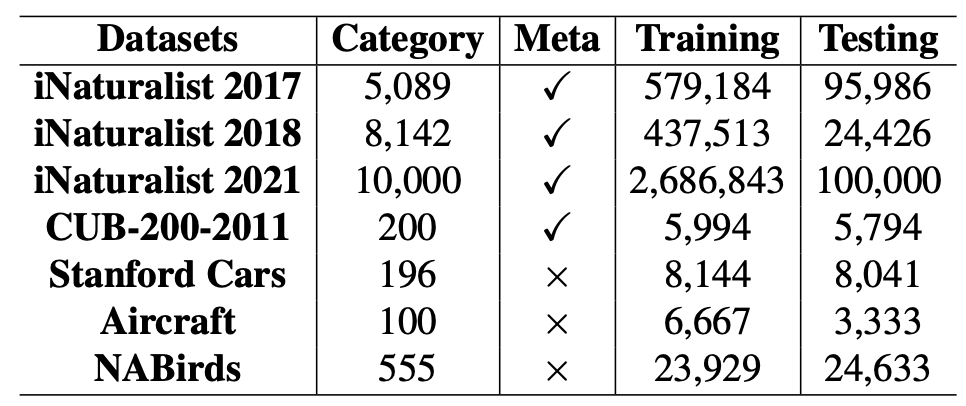
표2에서 fine-grained 벤치마크 정보를 확인할 수 있다.
Implementation details
먼저, 입력 이미지를 384*384로 조절한다
cosine decay learning rate scheduler를 적용한 AdamW 옵티마이저를 사용
초기 학습률은 $5e^{-5}$으로 설정하되, Standford Cars에 대해서는 $5e^{-3}$, Aircraft에는 $5e^{-4}$
가중치 감쇄(weight decay)는 0.05
참고문헌 [26] (swin transformer)에 사용된 증강과 regularization 전략을 대부분 포함한다
300 에폭 동안 모델을 파인튜닝하고, 5에폭 간 warm-up을 수행한다
MetaFormer-0, MetaFormer-1, MetaFormer-2에 대해 최대 0.1, 0.2, 0.3 비율까지 stochastic depth augmentation 정도가 증가한다
<Comparison with CoAtNet on ImageNet-1K>
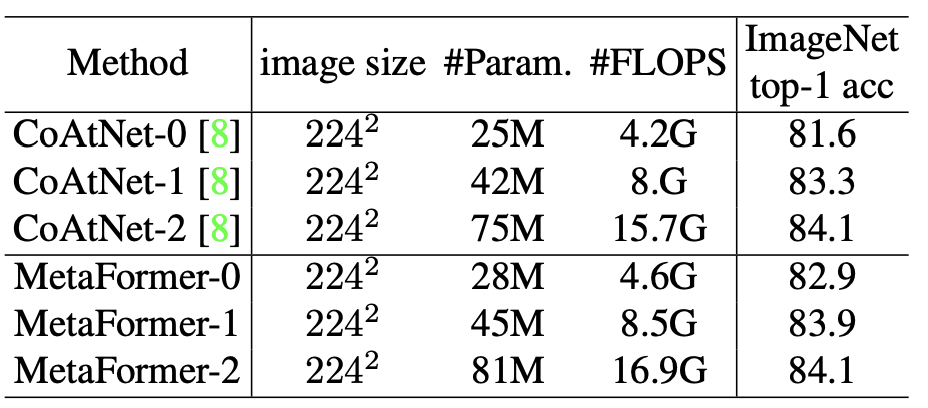
표 3에서는 ImageNet-1k에 대한 정확도를 보여준다.
본 네트워크 구조가 CoAtNet을 능가한다.
이 구조를 구현할 때, CoAtNet이 기반이 되었다.
MetaFormer와 CoAtNet의 차이점
- MetaFormer는 최종 출력을 얻기 위해 ViT에서 클래스 토큰을 유지한다
- CoAtNet에서는 풀링을 사용한다
- 특히, 본 네트워크에서는 Aggregate Layer를 설계하여 각기 다른 단계에서 얻어지는 클래스 토큰을 통합한다
일반적인 ImageNet-1k 훈련 시, MetaFormer가 CoAtNet의 성능을 능가하였다
- MetaFormer-0이 CoAtNet-0보다 +2.3%
- MetaFormer-1이 CoAtNet-1보다 +0.6%
<The Power of Meta Information>
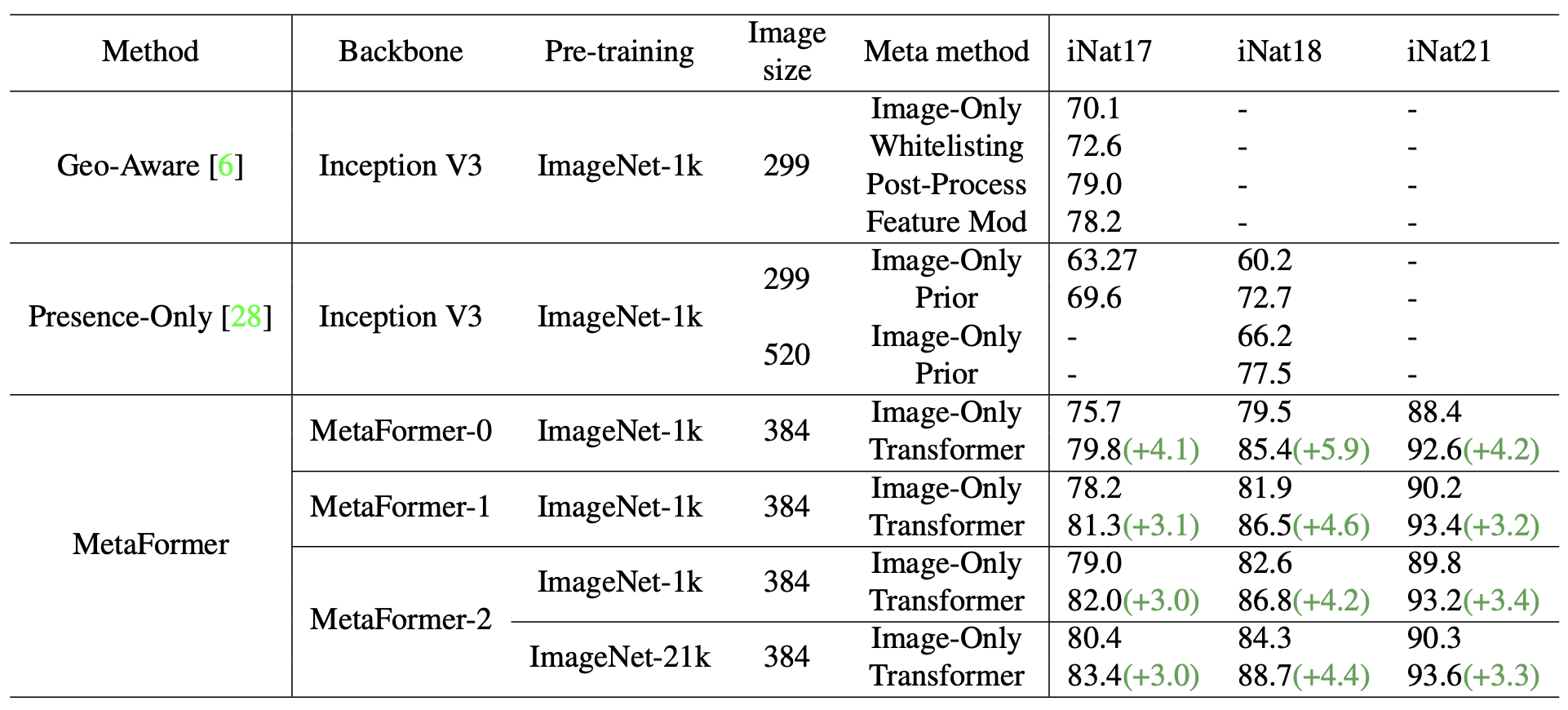
표 4는 spatio-temporal prior를 가진 iNaturalist 시리즈에 대한 실험 결과이다.
Geo-Aware는 지리학 정보를 통합하는 여러 방식을 체계적으로 검사한다.
whitelisting, post-processing, feature modulation
Presence-Only는 시공간(spatio-temporal) 정보를 prior로 사용하여 fine-grained 인식의 성능을 향상시켰다.
네트워크 구조의 한계로, geographical prior에 대한 이전의 실험은 poor baseline에 의해서 수행되었다.
본 논문에선 spatio-temporal 정보를 가진 강력한 베이스라인을 제공한다.게다가, 별도의 헤드가 없이도 추가 정보를 활용하기 위해 백본으로써 트랜스포머 층을 활용하였다.입력 크기와 모델 사이즈가 각기 다른 경우에는 spatio-temporal 정보를 추가하면 보통 3~6%의 개선을 보인다.
대용량 모델이 사용되면, 시각 능력이 개선된다.
MetaFormer-0에 비해 MetaFormer-2는 iNaturalist 2017에 대해 75.7%에서 79.0%의 정확도를 달성하였다.
(ImageNet-1k로 사전훈련)
강력한 사전훈련 모델은 성능 개선을 불러온다
MetaFormer-2의 경우, iNaturalist2017에 대해 ImageNet-21K로 사전훈련 하면 79.0%에서 80.4%로 증가한다
대용량 모델과 강한 사전학습을 사용하게 되면, 메타 정보로부터 얻은 이득이 줄어들지 않으면서 시각적 능력이 개선됨을 확인하였다.
이는 테스트셋의 샘플 일부가 메타 정보의 도움을 받아서 효과적으로 식별될 수 있음을 보여준다
게다가, MetaFormer는 iNaturalist 2017, iNaturalist 2018, iNaturalist 2021에 대해 각각 83.4%, 88.7%, 93.6%의 정확도를 달성하였다.
본 모델이 다양한 형태의 추가 정보를 적용할 수 있다는 것을 증명하기 위해 텍스트설명과 속성이 있는 CUB-200-2011 데이터셋에 대해 실험을 수행하였다.
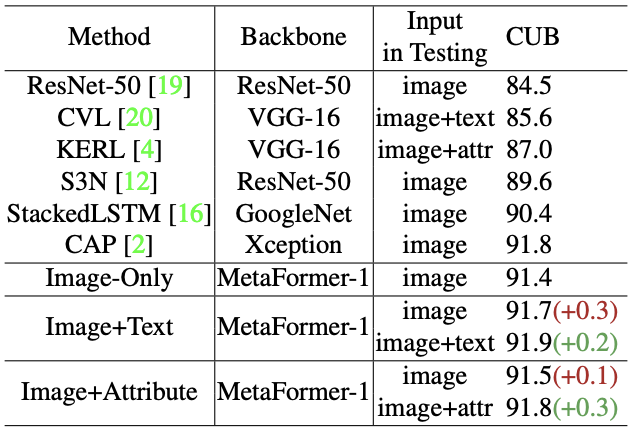
표5는 테스트할 때 이미지와 텍스트 설명을 입력으로 넣었을 때 정확도가 91.7%에서 91.9%로 상승했음을 보여준다.
속성(attribute)을 메타 정보로 사용했을 때도 결과는 비슷하다.
메타 정보의 타당성을 입증하기 위해, MetaFormer-1의 파라미터를 ImageNet-21를 사전훈련한 모델로 초기화하였다.
강력한 베이스라인의 경우, 메타 정보가 여전히 도움이 되며 본 방법이 메타 정보를 활용하여 fine-grained 인식을 수행함을 보여준다.
훈련 시 이미지를 입력으로 사용하였을 때, MetaFormer-1은 CUB-200-2011에 대해 91.4%의 정확도를 보였다.
같은 훈련 환경에서 이미지와 텍스트 설명을 훈련시 입력으로 사용하고, 이미지만을 테스트의 입력으로 넣었을 때 정확도는 91.7%을 보였다. 이는 메타정보가 최종 인식 성능을 개선시킬 뿐만 아니라, 모델의 시각화 능력을 촉진시킬 수 있음을 보여준다.
<The Visualization of Meta Information>
메타정보를 이해하기 위해 iNaturalist 2021의 여러 종에 대한 spatial prediction을 생성
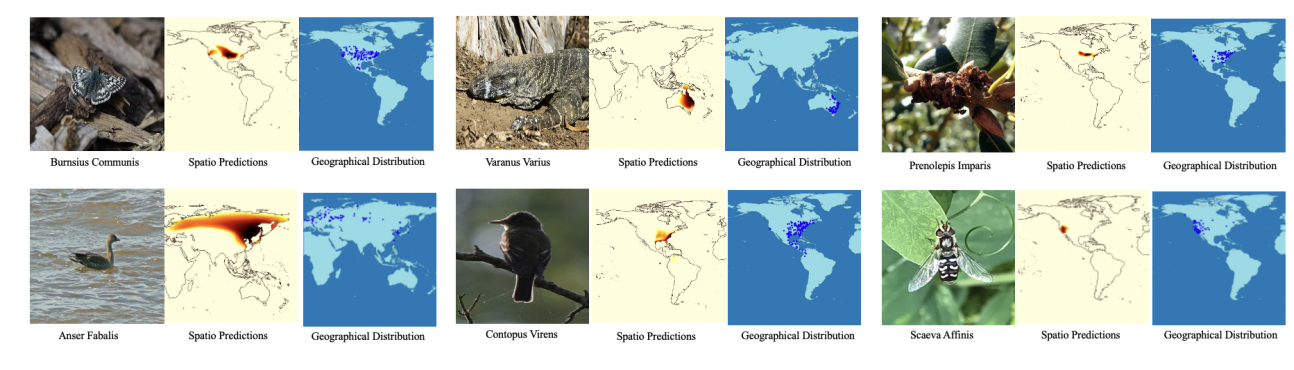
그림 3에서 각 이미지는 지구 표면상의 위치를 쿼리로 허여 관심있는 카테고리의 예측을 수행하여 만들어졌다.
표시된 점은 현재 종의 지리적 분포를 나타낸다.
실제로 $1000\times 2000$의 공간 위치를 평가하고 시각화를 위해 바다에 대한 예측은 mask out한다
시각화로부터 모델이 각 종에 대한 지리적 분포를 학습한다는 것을 보았기 때문에, 이 지리학 분포를 prior로 사용하여 fine-grained 분류를 도울 수 있다.
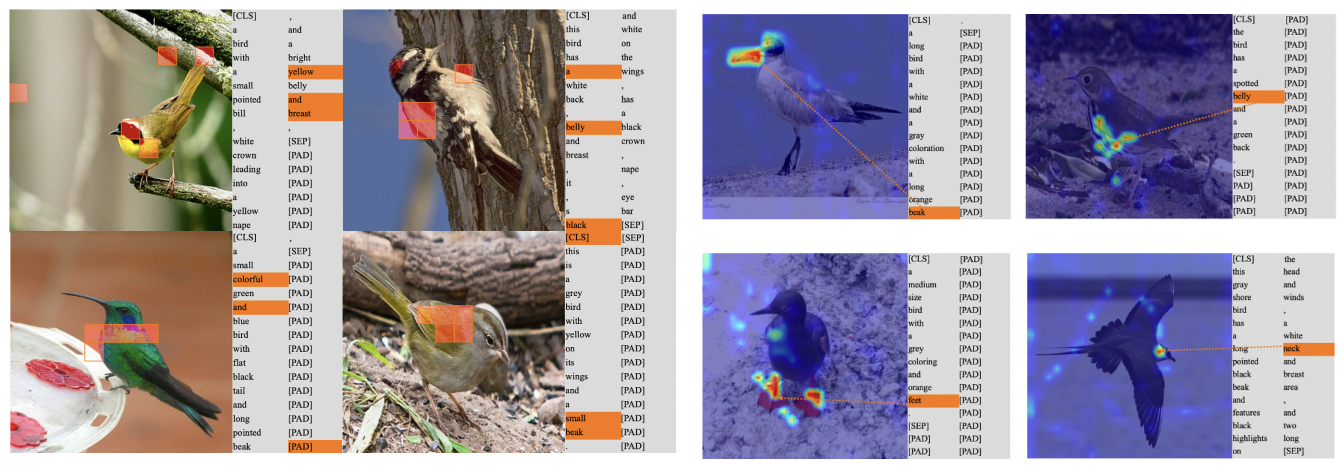
모델이 텍스트 설명을 fine-grained 인식에 사용하는 지를 확인하기 위해, 그림 4에서는 이미지 토큰과 클래스 토큰간의 유사도 top-5와 단어 토큰과 클래스 토큰간의 유사도 top-3를 시각화하였다.
클래스 토큰이 최종적으로 종 카테고리를 예측하는 데 사용된다.
시각화를 보면 클래스 토큰이 종의 속성을 표현하는 토큰들과 높은 유사도를 보임을 확인할 수 있다.
게다가 유사도가 높은 이미지토큰과 단어토큰은 상호보완적인 관계를 갖기도 한다.

그림 5에서는 단어 토큰에 해당하는 이미지 어텐션 맵을 보여준다.
종의 속성을 나타내는 이 단어는 해당되는 이미지 토큰과 높은 유사성을 갖는다.
즉, feet이라고 하면 feet에 해당되는 이미지 토큰과 유사하다는 의미같음
<The Importance of Pre-trained Model>
Fine-grained 분류 작업에서 사전 훈련된 모델이 필수적이긴 하지만 각기 다른 사전훈련 하에서 fine-grained 분류에 대해 베이스라인을 제공한 연구가 없다.
따라서 본 논문에서는 fine-grained 분류에 다양한 사전훈련의 영향을 디테일하게 연구해보고 다양한 데이터셋에 대해 SOTA 성능을 달성하였다.
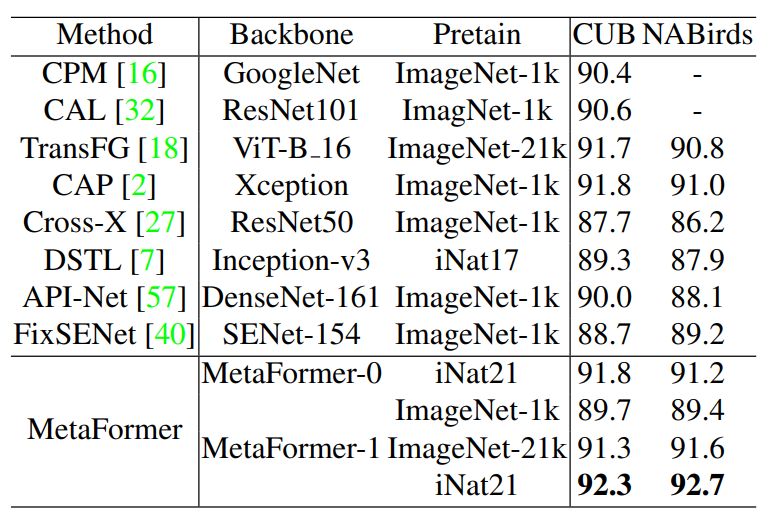
표 6은 CUB-200-2011와 NABirds의 실험 결과이다.
ImageNet-1k에 비해, ImageNet-21k로 사전훈련된 모델을 전이할때, MetaFormer-1의 성능이 CUB-200-2011, NABirds에 대해 각각 2.0%, 2.2% 개선되었다.
정확도는 각각 92.3%, 92.7% (iNautralist2021을 사전훈련에 사용한 기존의 SOTA를 능가함)
iNaturalist2021과 downstream 데이터셋 사이의 도메인 유사성이 높기 때문에 iNaturalist2021의 데이터가 더 적음에도 ImageNet-21k보다 더 나은 성능을 보일 수 있다.
더 적은 파라미터를 가진 MetaFormer-0을 사용하고, iNaturalist에 대해 사전훈련을 거쳤을 때 성능은 91.8%, 91.2%를 얻으면서 SOTA 접근법과 동등한 성능을 얻었다.
기존의 방법들은 복잡한 multi-stage전략이나 multi-branch 구조, 정교한 어텐션 모듈을 설계하였기 때문에 구현하기가 힘들었다.
DSTL은 대용량 데이터셋에서 저용량 데이터셋으로 파인튜닝하는 전이학습을 연구하였으며, 사전훈련에 사용할 데이터를 선택하였다.
본 실험에 따르면 전훈련에 사용되는 데이터의 양이 크고 더 많은 카테고리가 있을 때, 데이터를 선택해서 쓰지 않아도 더 좋은 성능을 얻었다.
하지만 본 연구진은 사전훈련 시 일부러 데이터를 선택하지 않았다.
FixSENet-154는 복잡한 이미지 해상도 전략을 설계하였고, 본 연구진은 과학적인 이미지 해상도 전략을 사용하였다.
ImageNet-21k이 모델을 사전훈련하는 데 사용될 때, 본 연구는 별다른 추가 구조가 없이도 파라미터도 적고 처리량은 높이면서 TransFT와 성능을 유사하게 얻었다.
실험 결과를 통해 fine-grained 인식을 위한 어떠한 inductive bias가 없이도 CUB-200-2011, NABirds 데이터셋에 대해 SOTA 성능을 달성했음을 알 수 있다.
이는 연구자들에게 강력하지만 단순한 베이스라인 모델을 제공한다.
iNaturalilst2017, iNaturalist2018은 fine-grained 인식을 위한 대용량 데이터셋이다

표 7은, MetaFormer-1으로 iNaturalist2017, iNaturalist2018에 대해 SOTA 성능을 얻었음을 보여준다.
iNaturalist 2017, iNaturalist2018에 대한 참고할만한 레퍼런스 성능이 없다.
ImageNet-1k로 사전훈련한 파라미터로 모델을 초기화할 때, FixSENet은 iNaturalist-2017에 대해 75.4.%, Grafit은 iNaturalist 2018에 대해 81.2% 성능을 얻었다.
하지만, 본 실험에서는 ImageNet-1k를 사용해서 모델을 사전훈련 했을 때 정확도가 각각 78.2%, 81.9%가 되어야한다고 함
fine-grained 데이터셋에 대해 MEtaFormer-1로 파인튜닝한 전이학습 성능은 표7에서 확인할 수 있다.
다른 결과들은 별첨에 있음
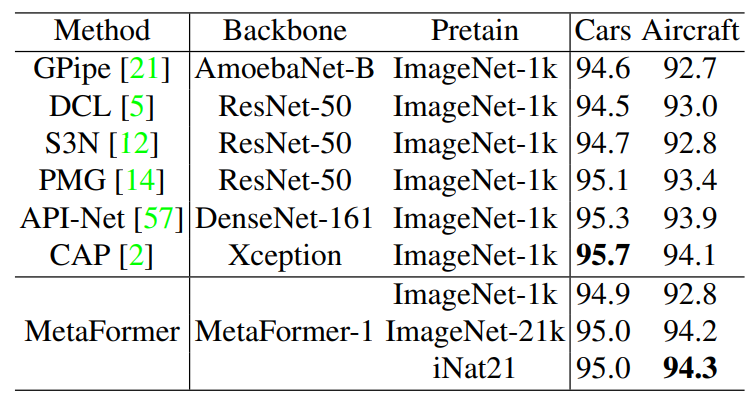
표 8은 Stanford Cars, Aircraft에 대한 본 모델의 실험 결과이다.
Stanford Cars, Aircraft의 경우 이전 방법의 대부분은 ImageNet-1k를 사전 훈련으로 상요하였다.
본 연구진은 MetaFormer-1을 파인튜닝하여 다른 전이학습 성능을 제공한다.
Stanford Cars의 경우, 사전 훈련 모델을 더 강력하게 하여도 더이상의 성능 향상은 없다.
Stanford Cars의 이미지들이 단순하기 때문에 사전 훈련 모델도 엄청난 작업을 요하지 않는다.
Aircraft의 경우, iNaturalist 2021이 ImageNet-21k로 훈련했을 때보다 더 성능이 떨어지는데, 이는 downstream domain에 비해 domain gap이 어마어마하게 차이나기 때문이다.
사전훈련 할 때, 도메인 유사도도 신경써야 될 요소중 하나인가보다..
Conclusion
본 연구에서는 fine-grained 이미지 분류를 위한 통합된 메타 프레임워크를 제안하였다.
MetaFormer는 트랜스포머를 사용하여 이미지 정보와 다양한 메타 정보를 융합한다. 이때, 추가되는 구조는 없다.
또한, MetaFormer는 단순하고 효과적인 베이스라인을 제공한다
게다가 fine-grained 작업에 대한 각기 다른 사전훈련 모델의 영향을 체계적으로 분석하였다.
MetaFormer는 iNaturalist 시리즈, CUB-200-2011, NABirds 데이터셋에 대해 SOTA 성능을 달성하였다.
메타 정보가 fine-grained 인식 작업에서 필수적이라고 여기며 MetaFormer는 다양한 추가정보를 활용할 수 있는 방법을 제공한다.